 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraceVision: Trajectory-Aware Vision-Language Model for Human-Like Spatial Understanding
Feb 24, 2026Recent Large Vision-Language Models (LVLMs) demonstrate remarkable capabilities in image understanding and natural language generation. However, current approaches focus predominantly on global image understanding, struggling to simulate human visual attention trajectories and explain associations between descriptions and specific regions. We propose TraceVision, a unified vision-language model integrating trajectory-aware spatial understanding in an end-to-end framework. TraceVision employs a Trajectory-aware Visual Perception (TVP) module for bidirectional fusion of visual features and trajectory information. We design geometric simplification to extract semantic keypoints from raw trajectories and propose a three-stage training pipeline where trajectories guide description generation and region localization. We extend TraceVision to trajectory-guided segmentation and video scene understanding, enabling cross-frame tracking and temporal attention analysis. We construct the Reasoning-based Interactive Localized Narratives (RILN) dataset to enhance logical reasoning and interpretability. Extensive experiments on trajectory-guided captioning, text-guided trajectory prediction, understanding, and segmentation demonstrate that TraceVision achieves state-of-the-art performance, establishing a foundation for intuitive spatial interaction and interpretable visual understanding.
GeM-VG: Towards Generalized Multi-image Visual Grounding with Multimodal Large Language Models
Jan 08, 2026Multimodal Large Language Models (MLLMs) have demonstrated impressive progress in single-image grounding and general multi-image understanding. Recently, some methods begin to address multi-image grounding. However, they are constrained by single-target localization and limited types of practical tasks, due to the lack of unified modeling for generalized grounding tasks. Therefore, we propose GeM-VG, an MLLM capable of Generalized Multi-image Visual Grounding. To support this, we systematically categorize and organize existing multi-image grounding tasks according to their reliance of cross-image cues and reasoning, and introduce the MG-Data-240K dataset, addressing the limitations of existing datasets regarding target quantity and image relation. To tackle the challenges of robustly handling diverse multi-image grounding tasks, we further propose a hybrid reinforcement finetuning strategy that integrates chain-of-thought (CoT) reasoning and direct answering, considering their complementary strengths. This strategy adopts an R1-like algorithm guided by a carefully designed rule-based reward, effectively enhancing the model's overall perception and reasoning capabilities. Extensive experiments demonstrate the superior generalized grounding capabilities of our model. For multi-image grounding, it outperforms the previous leading MLLMs by 2.0% and 9.7% on MIG-Bench and MC-Bench, respectively. In single-image grounding, it achieves a 9.1% improvement over the base model on ODINW. Furthermore, our model retains strong capabilities in general multi-image understanding.
From Seeing to Predicting: A Vision-Language Framework for Trajectory Forecasting and Controlled Video Generation
Oct 01, 2025
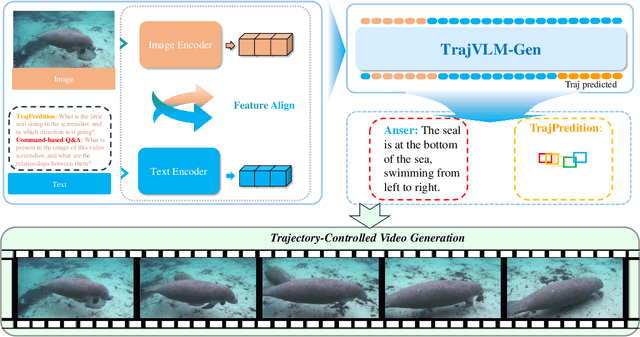


Current video generation models produce physically inconsistent motion that violates real-world dynamics. We propose TrajVLM-Gen, a two-stage framework for physics-aware image-to-video generation. First, we employ a Vision Language Model to predict coarse-grained motion trajectories that maintain consistency with real-world physics. Second, these trajectories guide video generation through attention-based mechanisms for fine-grained motion refinement. We build a trajectory prediction dataset based on video tracking data with realistic motion patterns. Experiments on UCF-101 and MSR-VTT demonstrate that TrajVLM-Gen outperforms existing methods, achieving competitive FVD scores of 545 on UCF-101 and 539 on MSR-VTT.
VFaith: Do Large Multimodal Models Really Reason on Seen Images Rather than Previous Memories?
Jun 13, 2025Recent extensive works have demonstrated that by introducing long CoT, the capabilities of MLLMs to solve complex problems can be effectively enhanced. However, the reasons for the effectiveness of such paradigms remain unclear. It is challenging to analysis with quantitative results how much the model's specific extraction of visual cues and its subsequent so-called reasoning during inference process contribute to the performance improvements. Therefore, evaluating the faithfulness of MLLMs' reasoning to visual information is crucial. To address this issue, we first present a cue-driven automatic and controllable editing pipeline with the help of GPT-Image-1. It enables the automatic and precise editing of specific visual cues based on the instruction. Furthermore, we introduce VFaith-Bench, the first benchmark to evaluate MLLMs' visual reasoning capabilities and analyze the source of such capabilities with an emphasis on the visual faithfulness. Using the designed pipeline, we constructed comparative question-answer pairs by altering the visual cues in images that are crucial for solving the original reasoning problem, thereby changing the question's answer. By testing similar questions with images that have different details, the average accuracy reflects the model's visual reasoning ability, while the difference in accuracy before and after editing the test set images effectively reveals the relationship between the model's reasoning ability and visual perception. We further designed specific metrics to expose this relationship. VFaith-Bench includes 755 entries divided into five distinct subsets, along with an additional human-labeled perception task. We conducted in-depth testing and analysis of existing mainstream flagship models and prominent open-source model series/reasoning models on VFaith-Bench, further investigating the underlying factors of their reasoning capabilities.
Understand, Think, and Answer: Advancing Visual Reasoning with Large Multimodal Models
May 27, 2025Large Multimodal Models (LMMs) have recently demonstrated remarkable visual understanding performance on both vision-language and vision-centric tasks. However, they often fall short in integrating advanced, task-specific capabilities for compositional reasoning, which hinders their progress toward truly competent general vision models. To address this, we present a unified visual reasoning mechanism that enables LMMs to solve complicated compositional problems by leveraging their intrinsic capabilities (e.g. grounding and visual understanding capabilities). Different from the previous shortcut learning mechanism, our approach introduces a human-like understanding-thinking-answering process, allowing the model to complete all steps in a single pass forwarding without the need for multiple inferences or external tools. This design bridges the gap between foundational visual capabilities and general question answering, encouraging LMMs to generate faithful and traceable responses for complex visual reasoning. Meanwhile, we curate 334K visual instruction samples covering both general scenes and text-rich scenes and involving multiple foundational visual capabilities. Our trained model, Griffon-R, has the ability of end-to-end automatic understanding, self-thinking, and reasoning answers. Comprehensive experiments show that Griffon-R not only achieves advancing performance on complex visual reasoning benchmarks including VSR and CLEVR, but also enhances multimodal capabilities across various benchmarks like MMBench and ScienceQA. Data, models, and codes will be release at https://github.com/jefferyZhan/Griffon/tree/master/Griffon-R soon.
Griffon-G: Bridging Vision-Language and Vision-Centric Tasks via Large Multimodal Models
Oct 21, 2024



Large Multimodal Models (LMMs) have achieved significant breakthroughs in various vision-language and vision-centric tasks based on auto-regressive modeling. However, these models typically focus on either vision-centric tasks, such as visual grounding and region description, or vision-language tasks, like image caption and multi-scenario VQAs. None of the LMMs have yet comprehensively unified both types of tasks within a single model, as seen in Large Language Models in the natural language processing field. Furthermore, even with abundant multi-task instruction-following data, directly stacking these data for universal capabilities extension remains challenging. To address these issues, we introduce a novel multi-dimension curated and consolidated multimodal dataset, named CCMD-8M, which overcomes the data barriers of unifying vision-centric and vision-language tasks through multi-level data curation and multi-task consolidation. More importantly, we present Griffon-G, a general large multimodal model that addresses both vision-centric and vision-language tasks within a single end-to-end paradigm. Griffon-G resolves the training collapse issue encountered during the joint optimization of these tasks, achieving better training efficiency. Evaluations across multimodal benchmarks, general Visual Question Answering (VQA) tasks, scene text-centric VQA tasks, document-related VQA tasks, Referring Expression Comprehension, and object detection demonstrate that Griffon-G surpasses the advanced LMMs and achieves expert-level performance in complicated vision-centric tasks.
Griffon v2: Advancing Multimodal Perception with High-Resolution Scaling and Visual-Language Co-Referring
Mar 14, 2024



Large Vision Language Models have achieved fine-grained object perception, but the limitation of image resolution remains a significant obstacle to surpass the performance of task-specific experts in complex and dense scenarios. Such limitation further restricts the model's potential to achieve nuanced visual and language referring in domains such as GUI Agents, Counting and \etc. To address this issue, we introduce a unified high-resolution generalist model, Griffon v2, enabling flexible object referring with visual and textual prompts. To efficiently scaling up image resolution, we design a simple and lightweight down-sampling projector to overcome the input tokens constraint in Large Language Models. This design inherently preserves the complete contexts and fine details, and significantly improves multimodal perception ability especially for small objects. Building upon this, we further equip the model with visual-language co-referring capabilities through a plug-and-play visual tokenizer. It enables user-friendly interaction with flexible target images, free-form texts and even coordinates. Experiments demonstrate that Griffon v2 can localize any objects of interest with visual and textual referring, achieve state-of-the-art performance on REC, phrase grounding, and REG tasks, and outperform expert models in object detection and object counting. Data, codes and models will be released at https://github.com/jefferyZhan/Griffon.
Griffon: Spelling out All Object Locations at Any Granularity with Large Language Models
Nov 27, 2023



Replicating the innate human ability to detect all objects based on free-form texts at any granularity remains a formidable challenge for Vision-Language models. Current Large Vision Language Models (LVLMs) are predominantly constrained to grounding a single, pre-existing object, relying solely on data from Referring Expression Comprehension tasks. The limitation leads to a compromise in model design, necessitating the introduction of visual expert models or the integration of customized head structures. Beyond these constraints, our research delves into the untapped potential of LVLMs and uncover their inherent capability for basic object perception, allowing them to accurately identify and locate objects of interest. Building on this insight, we introduce a novel language-prompted localization dataset designed to fully unleash the capabilities of LVLMs in integrating fine-grained object perception with precise location awareness. More importantly, we present $\textbf{Griffon}$, a purely LVLM-based baseline, which does not require the introduction of any special tokens, expert models, or additional detection modules. It simply maintains a consistent structure with popular LVLMs by unifying data formats across various localization-related scenarios and is trained end-to-end through a well-designed pipeline. Comprehensive experiments demonstrate that $\textbf{Griffon}$ not only achieves state-of-the-art performance on the fine-grained RefCOCO series but also approaches the capabilities of the expert model Faster RCNN on the detection benchmark MSCOCO.
Mitigating Hallucination in Visual Language Models with Visual Supervision
Nov 27, 2023



Large vision-language models (LVLMs) suffer from hallucination a lot, generating responses that apparently contradict to the image content occasionally. The key problem lies in its weak ability to comprehend detailed content in a multi-modal context, which can be mainly attributed to two factors in training data and loss function. The vision instruction dataset primarily focuses on global description, and the auto-regressive loss function favors text modeling rather than image understanding. In this paper, we bring more detailed vision annotations and more discriminative vision models to facilitate the training of LVLMs, so that they can generate more precise responses without encounter hallucination. On one hand, we generate image-text pairs with detailed relationship annotations in panoptic scene graph dataset (PSG). These conversations pay more attention on detailed facts in the image, encouraging the model to answer questions based on multi-modal contexts. On the other hand, we integrate SAM and mask prediction loss as auxiliary supervision, forcing the LVLMs to have the capacity to identify context-related objects, so that they can generate more accurate responses, mitigating hallucination. Moreover, to provide a deeper evaluation on the hallucination in LVLMs, we propose a new benchmark, RAH-Bench. It divides vision hallucination into three different types that contradicts the image with wrong categories, attributes or relations, and introduces False Positive Rate as detailed sub-metric for each type. In this benchmark, our approach demonstrates an +8.4% enhancement compared to original LLaVA and achieves widespread performance improvements across other models.
Efficient Masked Autoencoders with Self-Consistency
Feb 28, 2023



Inspired by masked language modeling (MLM) in natural language processing, masked image modeling (MIM) has been recognized as a strong and popular self-supervised pre-training method in computer vision. However, its high random mask ratio would result in two serious problems: 1) the data are not efficiently exploited, which brings inefficient pre-training (\eg, 1600 epochs for MAE $vs.$ 300 epochs for the supervised), and 2) the high uncertainty and inconsistency of the pre-trained model, \ie, the prediction of the same patch may be inconsistent under different mask rounds. To tackle these problems, we propose efficient masked autoencoders with self-consistency (EMAE), to improve the pre-training efficiency and increase the consistency of MIM. In particular, we progressively divide the image into K non-overlapping parts, each of which is generated by a random mask and has the same mask ratio. Then the MIM task is conducted parallelly on all parts in an iteration and generates predictions. Besides, we design a self-consistency module to further maintain the consistency of predictions of overlapping masked patches among parts. Overall, the proposed method is able to exploit the data more efficiently and obtains reliable representations. Experiments on ImageNet show that EMAE achieves even higher results with only 300 pre-training epochs under ViT-Base than MAE (1600 epochs). EMAE also consistently obtains state-of-the-art transfer performance on various downstream tasks, like object detection, and semantic segmentation.