 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenOneRec Technical Report
Dec 31, 2025While the OneRec series has successfully unified the fragmented recommendation pipeline into an end-to-end generative framework, a significant gap remains between recommendation systems and general intelligence. Constrained by isolated data, they operate as domain specialists-proficient in pattern matching but lacking world knowledge, reasoning capabilities, and instruction following. This limitation is further compounded by the lack of a holistic benchmark to evaluate such integrated capabilities. To address this, our contributions are: 1) RecIF Bench & Open Data: We propose RecIF-Bench, a holistic benchmark covering 8 diverse tasks that thoroughly evaluate capabilities from fundamental prediction to complex reasoning. Concurrently, we release a massive training dataset comprising 96 million interactions from 160,000 users to facilitate reproducible research. 2) Framework & Scaling: To ensure full reproducibility, we open-source our comprehensive training pipeline, encompassing data processing, co-pretraining, and post-training. Leveraging this framework, we demonstrate that recommendation capabilities can scale predictably while mitigating catastrophic forgetting of general knowledge. 3) OneRec-Foundation: We release OneRec Foundation (1.7B and 8B), a family of models establishing new state-of-the-art (SOTA) results across all tasks in RecIF-Bench. Furthermore, when transferred to the Amazon benchmark, our models surpass the strongest baselines with an average 26.8% improvement in Recall@10 across 10 diverse datasets (Figure 1). This work marks a step towards building truly intelligent recommender systems. Nonetheless, realizing this vision presents significant technical and theoretical challenges, highlighting the need for broader research engagement in this promising direction.
SemanticNN: Compressive and Error-Resilient Semantic Offloading for Extremely Weak Devices
Nov 14, 2025With the rapid growth of the Internet of Things (IoT), integrating artificial intelligence (AI) on extremely weak embedded devices has garnered significant attention, enabling improved real-time performance and enhanced data privacy. However, the resource limitations of such devices and unreliable network conditions necessitate error-resilient device-edge collaboration systems. Traditional approaches focus on bit-level transmission correctness, which can be inefficient under dynamic channel conditions. In contrast, we propose SemanticNN, a semantic codec that tolerates bit-level errors in pursuit of semantic-level correctness, enabling compressive and resilient collaborative inference offloading under strict computational and communication constraints. It incorporates a Bit Error Rate (BER)-aware decoder that adapts to dynamic channel conditions and a Soft Quantization (SQ)-based encoder to learn compact representations. Building on this architecture, we introduce Feature-augmentation Learning, a novel training strategy that enhances offloading efficiency. To address encoder-decoder capability mismatches from asymmetric resources, we propose XAI-based Asymmetry Compensation to enhance decoding semantic fidelity. We conduct extensive experiments on STM32 using three models and six datasets across image classification and object detection tasks. Experimental results demonstrate that, under varying transmission error rates, SemanticNN significantly reduces feature transmission volume by 56.82-344.83x while maintaining superior inference accuracy.
OneRec-V2 Technical Report
Aug 28, 2025



Recent breakthroughs in generative AI have transformed recommender systems through end-to-end generation. OneRec reformulates recommendation as an autoregressive generation task, achieving high Model FLOPs Utilization. While OneRec-V1 has shown significant empirical success in real-world deployment, two critical challenges hinder its scalability and performance: (1) inefficient computational allocation where 97.66% of resources are consumed by sequence encoding rather than generation, and (2) limitations in reinforcement learning relying solely on reward models. To address these challenges, we propose OneRec-V2, featuring: (1) Lazy Decoder-Only Architecture: Eliminates encoder bottlenecks, reducing total computation by 94% and training resources by 90%, enabling successful scaling to 8B parameters. (2) Preference Alignment with Real-World User Interactions: Incorporates Duration-Aware Reward Shaping and Adaptive Ratio Clipping to better align with user preferences using real-world feedback. Extensive A/B tests on Kuaishou demonstrate OneRec-V2's effectiveness, improving App Stay Time by 0.467%/0.741% while balancing multi-objective recommendations. This work advances generative recommendation scalability and alignment with real-world feedback, representing a step forward in the development of end-to-end recommender systems.
Klear-Reasoner: Advancing Reasoning Capability via Gradient-Preserving Clipping Policy Optimization
Aug 12, 2025



We present Klear-Reasoner, a model with long reasoning capabilities that demonstrates careful deliberation during problem solving, achieving outstanding performance across multiple benchmarks. Although there are already many excellent works related to inference models in the current community, there are still many problems with reproducing high-performance inference models due to incomplete disclosure of training details. This report provides an in-depth analysis of the reasoning model, covering the entire post-training workflow from data preparation and long Chain-of-Thought supervised fine-tuning (long CoT SFT) to reinforcement learning (RL), along with detailed ablation studies for each experimental component. For SFT data, our experiments show that a small number of high-quality data sources are more effective than a large number of diverse data sources, and that difficult samples can achieve better results without accuracy filtering. In addition, we investigate two key issues with current clipping mechanisms in RL: Clipping suppresses critical exploration signals and ignores suboptimal trajectories. To address these challenges, we propose Gradient-Preserving clipping Policy Optimization (GPPO) that gently backpropagates gradients from clipped tokens. GPPO not only enhances the model's exploration capacity but also improves its efficiency in learning from negative samples. Klear-Reasoner exhibits exceptional reasoning abilities in mathematics and programming, scoring 90.5% on AIME 2024, 83.2% on AIME 2025, 66.0% on LiveCodeBench V5 and 58.1% on LiveCodeBench V6.
Kwai Keye-VL Technical Report
Jul 02, 2025While Multimodal Large Language Models (MLLMs) demonstrate remarkable capabilities on static images, they often fall short in comprehending dynamic, information-dense short-form videos, a dominant medium in today's digital landscape. To bridge this gap, we introduce \textbf{Kwai Keye-VL}, an 8-billion-parameter multimodal foundation model engineered for leading-edge performance in short-video understanding while maintaining robust general-purpose vision-language abilities. The development of Keye-VL rests on two core pillars: a massive, high-quality dataset exceeding 600 billion tokens with a strong emphasis on video, and an innovative training recipe. This recipe features a four-stage pre-training process for solid vision-language alignment, followed by a meticulous two-phase post-training process. The first post-training stage enhances foundational capabilities like instruction following, while the second phase focuses on stimulating advanced reasoning. In this second phase, a key innovation is our five-mode ``cold-start'' data mixture, which includes ``thinking'', ``non-thinking'', ``auto-think'', ``think with image'', and high-quality video data. This mixture teaches the model to decide when and how to reason. Subsequent reinforcement learning (RL) and alignment steps further enhance these reasoning capabilities and correct abnormal model behaviors, such as repetitive outputs. To validate our approach, we conduct extensive evaluations, showing that Keye-VL achieves state-of-the-art results on public video benchmarks and remains highly competitive on general image-based tasks (Figure 1). Furthermore, we develop and release the \textbf{KC-MMBench}, a new benchmark tailored for real-world short-video scenarios, where Keye-VL shows a significant advantage.
OneRec Technical Report
Jun 16, 2025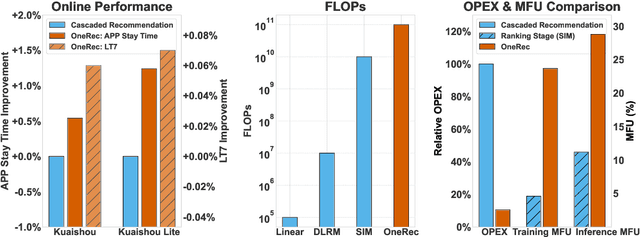

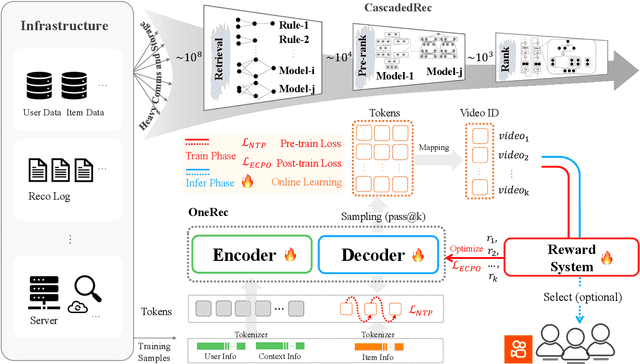
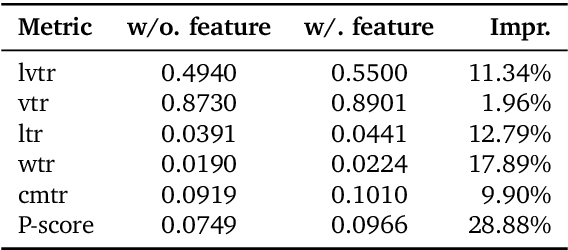
Recommender systems have been widely used in various large-scale user-oriented platforms for many years. However, compared to the rapid developments in the AI community, recommendation systems have not achieved a breakthrough in recent years. For instance, they still rely on a multi-stage cascaded architecture rather than an end-to-end approach, leading to computational fragmentation and optimization inconsistencies, and hindering the effective application of key breakthrough technologies from the AI community in recommendation scenarios. To address these issues, we propose OneRec, which reshapes the recommendation system through an end-to-end generative approach and achieves promising results. Firstly, we have enhanced the computational FLOPs of the current recommendation model by 10 $\times$ and have identified the scaling laws for recommendations within certain boundaries. Secondly, reinforcement learning techniques, previously difficult to apply for optimizing recommendations, show significant potential in this framework. Lastly, through infrastructure optimizations, we have achieved 23.7% and 28.8% Model FLOPs Utilization (MFU) on flagship GPUs during training and inference, respectively, aligning closely with the LLM community. This architecture significantly reduces communication and storage overhead, resulting in operating expense that is only 10.6% of traditional recommendation pipelines. Deployed in Kuaishou/Kuaishou Lite APP, it handles 25% of total queries per second, enhancing overall App Stay Time by 0.54% and 1.24%, respectively. Additionally, we have observed significant increases in metrics such as 7-day Lifetime, which is a crucial indicator of recommendation experience. We also provide practical lessons and insights derived from developing, optimizing, and maintaining a production-scale recommendation system with significant real-world impact.
E-Tree Learning: A Novel Decentralized Model Learning Framework for Edge AI
Aug 04, 2020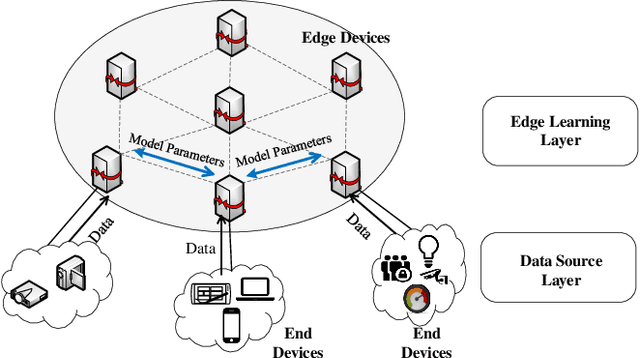

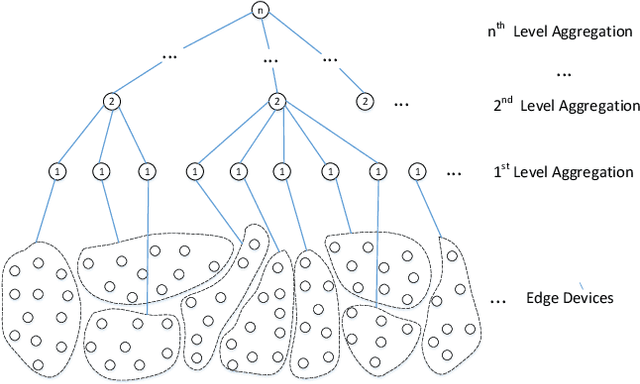
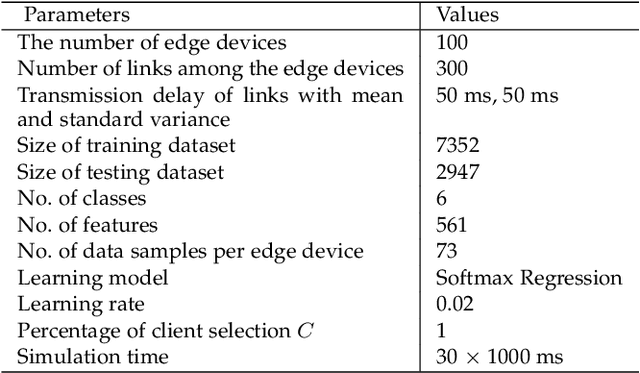
Traditionally, AI models are trained on the central cloud with data collected from end devices. This leads to high communication cost, long response time and privacy concerns. Recently Edge empowered AI, namely Edge AI, has been proposed to support AI model learning and deployment at the network edge closer to the data sources. Existing research including federated learning adopts a centralized architecture for model learning where a central server aggregates the model updates from the clients/workers. The centralized architecture has drawbacks such as performance bottleneck, poor scalability and single point of failure. In this paper, we propose a novel decentralized model learning approach, namely E-Tree, which makes use of a well-designed tree structure imposed on the edge devices. The tree structure and the locations and orders of aggregation on the tree are optimally designed to improve the training convergency and model accuracy. In particular, we design an efficient device clustering algorithm, named by KMA, for E-Tree by taking into account the data distribution on the devices as well as the the network distance. Evaluation results show E-Tree significantly outperforms the benchmark approaches such as federated learning and Gossip learning under NonIID data in terms of model accuracy and convergency.