 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIRPO: Scaling the Bradley-Terry Model via Reinforcement Learning
Jan 02, 2026Generative Reward Models (GRMs) have attracted considerable research interest in reward modeling due to their interpretability, inference-time scalability, and potential for refinement through reinforcement learning (RL). However, widely used pairwise GRMs create a computational bottleneck when integrated with RL algorithms such as Group Relative Policy Optimization (GRPO). This bottleneck arises from two factors: (i) the O(n^2) time complexity of pairwise comparisons required to obtain relative scores, and (ii) the computational overhead of repeated sampling or additional chain-of-thought (CoT) reasoning to improve performance. To address the first factor, we propose Intergroup Relative Preference Optimization (IRPO), a novel RL framework that incorporates the well-established Bradley-Terry model into GRPO. By generating a pointwise score for each response, IRPO enables efficient evaluation of arbitrarily many candidates during RL training while preserving interpretability and fine-grained reward signals. Experimental results demonstrate that IRPO achieves state-of-the-art (SOTA) performance among pointwise GRMs across multiple benchmarks, with performance comparable to that of current leading pairwise GRMs. Furthermore, we show that IRPO significantly outperforms pairwise GRMs in post-training evaluations.
From Anchor Generation to Distribution Alignment: Learning a Discriminative Embedding Space for Zero-Shot Recognition
Feb 10, 2020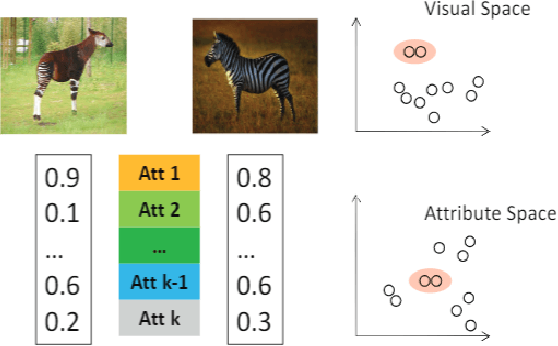
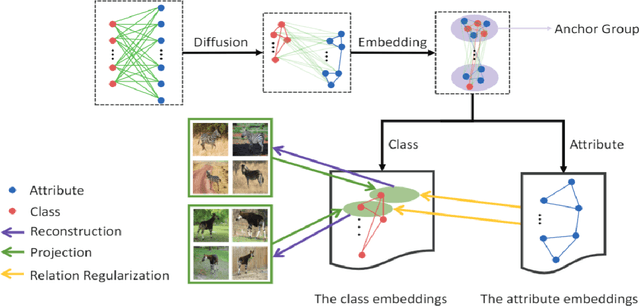
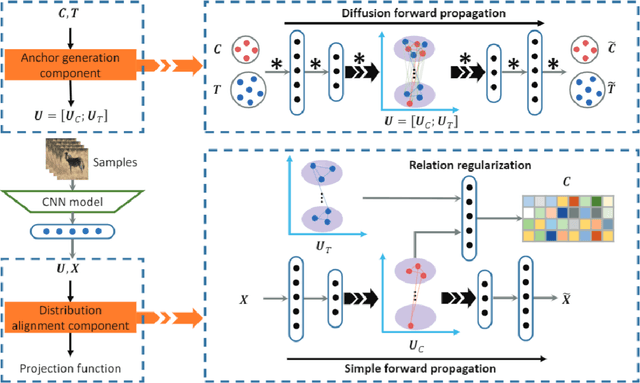

In zero-shot learning (ZSL), the samples to be classified are usually projected into side information templates such as attributes. However, the irregular distribution of templates makes classification results confused. To alleviate this issue, we propose a novel framework called Discriminative Anchor Generation and Distribution Alignment Model (DAGDA). Firstly, in order to rectify the distribution of original templates, a diffusion based graph convolutional network, which can explicitly model the interaction between class and side information, is proposed to produce discriminative anchors. Secondly, to further align the samples with the corresponding anchors in anchor space, which aims to refine the distribution in a fine-grained manner, we introduce a semantic relation regularization in anchor space. Following the way of inductive learning, our approach outperforms some existing state-of-the-art methods, on several benchmark datasets, for both conventional as well as generalized ZSL setting. Meanwhile, the ablation experiments strongly demonstrate the effectiveness of each component.