 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKunlun: Establishing Scaling Laws for Massive-Scale Recommendation Systems through Unified Architecture Design
Feb 13, 2026Deriving predictable scaling laws that govern the relationship between model performance and computational investment is crucial for designing and allocating resources in massive-scale recommendation systems. While such laws are established for large language models, they remain challenging for recommendation systems, especially those processing both user history and context features. We identify poor scaling efficiency as the main barrier to predictable power-law scaling, stemming from inefficient modules with low Model FLOPs Utilization (MFU) and suboptimal resource allocation. We introduce Kunlun, a scalable architecture that systematically improves model efficiency and resource allocation. Our low-level optimizations include Generalized Dot-Product Attention (GDPA), Hierarchical Seed Pooling (HSP), and Sliding Window Attention. Our high-level innovations feature Computation Skip (CompSkip) and Event-level Personalization. These advances increase MFU from 17% to 37% on NVIDIA B200 GPUs and double scaling efficiency over state-of-the-art methods. Kunlun is now deployed in major Meta Ads models, delivering significant production impact.
Meta Lattice: Model Space Redesign for Cost-Effective Industry-Scale Ads Recommendations
Dec 15, 2025The rapidly evolving landscape of products, surfaces, policies, and regulations poses significant challenges for deploying state-of-the-art recommendation models at industry scale, primarily due to data fragmentation across domains and escalating infrastructure costs that hinder sustained quality improvements. To address this challenge, we propose Lattice, a recommendation framework centered around model space redesign that extends Multi-Domain, Multi-Objective (MDMO) learning beyond models and learning objectives. Lattice addresses these challenges through a comprehensive model space redesign that combines cross-domain knowledge sharing, data consolidation, model unification, distillation, and system optimizations to achieve significant improvements in both quality and cost-efficiency. Our deployment of Lattice at Meta has resulted in 10% revenue-driving top-line metrics gain, 11.5% user satisfaction improvement, 6% boost in conversion rate, with 20% capacity saving.
External Large Foundation Model: How to Efficiently Serve Trillions of Parameters for Online Ads Recommendation
Feb 26, 2025



Ads recommendation is a prominent service of online advertising systems and has been actively studied. Recent studies indicate that scaling-up and advanced design of the recommendation model can bring significant performance improvement. However, with a larger model scale, such prior studies have a significantly increasing gap from industry as they often neglect two fundamental challenges in industrial-scale applications. First, training and inference budgets are restricted for the model to be served, exceeding which may incur latency and impair user experience. Second, large-volume data arrive in a streaming mode with data distributions dynamically shifting, as new users/ads join and existing users/ads leave the system. We propose the External Large Foundation Model (ExFM) framework to address the overlooked challenges. Specifically, we develop external distillation and a data augmentation system (DAS) to control the computational cost of training/inference while maintaining high performance. We design the teacher in a way like a foundation model (FM) that can serve multiple students as vertical models (VMs) to amortize its building cost. We propose Auxiliary Head and Student Adapter to mitigate the data distribution gap between FM and VMs caused by the streaming data issue. Comprehensive experiments on internal industrial-scale applications and public datasets demonstrate significant performance gain by ExFM.
A Collaborative Ensemble Framework for CTR Prediction
Nov 20, 2024



Recent advances in foundation models have established scaling laws that enable the development of larger models to achieve enhanced performance, motivating extensive research into large-scale recommendation models. However, simply increasing the model size in recommendation systems, even with large amounts of data, does not always result in the expected performance improvements. In this paper, we propose a novel framework, Collaborative Ensemble Training Network (CETNet), to leverage multiple distinct models, each with its own embedding table, to capture unique feature interaction patterns. Unlike naive model scaling, our approach emphasizes diversity and collaboration through collaborative learning, where models iteratively refine their predictions. To dynamically balance contributions from each model, we introduce a confidence-based fusion mechanism using general softmax, where model confidence is computed via negation entropy. This design ensures that more confident models have a greater influence on the final prediction while benefiting from the complementary strengths of other models. We validate our framework on three public datasets (AmazonElectronics, TaobaoAds, and KuaiVideo) as well as a large-scale industrial dataset from Meta, demonstrating its superior performance over individual models and state-of-the-art baselines. Additionally, we conduct further experiments on the Criteo and Avazu datasets to compare our method with the multi-embedding paradigm. Our results show that our framework achieves comparable or better performance with smaller embedding sizes, offering a scalable and efficient solution for CTR prediction tasks.
InterFormer: Towards Effective Heterogeneous Interaction Learning for Click-Through Rate Prediction
Nov 15, 2024



Click-through rate (CTR) prediction, which predicts the probability of a user clicking an ad, is a fundamental task in recommender systems. The emergence of heterogeneous information, such as user profile and behavior sequences, depicts user interests from different aspects. A mutually beneficial integration of heterogeneous information is the cornerstone towards the success of CTR prediction. However, most of the existing methods suffer from two fundamental limitations, including (1) insufficient inter-mode interaction due to the unidirectional information flow between modes, and (2) aggressive information aggregation caused by early summarization, resulting in excessive information loss. To address the above limitations, we propose a novel module named InterFormer to learn heterogeneous information interaction in an interleaving style. To achieve better interaction learning, InterFormer enables bidirectional information flow for mutually beneficial learning across different modes. To avoid aggressive information aggregation, we retain complete information in each data mode and use a separate bridging arch for effective information selection and summarization. Our proposed InterFormer achieves state-of-the-art performance on three public datasets and a large-scale industrial dataset.
Lightweight Compositional Embeddings for Incremental Streaming Recommendation
Feb 04, 2022



Most work in graph-based recommender systems considers a {\em static} setting where all information about test nodes (i.e., users and items) is available upfront at training time. However, this static setting makes little sense for many real-world applications where data comes in continuously as a stream of new edges and nodes, and one has to update model predictions incrementally to reflect the latest state. To fully capitalize on the newly available data in the stream, recent graph-based recommendation models would need to be repeatedly retrained, which is infeasible in practice. In this paper, we study the graph-based streaming recommendation setting and propose a compositional recommendation model -- Lightweight Compositional Embedding (LCE) -- that supports incremental updates under low computational cost. Instead of learning explicit embeddings for the full set of nodes, LCE learns explicit embeddings for only a subset of nodes and represents the other nodes {\em implicitly}, through a composition function based on their interactions in the graph. This provides an effective, yet efficient, means to leverage streaming graph data when one node type (e.g., items) is more amenable to static representation. We conduct an extensive empirical study to compare LCE to a set of competitive baselines on three large-scale user-item recommendation datasets with interactions under a streaming setting. The results demonstrate the superior performance of LCE, showing that it achieves nearly skyline performance with significantly fewer parameters than alternative graph-based models.
A Collective Learning Framework to Boost GNN Expressiveness
Mar 26, 2020
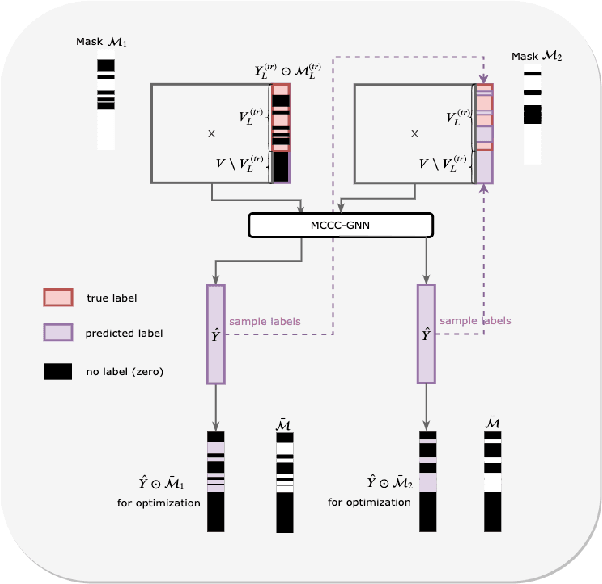
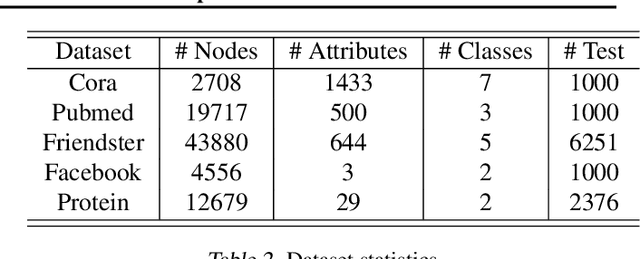
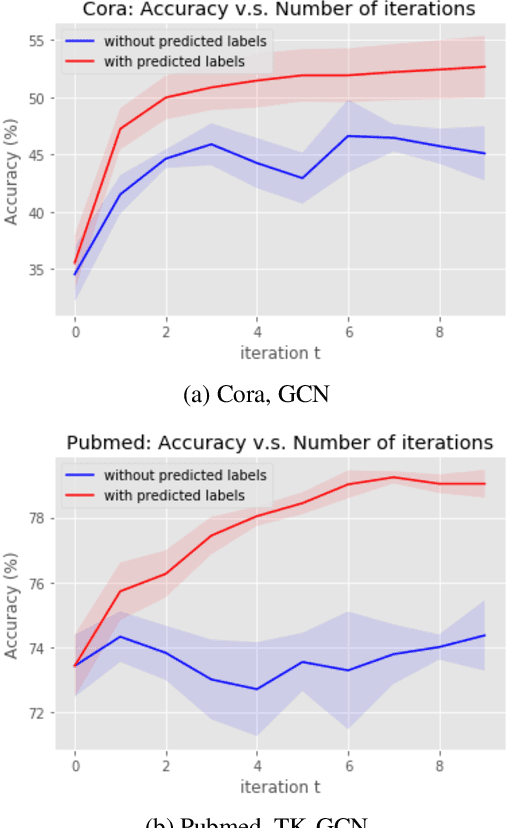
Graph Neural Networks (GNNs) have recently been used for node and graph classification tasks with great success, but GNNs model dependencies among the attributes of nearby neighboring nodes rather than dependencies among observed node labels. In this work, we consider the task of inductive node classification using GNNs in supervised and semi-supervised settings, with the goal of incorporating label dependencies. Because current GNNs are not universal (i.e., most-expressive) graph representations, we propose a general collective learning approach to increase the representation power of any existing GNN. Our framework combines ideas from collective classification with self-supervised learning, and uses a Monte Carlo approach to sampling embeddings for inductive learning across graphs. We evaluate performance on five real-world network datasets and demonstrate consistent, significant improvement in node classification accuracy, for a variety of state-of-the-art GNNs.