 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOutcome-Grounded Advantage Reshaping for Fine-Grained Credit Assignment in Mathematical Reasoning
Jan 12, 2026Group Relative Policy Optimization (GRPO) has emerged as a promising critic-free reinforcement learning paradigm for reasoning tasks. However, standard GRPO employs a coarse-grained credit assignment mechanism that propagates group-level rewards uniformly to to every token in a sequence, neglecting the varying contribution of individual reasoning steps. We address this limitation by introducing Outcome-grounded Advantage Reshaping (OAR), a fine-grained credit assignment mechanism that redistributes advantages based on how much each token influences the model's final answer. We instantiate OAR via two complementary strategies: (1) OAR-P, which estimates outcome sensitivity through counterfactual token perturbations, serving as a high-fidelity attribution signal; (2) OAR-G, which uses an input-gradient sensitivity proxy to approximate the influence signal with a single backward pass. These importance signals are integrated with a conservative Bi-Level advantage reshaping scheme that suppresses low-impact tokens and boosts pivotal ones while preserving the overall advantage mass. Empirical results on extensive mathematical reasoning benchmarks demonstrate that while OAR-P sets the performance upper bound, OAR-G achieves comparable gains with negligible computational overhead, both significantly outperforming a strong GRPO baseline, pushing the boundaries of critic-free LLM reasoning.
IRPO: Scaling the Bradley-Terry Model via Reinforcement Learning
Jan 02, 2026Generative Reward Models (GRMs) have attracted considerable research interest in reward modeling due to their interpretability, inference-time scalability, and potential for refinement through reinforcement learning (RL). However, widely used pairwise GRMs create a computational bottleneck when integrated with RL algorithms such as Group Relative Policy Optimization (GRPO). This bottleneck arises from two factors: (i) the O(n^2) time complexity of pairwise comparisons required to obtain relative scores, and (ii) the computational overhead of repeated sampling or additional chain-of-thought (CoT) reasoning to improve performance. To address the first factor, we propose Intergroup Relative Preference Optimization (IRPO), a novel RL framework that incorporates the well-established Bradley-Terry model into GRPO. By generating a pointwise score for each response, IRPO enables efficient evaluation of arbitrarily many candidates during RL training while preserving interpretability and fine-grained reward signals. Experimental results demonstrate that IRPO achieves state-of-the-art (SOTA) performance among pointwise GRMs across multiple benchmarks, with performance comparable to that of current leading pairwise GRMs. Furthermore, we show that IRPO significantly outperforms pairwise GRMs in post-training evaluations.
Psychology-guided Controllable Story Generation
Oct 14, 2022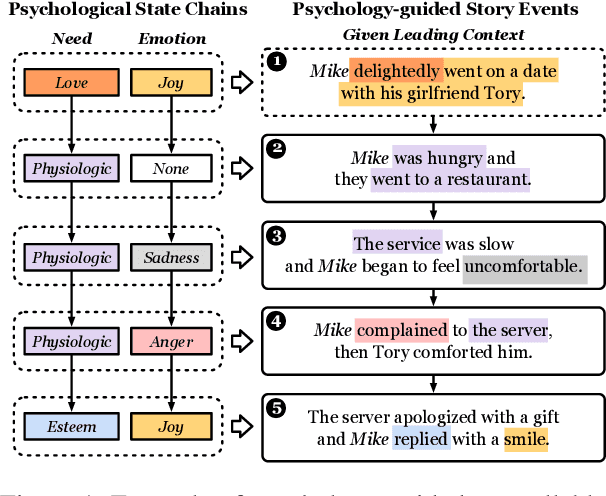

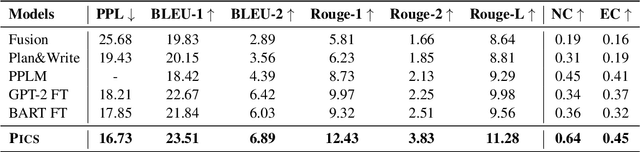
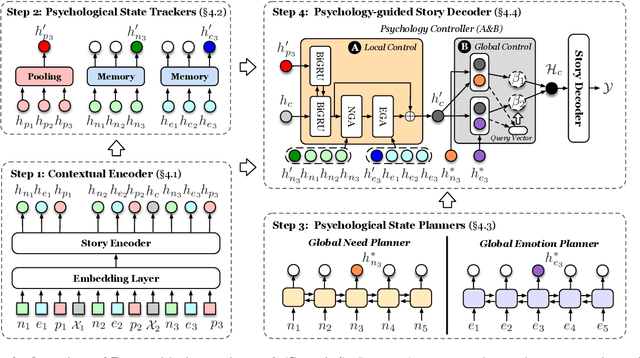
Controllable story generation is a challenging task in the field of NLP, which has attracted increasing research interest in recent years. However, most existing works generate a whole story conditioned on the appointed keywords or emotions, ignoring the psychological changes of the protagonist. Inspired by psychology theories, we introduce global psychological state chains, which include the needs and emotions of the protagonists, to help a story generation system create more controllable and well-planned stories. In this paper, we propose a Psychology-guIded Controllable Story Generation System (PICS) to generate stories that adhere to the given leading context and desired psychological state chains for the protagonist. Specifically, psychological state trackers are employed to memorize the protagonist's local psychological states to capture their inner temporal relationships. In addition, psychological state planners are adopted to gain the protagonist's global psychological states for story planning. Eventually, a psychology controller is designed to integrate the local and global psychological states into the story context representation for composing psychology-guided stories. Automatic and manual evaluations demonstrate that PICS outperforms baselines, and each part of PICS shows effectiveness for writing stories with more consistent psychological changes.
COMMA: Modeling Relationship among Motivations, Emotions and Actions in Language-based Human Activities
Sep 14, 2022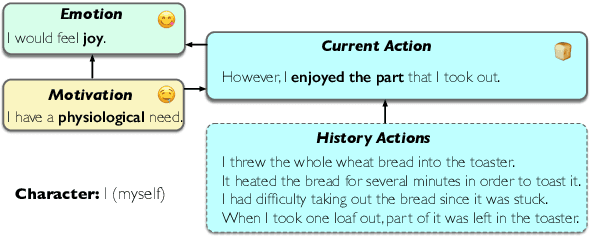

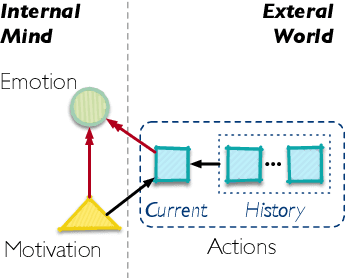
Motivations, emotions, and actions are inter-related essential factors in human activities. While motivations and emotions have long been considered at the core of exploring how people take actions in human activities, there has been relatively little research supporting analyzing the relationship between human mental states and actions. We present the first study that investigates the viability of modeling motivations, emotions, and actions in language-based human activities, named COMMA (Cognitive Framework of Human Activities). Guided by COMMA, we define three natural language processing tasks (emotion understanding, motivation understanding and conditioned action generation), and build a challenging dataset Hail through automatically extracting samples from Story Commonsense. Experimental results on NLP applications prove the effectiveness of modeling the relationship. Furthermore, our models inspired by COMMA can better reveal the essential relationship among motivations, emotions and actions than existing methods.
Do You Know My Emotion? Emotion-Aware Strategy Recognition towards a Persuasive Dialogue System
Jun 24, 2022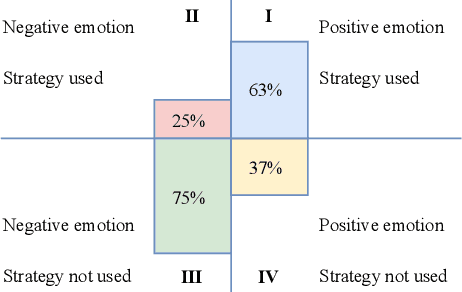
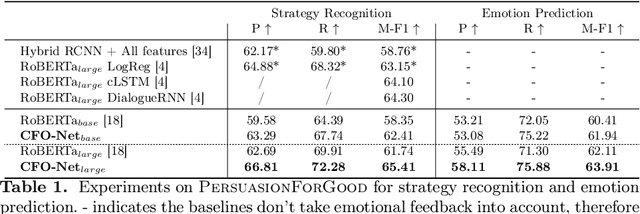
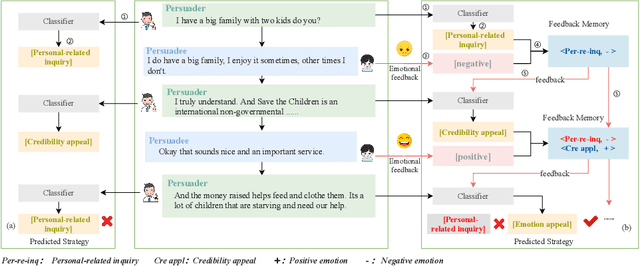

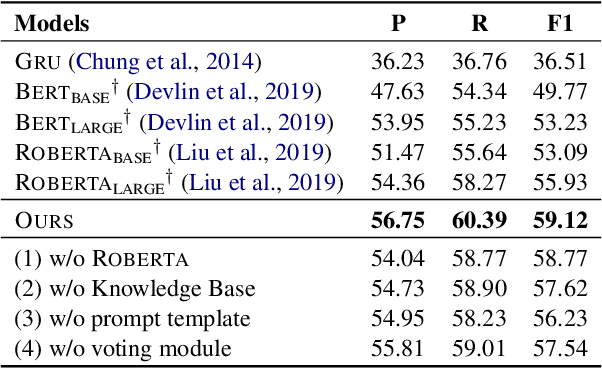
Persuasive strategy recognition task requires the system to recognize the adopted strategy of the persuader according to the conversation. However, previous methods mainly focus on the contextual information, little is known about incorporating the psychological feedback, i.e. emotion of the persuadee, to predict the strategy. In this paper, we propose a Cross-channel Feedback memOry Network (CFO-Net) to leverage the emotional feedback to iteratively measure the potential benefits of strategies and incorporate them into the contextual-aware dialogue information. Specifically, CFO-Net designs a feedback memory module, including strategy pool and feedback pool, to obtain emotion-aware strategy representation. The strategy pool aims to store historical strategies and the feedback pool is to obtain updated strategy weight based on feedback emotional information. Furthermore, a cross-channel fusion predictor is developed to make a mutual interaction between the emotion-aware strategy representation and the contextual-aware dialogue information for strategy recognition. Experimental results on \textsc{PersuasionForGood} confirm that the proposed model CFO-Net is effective to improve the performance on M-F1 from 61.74 to 65.41.
CogIntAc: Modeling the Relationships between Intention, Emotion and Action in Interactive Process from Cognitive Perspective
May 16, 2022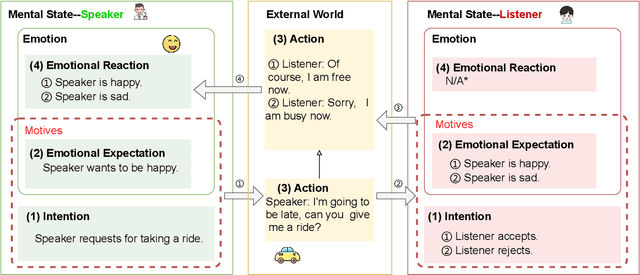
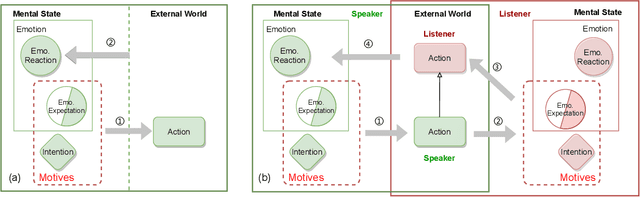
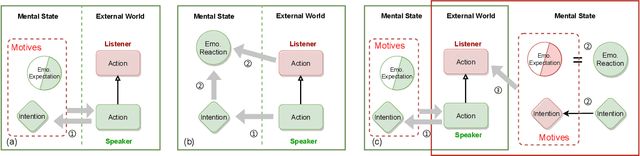
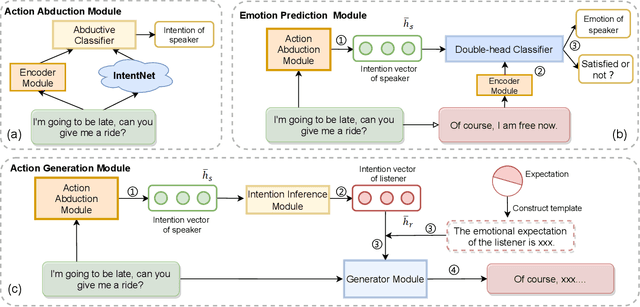
Intention, emotion and action are important psychological factors in human activities, which play an important role in the interaction between individuals. How to model the interaction process between individuals by analyzing the relationship of their intentions, emotions, and actions at the cognitive level is challenging. In this paper, we propose a novel cognitive framework of individual interaction. The core of the framework is that individuals achieve interaction through external action driven by their inner intention. Based on this idea, the interactions between individuals can be constructed by establishing relationships between the intention, emotion and action. Furthermore, we conduct analysis on the interaction between individuals and give a reasonable explanation for the predicting results. To verify the effectiveness of the framework, we reconstruct a dataset and propose three tasks as well as the corresponding baseline models, including action abduction, emotion prediction and action generation. The novel framework shows an interesting perspective on mimicking the mental state of human beings in cognitive science.
Control Globally, Understand Locally: A Global-to-Local Hierarchical Graph Network for Emotional Support Conversation
Apr 27, 2022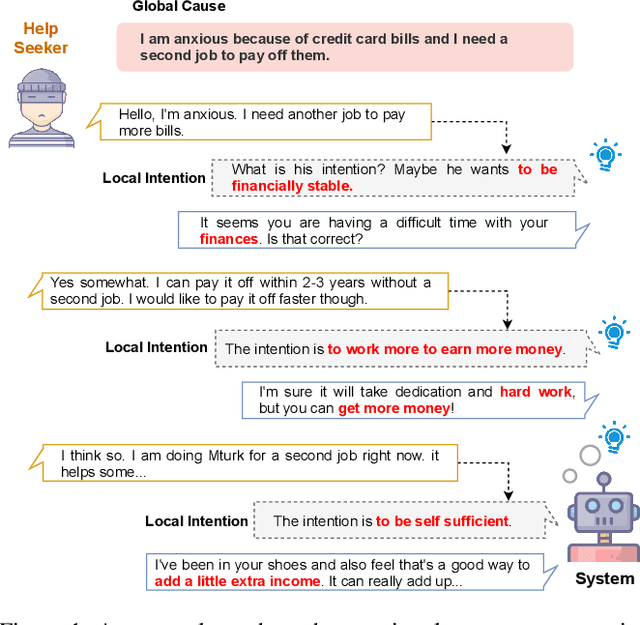
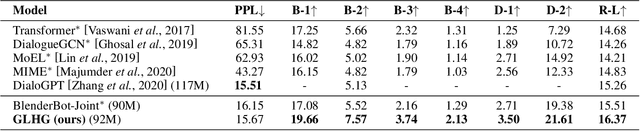
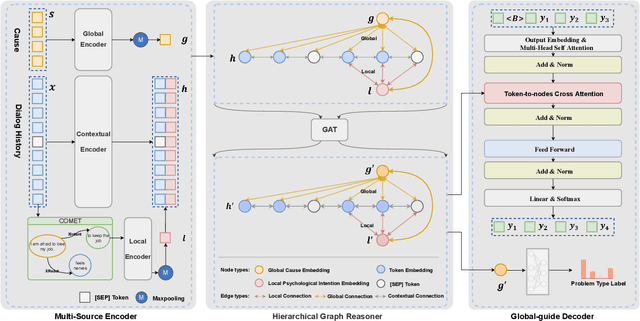
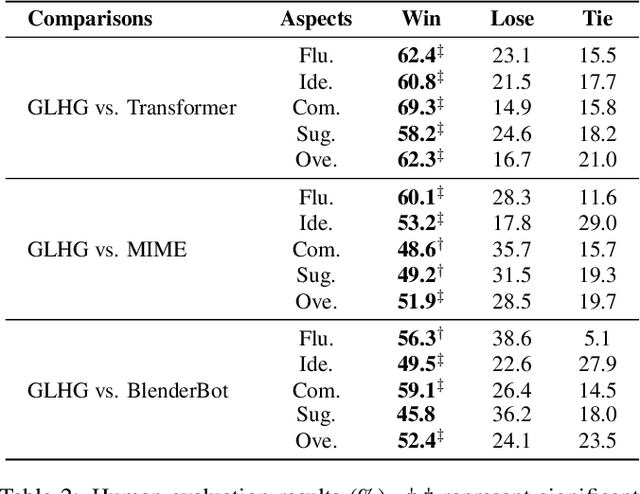
Emotional support conversation aims at reducing the emotional distress of the help-seeker, which is a new and challenging task. It requires the system to explore the cause of help-seeker's emotional distress and understand their psychological intention to provide supportive responses. However, existing methods mainly focus on the sequential contextual information, ignoring the hierarchical relationships with the global cause and local psychological intention behind conversations, thus leads to a weak ability of emotional support. In this paper, we propose a Global-to-Local Hierarchical Graph Network to capture the multi-source information (global cause, local intentions and dialog history) and model hierarchical relationships between them, which consists of a multi-source encoder, a hierarchical graph reasoner, and a global-guide decoder. Furthermore, a novel training objective is designed to monitor semantic information of the global cause. Experimental results on the emotional support conversation dataset, ESConv, confirm that the proposed GLHG has achieved the state-of-the-art performance on the automatic and human evaluations.
Multi-CPR: A Multi Domain Chinese Dataset for Passage Retrieval
Mar 07, 2022
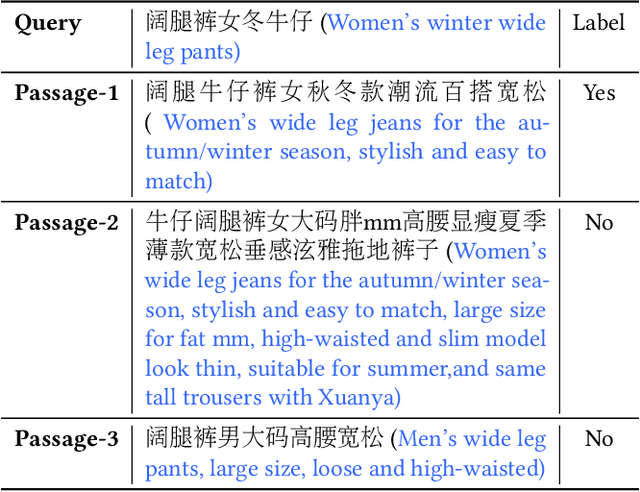
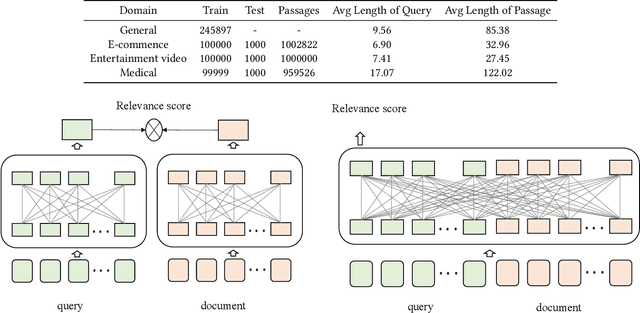
Passage retrieval is a fundamental task in information retrieval (IR) research, which has drawn much attention recently. In English field, the availability of large-scale annotated dataset (e.g, MS MARCO) and the emergence of deep pre-trained language models (e.g, BERT) have resulted in a substantial improvement of existing passage retrieval systems. However, in Chinese field, especially for specific domain, passage retrieval systems are still immature due to quality-annotated dataset being limited by scale. Therefore, in this paper, we present a novel multi-domain Chinese dataset for passage retrieval (Multi-CPR). The dataset is collected from three different domains, including E-commerce, Entertainment video and Medical. Each dataset contains millions of passages and a certain amount of human annotated query-passage related pairs. We implement various representative passage retrieval methods as baselines. We find that the performance of retrieval models trained on dataset from general domain will inevitably decrease on specific domain. Nevertheless, passage retrieval system built on in-domain annotated dataset can achieve significant improvement, which indeed demonstrates the necessity of domain labeled data for further optimization. We hope the release of the Multi-CPR dataset could benchmark Chinese passage retrieval task in specific domain and also make advances for future studies.
CLSEG: Contrastive Learning of Story Ending Generation
Feb 18, 2022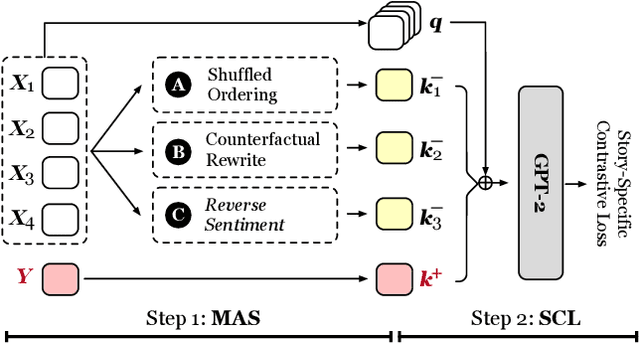

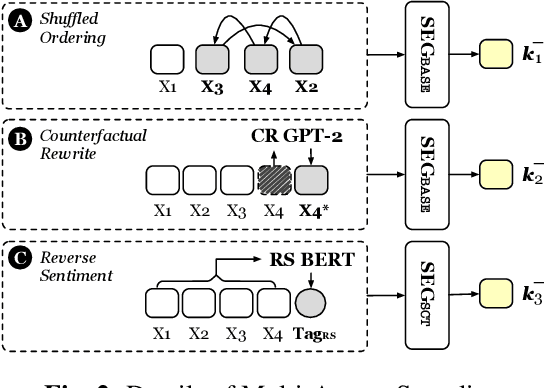
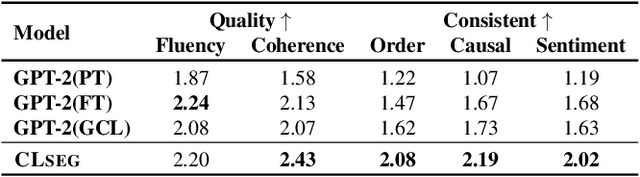
Story Ending Generation (SEG) is a challenging task in natural language generation. Recently, methods based on Pre-trained Language Models (PLM) have achieved great prosperity, which can produce fluent and coherent story endings. However, the pre-training objective of PLM-based methods is unable to model the consistency between story context and ending. The goal of this paper is to adopt contrastive learning to generate endings more consistent with story context, while there are two main challenges in contrastive learning of SEG. First is the negative sampling of wrong endings inconsistent with story contexts. The second challenge is the adaptation of contrastive learning for SEG. To address these two issues, we propose a novel Contrastive Learning framework for Story Ending Generation (CLSEG), which has two steps: multi-aspect sampling and story-specific contrastive learning. Particularly, for the first issue, we utilize novel multi-aspect sampling mechanisms to obtain wrong endings considering the consistency of order, causality, and sentiment. To solve the second issue, we well-design a story-specific contrastive training strategy that is adapted for SEG. Experiments show that CLSEG outperforms baselines and can produce story endings with stronger consistency and rationality.
Modeling Intention, Emotion and External World in Dialogue Systems
Feb 14, 2022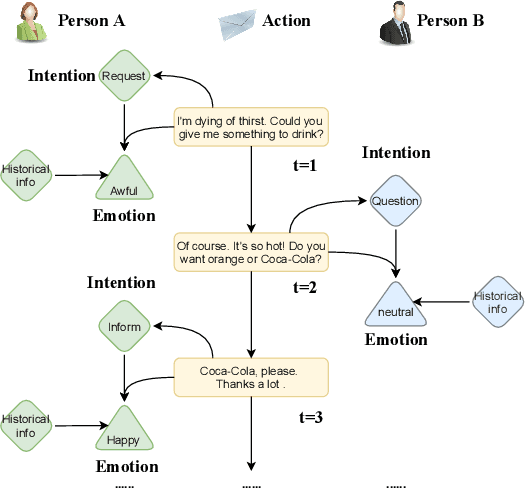
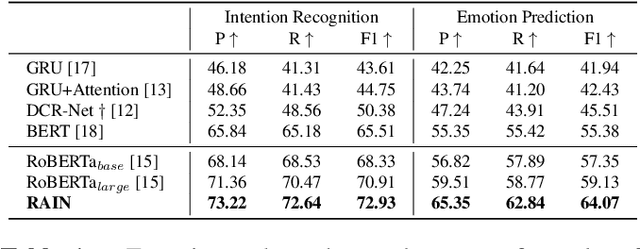
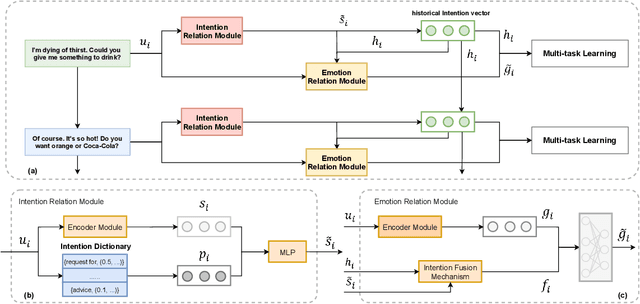
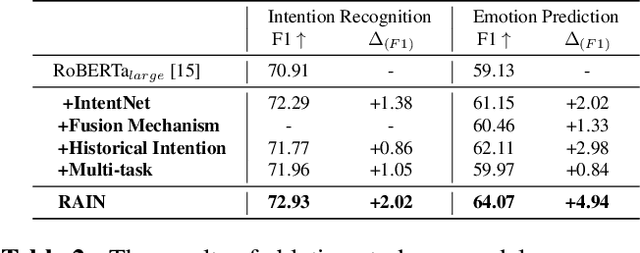
Intention, emotion and action are important elements in human activities. Modeling the interaction process between individuals by analyzing the relationships between these elements is a challenging task. However, previous work mainly focused on modeling intention and emotion independently, and neglected of exploring the mutual relationships between intention and emotion. In this paper, we propose a RelAtion Interaction Network (RAIN), consisting of Intention Relation Module and Emotion Relation Module, to jointly model mutual relationships and explicitly integrate historical intention information. The experiments on the dataset show that our model can take full advantage of the intention, emotion and action between individuals and achieve a remarkable improvement over BERT-style baselines. Qualitative analysis verifies the importance of the mutual interaction between the intention and emotion.