 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen the Same Musical Knowledge Forgets Differently: A Clean Probe of Pathway-Dependent Forgetting
Jun 17, 2026A model can learn that the piano piece Für Elise is calm and reflective by listening to the audio or by reading a text description, but does it matter which route that knowledge took when it is later at risk of being forgotten? Forgetting research in multimodal models measures what knowledge is lost under adaptation, yet has not asked whether acquisition route affects how easily that knowledge is forgotten. We call this untested premise the Pathway-Invariant Assumption. Music understanding enables a clean test because a music clip and a canonical text description can be aligned to the same perceptual content, allowing the same knowledge unit to enter a model through listening or reading while the target remains fixed. Across multiple architecturally distinct audio-language models, we observe a consistent asymmetry: text-pathway knowledge is forgotten more than matched audio-pathway knowledge under identical adaptation pressure. To attribute this effect to route rather than confounds, we introduce the Paired Pathway Controlled Protocol (PPCP), a three-phase design that establishes matched pathway baselines, activates both pathways under symmetric supervision on the same knowledge pool, and applies identical forgetting pressure to both pathways. The gap is stable across models and gain-controlled analyses, persists when contradictory overwrite is replaced by correct-label cross-domain learning, remains under single-modality pressure, and is not removed by lightweight replay. Two independent routing-depth controls confirm that the effect is not explained by architectural depth, pointing to input representation as the dominant factor. Under PPCP, our results demonstrate that forgetting is highly route-dependent, establishing acquisition route as a new analytical dimension for forgetting research and multimodal system design.
Trans-RAG: Query-Centric Vector Transformation for Secure Cross-Organizational Retrieval
Apr 10, 2026Retrieval Augmented Generation (RAG) systems deployed across organizational boundaries face fundamental tensions between security, accuracy, and efficiency. Current encryption methods expose plaintext during decryption, while federated architectures prevent resource integration and incur substantial overhead. We introduce Trans-RAG, implementing a novel vector space language paradigm where each organization's knowledge exists in a mathematically isolated semantic space. At the core lies vector2Trans, a multi-stage transformation technique that enables queries to dynamically "speak" each organization's vector space "language" through query-centric transformations, eliminating decryption overhead while maintaining native retrieval efficiency. Security evaluations demonstrate near-orthogonal vector spaces with 89.90° angular separation and 99.81% isolation rates. Experiments across 8 retrievers, 3 datasets, and 3 LLMs show minimal accuracy degradation (3.5% decrease in nDCG@10) and significant efficiency improvements over homomorphic encryption.
SpiralDiff: Spiral Diffusion with LoRA for RGB-to-RAW Conversion Across Cameras
Mar 16, 2026RAW images preserve superior fidelity and rich scene information compared to RGB, making them essential for tasks in challenging imaging conditions. To alleviate the high cost of data collection, recent RGB-to-RAW conversion methods aim to synthesize RAW images from RGB. However, they overlook two key challenges: (i) the reconstruction difficulty varies with pixel intensity, and (ii) multi-camera conversion requires camera-specific adaptation. To address these issues, we propose SpiralDiff, a diffusion-based framework tailored for RGB-to-RAW conversion with a signal-dependent noise weighting strategy that adapts reconstruction fidelity across intensity levels. In addition, we introduce CamLoRA, a camera-aware lightweight adaptation module that enables a unified model to adapt to different camera-specific ISP characteristics. Extensive experiments on four benchmark datasets demonstrate the superiority of SpiralDiff in RGB-to-RAW conversion quality and its downstream benefits in RAW-based object detection. Our code and model are available at https://github.com/Chuancy-TJU/SpiralDiff.
A Hierarchical Error-Corrective Graph Framework for Autonomous Agents with LLM-Based Action Generation
Mar 09, 2026We propose a Hierarchical Error-Corrective Graph FrameworkforAutonomousAgentswithLLM-BasedActionGeneration(HECG),whichincorporates three core innovations: (1) Multi-Dimensional Transferable Strategy (MDTS): by integrating task quality metrics (Q), confidence/cost metrics (C), reward metrics (R), and LLM-based semantic reasoning scores (LLM-Score), MDTS achieves multi-dimensional alignment between quantitative performance and semantic context, enabling more precise selection of high-quality candidate strate gies and effectively reducing the risk of negative transfer. (2) Error Matrix Classification (EMC): unlike simple confusion matrices or overall performance metrics, EMC provides structured attribution of task failures by categorizing errors into ten types, such as Strategy Errors (Strategy Whe) and Script Parsing Errors (Script-Parsing-Error), and decomposing them according to severity, typical actions, error descriptions, and recoverability. This allows precise analysis of the root causes of task failures, offering clear guidance for subsequent error correction and strategy optimization rather than relying solely on overall success rates or single performance metrics. (3) Causal-Context Graph Retrieval (CCGR): to enhance agent retrieval capabilities in dynamic task environments, we construct graphs from historical states, actions, and event sequences, where nodes store executed actions, next-step actions, execution states, transferable strategies, and other relevant information, and edges represent causal dependencies such as preconditions for transitions between nodes. CCGR identifies subgraphs most relevant to the current task context, effectively capturing structural relationships beyond vector similarity, allowing agents to fully leverage contextual information, accelerate strategy adaptation, and improve execution reliability in complex, multi-step tasks.
Spatio-Temporal Garment Reconstruction Using Diffusion Mapping via Pattern Coordinates
Feb 27, 2026Reconstructing 3D clothed humans from monocular images and videos is a fundamental problem with applications in virtual try-on, avatar creation, and mixed reality. Despite significant progress in human body recovery, accurately reconstructing garment geometry, particularly for loose-fitting clothing, remains an open challenge. We propose a unified framework for high-fidelity 3D garment reconstruction from both single images and video sequences. Our approach combines Implicit Sewing Patterns (ISP) with a generative diffusion model to learn expressive garment shape priors in 2D UV space. Leveraging these priors, we introduce a mapping model that establishes correspondences between image pixels, UV pattern coordinates, and 3D geometry, enabling accurate and detailed garment reconstruction from single images. We further extend this formulation to dynamic reconstruction by introducing a spatio-temporal diffusion scheme with test-time guidance to enforce long-range temporal consistency. We also develop analytic projection-based constraints that preserve image-aligned geometry in visible regions while enforcing coherent completion in occluded areas over time. Although trained exclusively on synthetically simulated cloth data, our method generalizes well to real-world imagery and consistently outperforms existing approaches on both tight- and loose-fitting garments. The reconstructed garments preserve fine geometric detail while exhibiting realistic dynamic motion, supporting downstream applications such as texture editing, garment retargeting, and animation.
CRAFT: Calibrated Reasoning with Answer-Faithful Traces via Reinforcement Learning for Multi-Hop Question Answering
Feb 01, 2026Retrieval-augmented generation (RAG) is widely used to ground Large Language Models (LLMs) for multi-hop question answering. Recent work mainly focused on improving answer accuracy via fine-tuning and structured or reinforcement-based optimization. However, reliable reasoning in response generation faces three challenges: 1) Reasoning Collapse. Reasoning in multi-hop QA is inherently complex due to multi-hop composition and is further destabilized by noisy retrieval. 2) Reasoning-answer inconsistency. Due to the intrinsic uncertainty of LLM generation and exposure to evidence--distractor mixtures, models may produce correct answers that are not faithfully supported by their intermediate reasoning or evidence. 3) Loss of format control. Traditional chain-of-thought generation often deviates from required structured output formats, leading to incomplete or malformed structured content. To address these challenges, we propose CRAFT (Calibrated Reasoning with Answer-Faithful Traces), a Group Relative Policy Optimization (GRPO) based reinforcement learning framework that trains models to perform faithful reasoning during response generation. CRAFT employs dual reward mechanisms to optimize multi-hop reasoning: deterministic rewards ensure structural correctness while judge-based rewards verify semantic faithfulness. This optimization framework supports controllable trace variants that enable systematic analysis of how structure and scale affect reasoning performance and faithfulness. Experiments on three multi-hop QA benchmarks show that CRAFT improves both answer accuracy and reasoning faithfulness across model scales, with the CRAFT 7B model achieving competitive performance with closed-source LLMs across multiple reasoning trace settings.
MuVaC: AVariational Causal Framework for Multimodal Sarcasm Understanding in Dialogues
Jan 28, 2026The prevalence of sarcasm in multimodal dialogues on the social platforms presents a crucial yet challenging task for understanding the true intent behind online content. Comprehensive sarcasm analysis requires two key aspects: Multimodal Sarcasm Detection (MSD) and Multimodal Sarcasm Explanation (MuSE). Intuitively, the act of detection is the result of the reasoning process that explains the sarcasm. Current research predominantly focuses on addressing either MSD or MuSE as a single task. Even though some recent work has attempted to integrate these tasks, their inherent causal dependency is often overlooked. To bridge this gap, we propose MuVaC, a variational causal inference framework that mimics human cognitive mechanisms for understanding sarcasm, enabling robust multimodal feature learning to jointly optimize MSD and MuSE. Specifically, we first model MSD and MuSE from the perspective of structural causal models, establishing variational causal pathways to define the objectives for joint optimization. Next, we design an alignment-then-fusion approach to integrate multimodal features, providing robust fusion representations for sarcasm detection and explanation generation. Finally, we enhance the reasoning trustworthiness by ensuring consistency between detection results and explanations. Experimental results demonstrate the superiority of MuVaC in public datasets, offering a new perspective for understanding multimodal sarcasm.
Learning Sewing Patterns via Latent Flow Matching of Implicit Fields
Jan 25, 2026Sewing patterns define the structural foundation of garments and are essential for applications such as fashion design, fabrication, and physical simulation. Despite progress in automated pattern generation, accurately modeling sewing patterns remains difficult due to the broad variability in panel geometry and seam arrangements. In this work, we introduce a sewing pattern modeling method based on an implicit representation. We represent each panel using a signed distance field that defines its boundary and an unsigned distance field that identifies seam endpoints, and encode these fields into a continuous latent space that enables differentiable meshing. A latent flow matching model learns distributions over panel combinations in this representation, and a stitching prediction module recovers seam relations from extracted edge segments. This formulation allows accurate modeling and generation of sewing patterns with complex structures. We further show that it can be used to estimate sewing patterns from images with improved accuracy relative to existing approaches, and supports applications such as pattern completion and refitting, providing a practical tool for digital fashion design.
Parameter-Efficient MoE LoRA for Few-Shot Multi-Style Editing
Nov 14, 2025
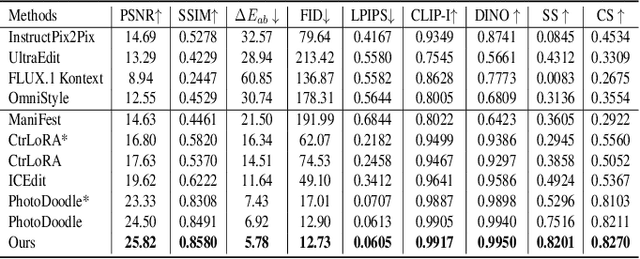


In recent years, image editing has garnered growing attention. However, general image editing models often fail to produce satisfactory results when confronted with new styles. The challenge lies in how to effectively fine-tune general image editing models to new styles using only a limited amount of paired data. To address this issue, this paper proposes a novel few-shot style editing framework. For this task, we construct a benchmark dataset that encompasses five distinct styles. Correspondingly, we propose a parameter-efficient multi-style Mixture-of-Experts Low-Rank Adaptation (MoE LoRA) with style-specific and style-shared routing mechanisms for jointly fine-tuning multiple styles. The style-specific routing ensures that different styles do not interfere with one another, while the style-shared routing adaptively allocates shared MoE LoRAs to learn common patterns. Our MoE LoRA can automatically determine the optimal ranks for each layer through a novel metric-guided approach that estimates the importance score of each single-rank component. Additionally, we explore the optimal location to insert LoRA within the Diffusion in Transformer (DiT) model and integrate adversarial learning and flow matching to guide the diffusion training process. Experimental results demonstrate that our proposed method outperforms existing state-of-the-art approaches with significantly fewer LoRA parameters.
LUIVITON: Learned Universal Interoperable VIrtual Try-ON
Sep 05, 2025



We present LUIVITON, an end-to-end system for fully automated virtual try-on, capable of draping complex, multi-layer clothing onto diverse and arbitrarily posed humanoid characters. To address the challenge of aligning complex garments with arbitrary and highly diverse body shapes, we use SMPL as a proxy representation and separate the clothing-to-body draping problem into two correspondence tasks: 1) clothing-to-SMPL and 2) body-to-SMPL correspondence, where each has its unique challenges. While we address the clothing-to-SMPL fitting problem using a geometric learning-based approach for partial-to-complete shape correspondence prediction, we introduce a diffusion model-based approach for body-to-SMPL correspondence using multi-view consistent appearance features and a pre-trained 2D foundation model. Our method can handle complex geometries, non-manifold meshes, and generalizes effectively to a wide range of humanoid characters -- including humans, robots, cartoon subjects, creatures, and aliens, while maintaining computational efficiency for practical adoption. In addition to offering a fully automatic fitting solution, LUIVITON supports fast customization of clothing size, allowing users to adjust clothing sizes and material properties after they have been draped. We show that our system can produce high-quality 3D clothing fittings without any human labor, even when 2D clothing sewing patterns are not available.