 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Dual-Student with Differentiable Spatial Warping for Semi-Supervised Semantic Segmentation
Mar 05, 2022
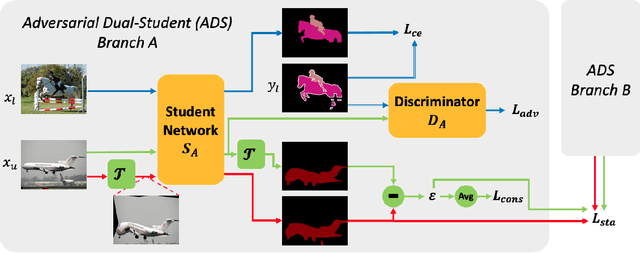
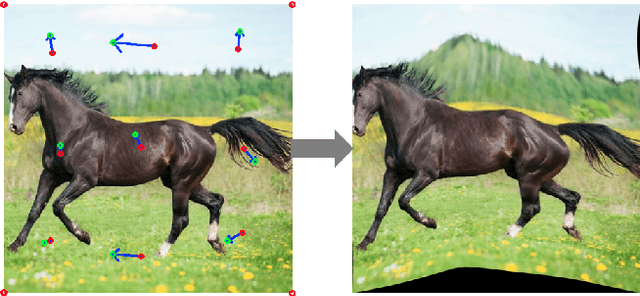

A common challenge posed to robust semantic segmentation is the expensive data annotation cost. Existing semi-supervised solutions show great potential toward solving this problem. Their key idea is constructing consistency regularization with unsupervised data augmentation from unlabeled data for model training. The perturbations for unlabeled data enable the consistency training loss, which benefits semi-supervised semantic segmentation. However, these perturbations destroy image context and introduce unnatural boundaries, which is harmful for semantic segmentation. Besides, the widely adopted semi-supervised learning framework, i.e. mean-teacher, suffers performance limitation since the student model finally converges to the teacher model. In this paper, first of all, we propose a context friendly differentiable geometric warping to conduct unsupervised data augmentation; secondly, a novel adversarial dual-student framework is proposed to improve the Mean-Teacher from the following two aspects: (1) dual student models are learnt independently except for a stabilization constraint to encourage exploiting model diversities; (2) adversarial training scheme is applied to both students and the discriminators are resorted to distinguish reliable pseudo-label of unlabeled data for self-training. Effectiveness is validated via extensive experiments on PASCAL VOC2012 and Citescapes. Our solution significantly improves the performance and state-of-the-art results are achieved on both datasets. Remarkably, compared with fully supervision, our solution achieves comparable mIoU of 73.4% using only 12.5% annotated data on PASCAL VOC2012.
MobileFaceSwap: A Lightweight Framework for Video Face Swapping
Jan 11, 2022
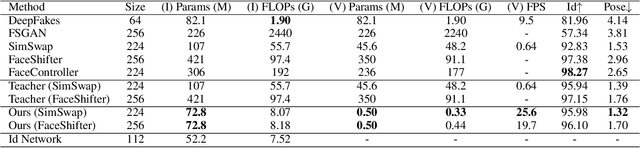
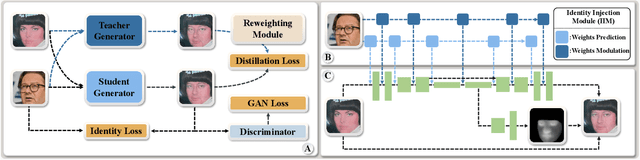
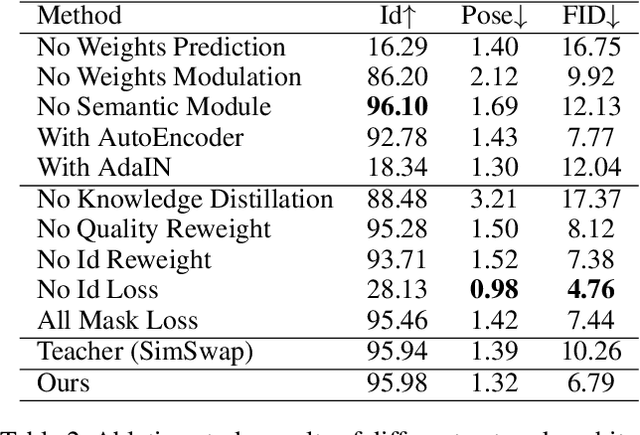
Advanced face swapping methods have achieved appealing results. However, most of these methods have many parameters and computations, which makes it challenging to apply them in real-time applications or deploy them on edge devices like mobile phones. In this work, we propose a lightweight Identity-aware Dynamic Network (IDN) for subject-agnostic face swapping by dynamically adjusting the model parameters according to the identity information. In particular, we design an efficient Identity Injection Module (IIM) by introducing two dynamic neural network techniques, including the weights prediction and weights modulation. Once the IDN is updated, it can be applied to swap faces given any target image or video. The presented IDN contains only 0.50M parameters and needs 0.33G FLOPs per frame, making it capable for real-time video face swapping on mobile phones. In addition, we introduce a knowledge distillation-based method for stable training, and a loss reweighting module is employed to obtain better synthesized results. Finally, our method achieves comparable results with the teacher models and other state-of-the-art methods.
The Devil is in the Task: Exploiting Reciprocal Appearance-Localization Features for Monocular 3D Object Detection
Dec 28, 2021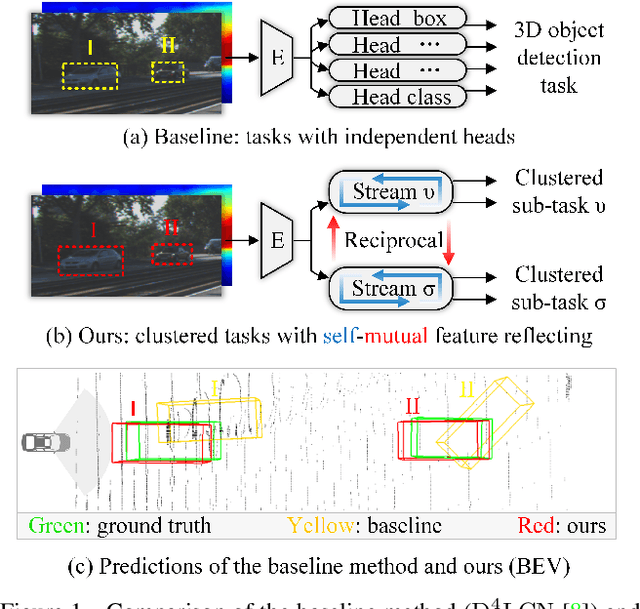
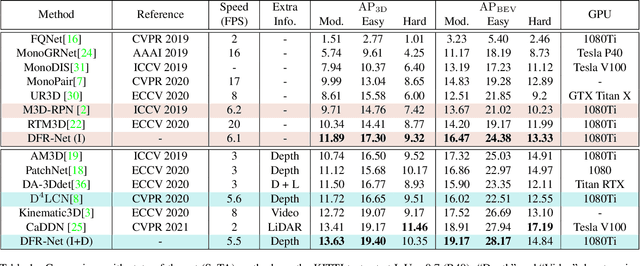
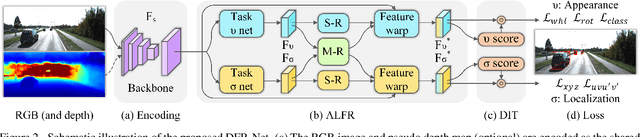
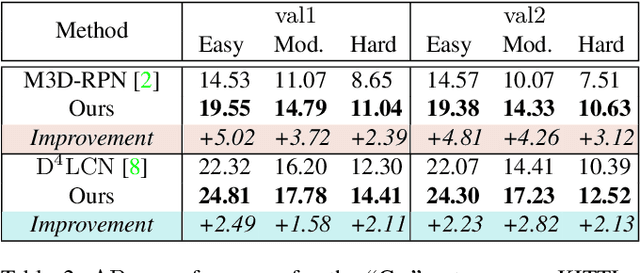
Low-cost monocular 3D object detection plays a fundamental role in autonomous driving, whereas its accuracy is still far from satisfactory. In this paper, we dig into the 3D object detection task and reformulate it as the sub-tasks of object localization and appearance perception, which benefits to a deep excavation of reciprocal information underlying the entire task. We introduce a Dynamic Feature Reflecting Network, named DFR-Net, which contains two novel standalone modules: (i) the Appearance-Localization Feature Reflecting module (ALFR) that first separates taskspecific features and then self-mutually reflects the reciprocal features; (ii) the Dynamic Intra-Trading module (DIT) that adaptively realigns the training processes of various sub-tasks via a self-learning manner. Extensive experiments on the challenging KITTI dataset demonstrate the effectiveness and generalization of DFR-Net. We rank 1st among all the monocular 3D object detectors in the KITTI test set (till March 16th, 2021). The proposed method is also easy to be plug-and-play in many cutting-edge 3D detection frameworks at negligible cost to boost performance. The code will be made publicly available.
SGM3D: Stereo Guided Monocular 3D Object Detection
Dec 03, 2021
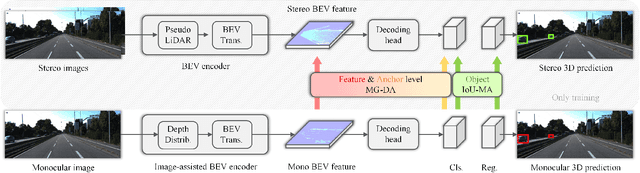
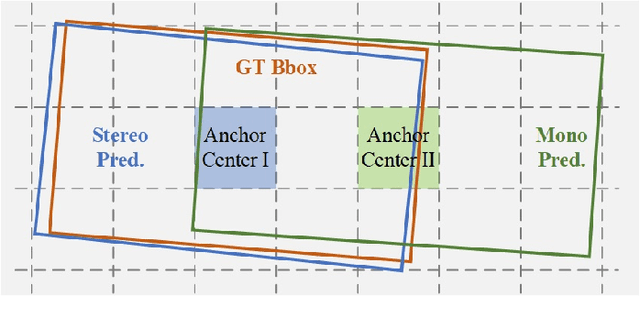

Monocular 3D object detection is a critical yet challenging task for autonomous driving, due to the lack of accurate depth information captured by LiDAR sensors. In this paper, we propose a stereo-guided monocular 3D object detection network, termed SGM3D, which leverages robust 3D features extracted from stereo images to enhance the features learned from the monocular image. We innovatively investigate a multi-granularity domain adaptation module (MG-DA) to exploit the network's ability so as to generate stereo-mimic features only based on the monocular cues. The coarse BEV feature-level, as well as the fine anchor-level domain adaptation, are leveraged to guide the monocular branch. We present an IoU matching-based alignment module (IoU-MA) for object-level domain adaptation between the stereo and monocular predictions to alleviate the mismatches in previous stages. We conduct extensive experiments on the most challenging KITTI and Lyft datasets and achieve new state-of-the-art performance. Furthermore, our method can be integrated into many other monocular approaches to boost performance without introducing any extra computational cost.
Predict, Prevent, and Evaluate: Disentangled Text-Driven Image Manipulation Empowered by Pre-Trained Vision-Language Model
Nov 26, 2021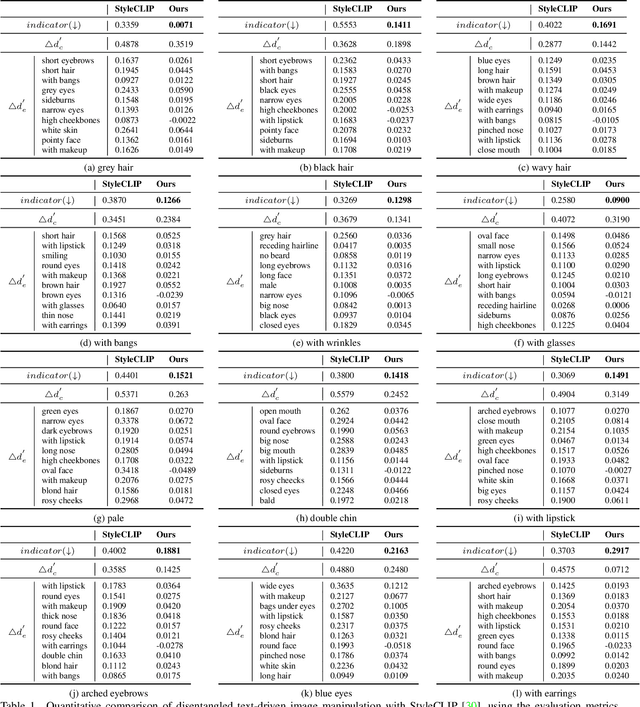
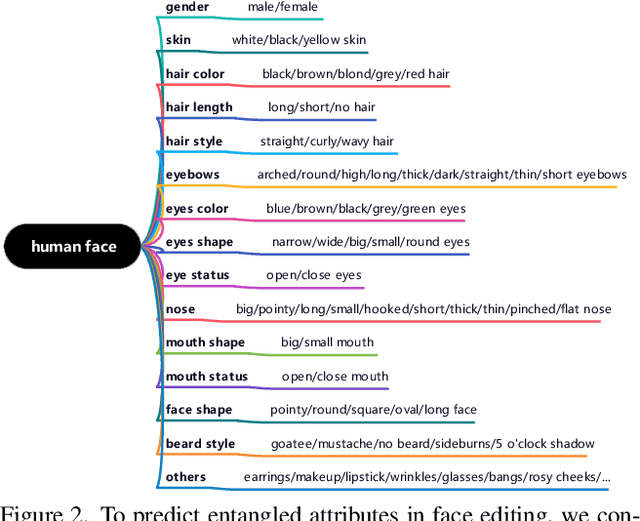
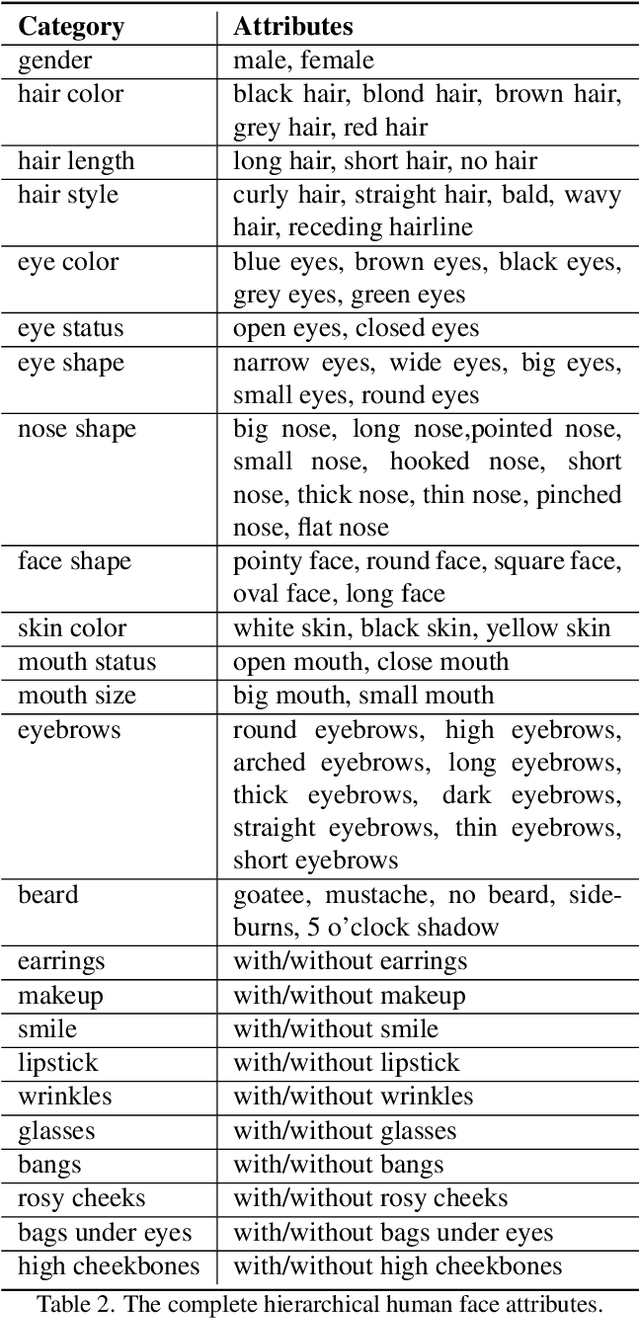

To achieve disentangled image manipulation, previous works depend heavily on manual annotation. Meanwhile, the available manipulations are limited to a pre-defined set the models were trained for. In this paper, we propose a novel framework, i.e., Predict, Prevent, and Evaluate (PPE), for disentangled text-driven image manipulation, which does not need manual annotation and thus is not limited to fixed manipulations. Our method approaches the targets by deeply exploiting the power of the large scale pre-trained vision-language model CLIP. Concretely, we firstly Predict the possibly entangled attributes for a given text command. Then, based on the predicted attributes, we introduce an entanglement loss to Prevent entanglements during training. Finally, we propose a new evaluation metric to Evaluate the disentangled image manipulation. We verify the effectiveness of our method on the challenging face editing task. Extensive experiments show that the proposed PPE framework achieves much better quantitative and qualitative results than the up-to-date StyleCLIP baseline.
An Information Theory-inspired Strategy for Automatic Network Pruning
Aug 19, 2021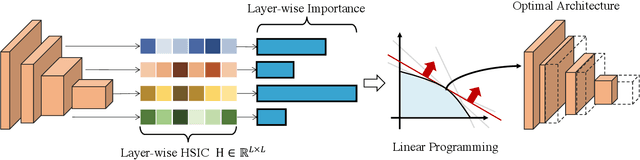
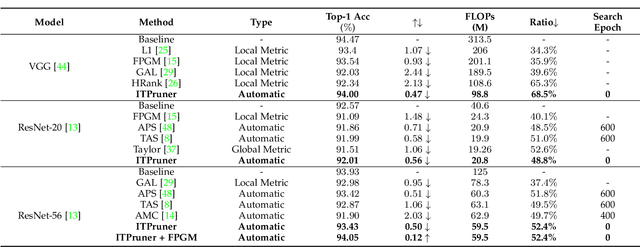

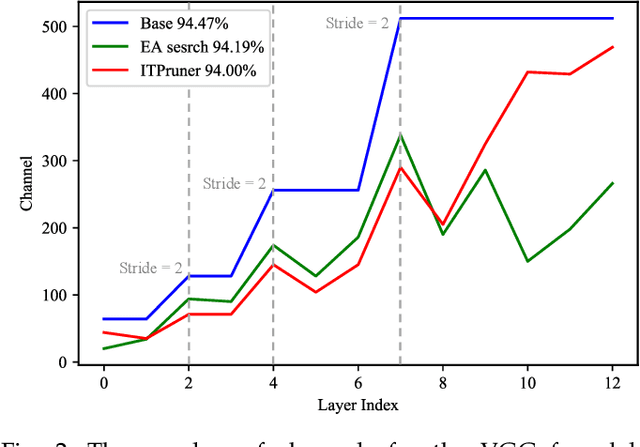
Despite superior performance on many computer vision tasks, deep convolution neural networks are well known to be compressed on devices that have resource constraints. Most existing network pruning methods require laborious human efforts and prohibitive computation resources, especially when the constraints are changed. This practically limits the application of model compression when the model needs to be deployed on a wide range of devices. Besides, existing methods are still challenged by the missing theoretical guidance. In this paper we propose an information theory-inspired strategy for automatic model compression. The principle behind our method is the information bottleneck theory, i.e., the hidden representation should compress information with each other. We thus introduce the normalized Hilbert-Schmidt Independence Criterion (nHSIC) on network activations as a stable and generalized indicator of layer importance. When a certain resource constraint is given, we integrate the HSIC indicator with the constraint to transform the architecture search problem into a linear programming problem with quadratic constraints. Such a problem is easily solved by a convex optimization method with a few seconds. We also provide a rigorous proof to reveal that optimizing the normalized HSIC simultaneously minimizes the mutual information between different layers. Without any search process, our method achieves better compression tradeoffs comparing to the state-of-the-art compression algorithms. For instance, with ResNet-50, we achieve a 45.3%-FLOPs reduction, with a 75.75 top-1 accuracy on ImageNet. Codes are avaliable at https://github.com/MAC-AutoML/ITPruner/tree/master.
DOLG: Single-Stage Image Retrieval with Deep Orthogonal Fusion of Local and Global Features
Aug 11, 2021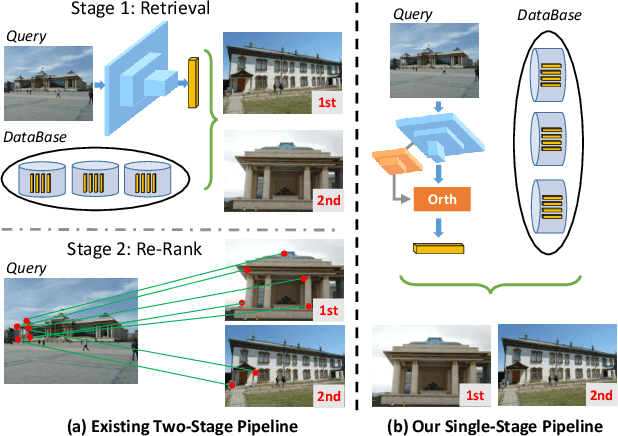
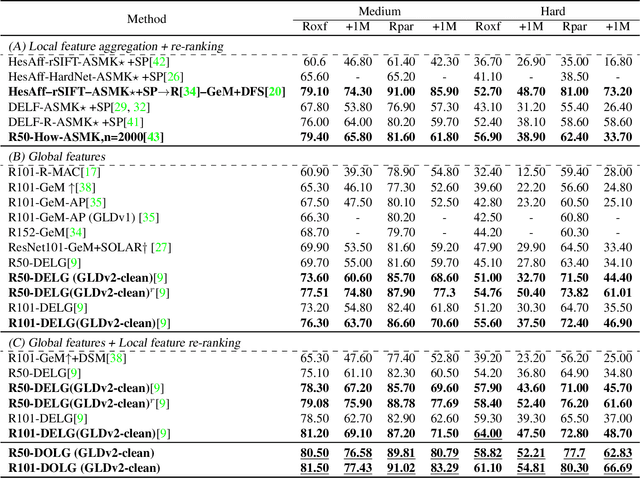
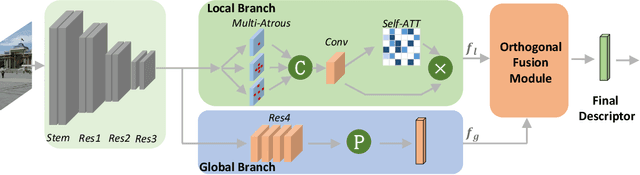
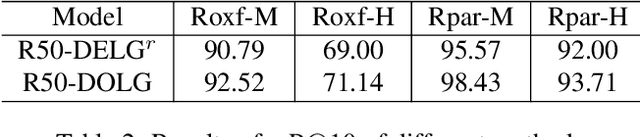
Image Retrieval is a fundamental task of obtaining images similar to the query one from a database. A common image retrieval practice is to firstly retrieve candidate images via similarity search using global image features and then re-rank the candidates by leveraging their local features. Previous learning-based studies mainly focus on either global or local image representation learning to tackle the retrieval task. In this paper, we abandon the two-stage paradigm and seek to design an effective single-stage solution by integrating local and global information inside images into compact image representations. Specifically, we propose a Deep Orthogonal Local and Global (DOLG) information fusion framework for end-to-end image retrieval. It attentively extracts representative local information with multi-atrous convolutions and self-attention at first. Components orthogonal to the global image representation are then extracted from the local information. At last, the orthogonal components are concatenated with the global representation as a complementary, and then aggregation is performed to generate the final representation. The whole framework is end-to-end differentiable and can be trained with image-level labels. Extensive experimental results validate the effectiveness of our solution and show that our model achieves state-of-the-art image retrieval performances on Revisited Oxford and Paris datasets.
AdaAttN: Revisit Attention Mechanism in Arbitrary Neural Style Transfer
Aug 11, 2021
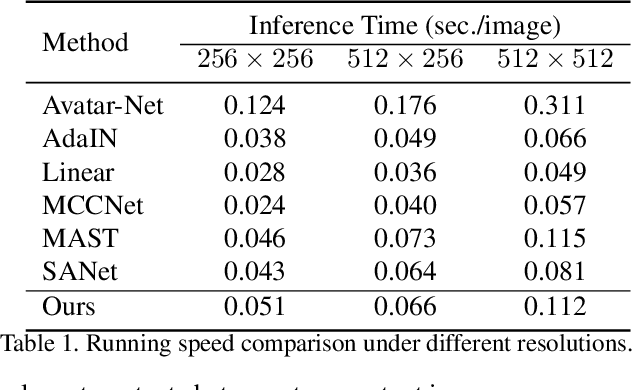
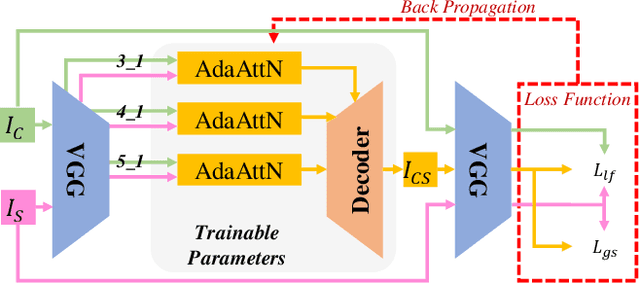

Fast arbitrary neural style transfer has attracted widespread attention from academic, industrial and art communities due to its flexibility in enabling various applications. Existing solutions either attentively fuse deep style feature into deep content feature without considering feature distributions, or adaptively normalize deep content feature according to the style such that their global statistics are matched. Although effective, leaving shallow feature unexplored and without locally considering feature statistics, they are prone to unnatural output with unpleasing local distortions. To alleviate this problem, in this paper, we propose a novel attention and normalization module, named Adaptive Attention Normalization (AdaAttN), to adaptively perform attentive normalization on per-point basis. Specifically, spatial attention score is learnt from both shallow and deep features of content and style images. Then per-point weighted statistics are calculated by regarding a style feature point as a distribution of attention-weighted output of all style feature points. Finally, the content feature is normalized so that they demonstrate the same local feature statistics as the calculated per-point weighted style feature statistics. Besides, a novel local feature loss is derived based on AdaAttN to enhance local visual quality. We also extend AdaAttN to be ready for video style transfer with slight modifications. Experiments demonstrate that our method achieves state-of-the-art arbitrary image/video style transfer. Codes and models are available.
Paint Transformer: Feed Forward Neural Painting with Stroke Prediction
Aug 11, 2021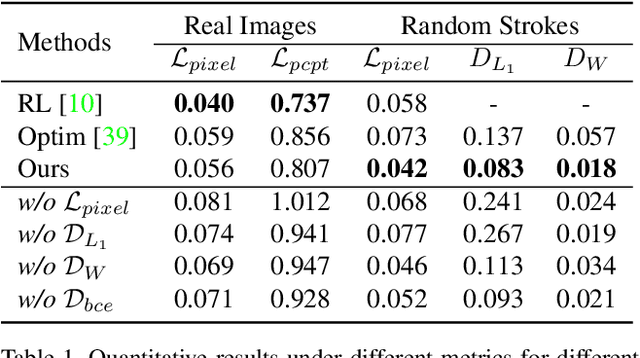
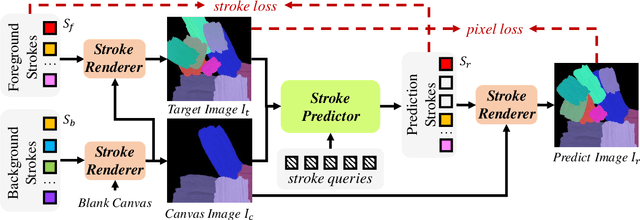
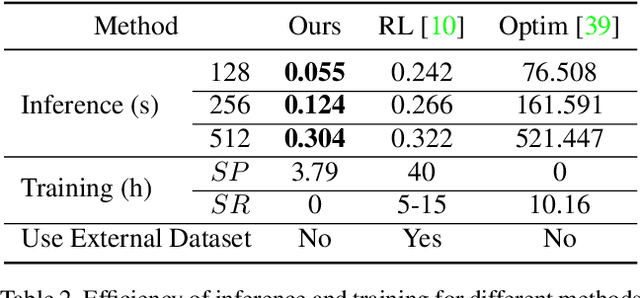
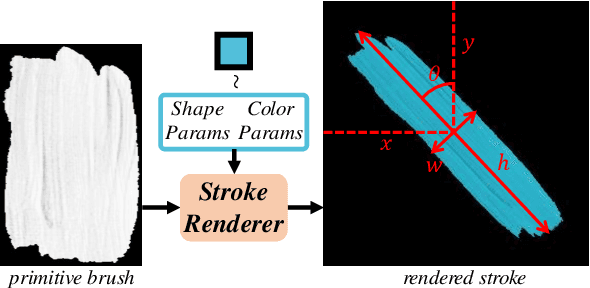
Neural painting refers to the procedure of producing a series of strokes for a given image and non-photo-realistically recreating it using neural networks. While reinforcement learning (RL) based agents can generate a stroke sequence step by step for this task, it is not easy to train a stable RL agent. On the other hand, stroke optimization methods search for a set of stroke parameters iteratively in a large search space; such low efficiency significantly limits their prevalence and practicality. Different from previous methods, in this paper, we formulate the task as a set prediction problem and propose a novel Transformer-based framework, dubbed Paint Transformer, to predict the parameters of a stroke set with a feed forward network. This way, our model can generate a set of strokes in parallel and obtain the final painting of size 512 * 512 in near real time. More importantly, since there is no dataset available for training the Paint Transformer, we devise a self-training pipeline such that it can be trained without any off-the-shelf dataset while still achieving excellent generalization capability. Experiments demonstrate that our method achieves better painting performance than previous ones with cheaper training and inference costs. Codes and models are available.
Learning Multi-Granular Spatio-Temporal Graph Network for Skeleton-based Action Recognition
Aug 10, 2021
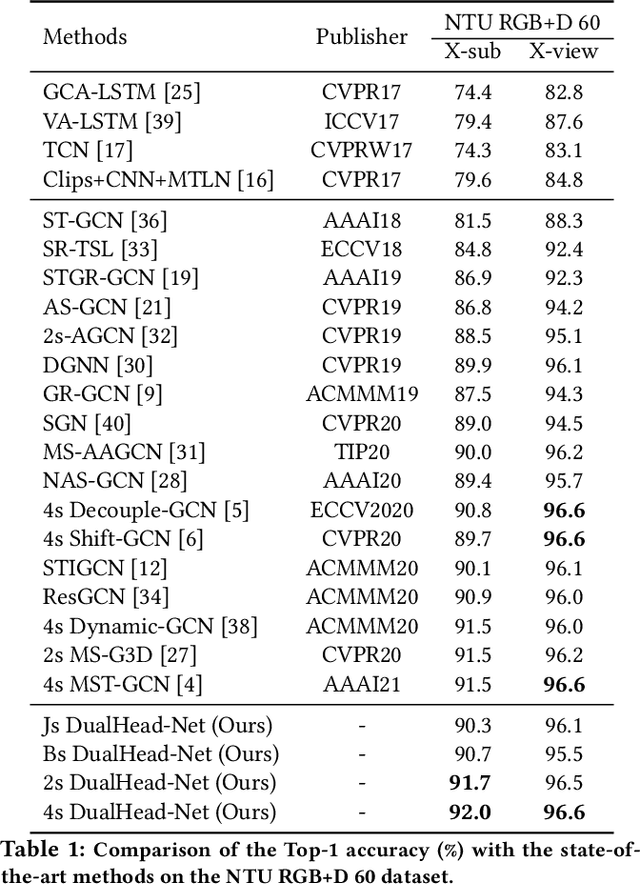
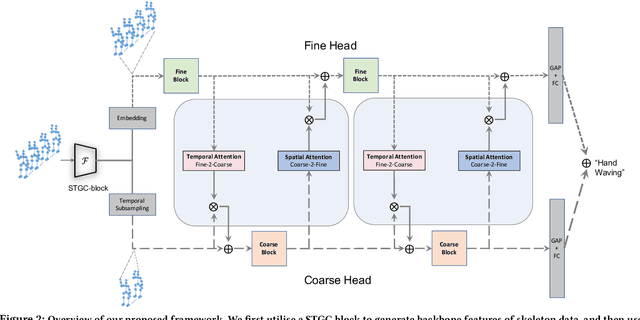
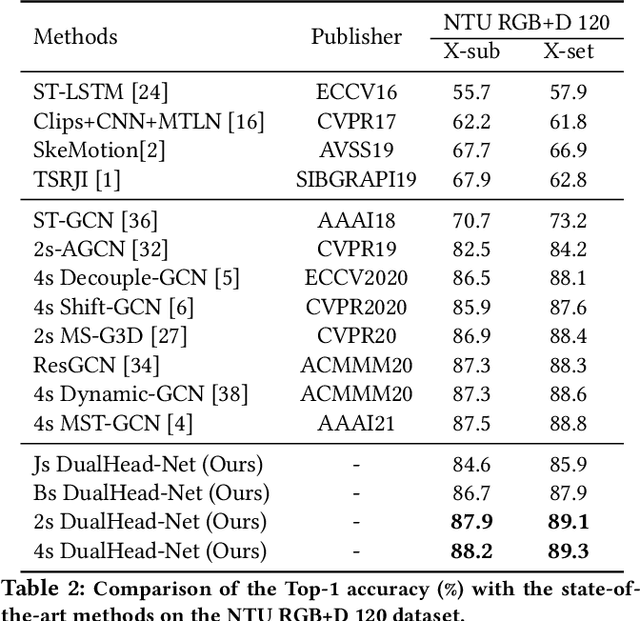
The task of skeleton-based action recognition remains a core challenge in human-centred scene understanding due to the multiple granularities and large variation in human motion. Existing approaches typically employ a single neural representation for different motion patterns, which has difficulty in capturing fine-grained action classes given limited training data. To address the aforementioned problems, we propose a novel multi-granular spatio-temporal graph network for skeleton-based action classification that jointly models the coarse- and fine-grained skeleton motion patterns. To this end, we develop a dual-head graph network consisting of two interleaved branches, which enables us to extract features at two spatio-temporal resolutions in an effective and efficient manner. Moreover, our network utilises a cross-head communication strategy to mutually enhance the representations of both heads. We conducted extensive experiments on three large-scale datasets, namely NTU RGB+D 60, NTU RGB+D 120, and Kinetics-Skeleton, and achieves the state-of-the-art performance on all the benchmarks, which validates the effectiveness of our method.