 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiHateLoc: Towards Temporal Localisation of Multimodal Hate Content in Online Videos
Dec 11, 2025The rapid growth of video content on platforms such as TikTok and YouTube has intensified the spread of multimodal hate speech, where harmful cues emerge subtly and asynchronously across visual, acoustic, and textual streams. Existing research primarily focuses on video-level classification, leaving the practically crucial task of temporal localisation, identifying when hateful segments occur, largely unaddressed. This challenge is even more noticeable under weak supervision, where only video-level labels are available, and static fusion or classification-based architectures struggle to capture cross-modal and temporal dynamics. To address these challenges, we propose MultiHateLoc, the first framework designed for weakly-supervised multimodal hate localisation. MultiHateLoc incorporates (1) modality-aware temporal encoders to model heterogeneous sequential patterns, including a tailored text-based preprocessing module for feature enhancement; (2) dynamic cross-modal fusion to adaptively emphasise the most informative modality at each moment and a cross-modal contrastive alignment strategy to enhance multimodal feature consistency; (3) a modality-aware MIL objective to identify discriminative segments under video-level supervision. Despite relying solely on coarse labels, MultiHateLoc produces fine-grained, interpretable frame-level predictions. Experiments on HateMM and MultiHateClip show that our method achieves state-of-the-art performance in the localisation task.
Revealing Temporal Label Noise in Multimodal Hateful Video Classification
Aug 06, 2025The rapid proliferation of online multimedia content has intensified the spread of hate speech, presenting critical societal and regulatory challenges. While recent work has advanced multimodal hateful video detection, most approaches rely on coarse, video-level annotations that overlook the temporal granularity of hateful content. This introduces substantial label noise, as videos annotated as hateful often contain long non-hateful segments. In this paper, we investigate the impact of such label ambiguity through a fine-grained approach. Specifically, we trim hateful videos from the HateMM and MultiHateClip English datasets using annotated timestamps to isolate explicitly hateful segments. We then conduct an exploratory analysis of these trimmed segments to examine the distribution and characteristics of both hateful and non-hateful content. This analysis highlights the degree of semantic overlap and the confusion introduced by coarse, video-level annotations. Finally, controlled experiments demonstrated that time-stamp noise fundamentally alters model decision boundaries and weakens classification confidence, highlighting the inherent context dependency and temporal continuity of hate speech expression. Our findings provide new insights into the temporal dynamics of multimodal hateful videos and highlight the need for temporally aware models and benchmarks for improved robustness and interpretability. Code and data are available at https://github.com/Multimodal-Intelligence-Lab-MIL/HatefulVideoLabelNoise.
Enhanced Multimodal Hate Video Detection via Channel-wise and Modality-wise Fusion
May 17, 2025The rapid rise of video content on platforms such as TikTok and YouTube has transformed information dissemination, but it has also facilitated the spread of harmful content, particularly hate videos. Despite significant efforts to combat hate speech, detecting these videos remains challenging due to their often implicit nature. Current detection methods primarily rely on unimodal approaches, which inadequately capture the complementary features across different modalities. While multimodal techniques offer a broader perspective, many fail to effectively integrate temporal dynamics and modality-wise interactions essential for identifying nuanced hate content. In this paper, we present CMFusion, an enhanced multimodal hate video detection model utilizing a novel Channel-wise and Modality-wise Fusion Mechanism. CMFusion first extracts features from text, audio, and video modalities using pre-trained models and then incorporates a temporal cross-attention mechanism to capture dependencies between video and audio streams. The learned features are then processed by channel-wise and modality-wise fusion modules to obtain informative representations of videos. Our extensive experiments on a real-world dataset demonstrate that CMFusion significantly outperforms five widely used baselines in terms of accuracy, precision, recall, and F1 score. Comprehensive ablation studies and parameter analyses further validate our design choices, highlighting the model's effectiveness in detecting hate videos. The source codes will be made publicly available at https://github.com/EvelynZ10/cmfusion.
* ICDMW 2024, Github: https://github.com/EvelynZ10/cmfusion
Part-aware Prototypical Graph Network for One-shot Skeleton-based Action Recognition
Aug 19, 2022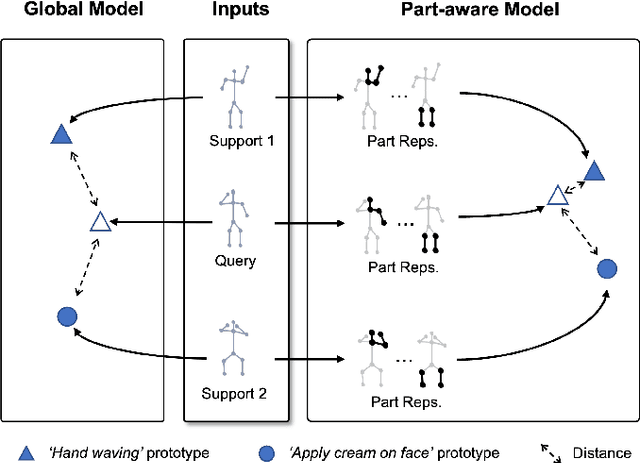
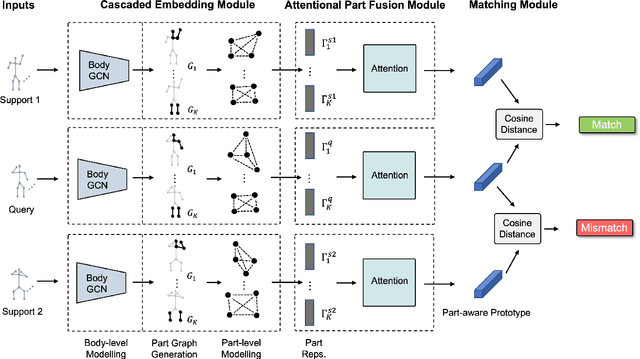
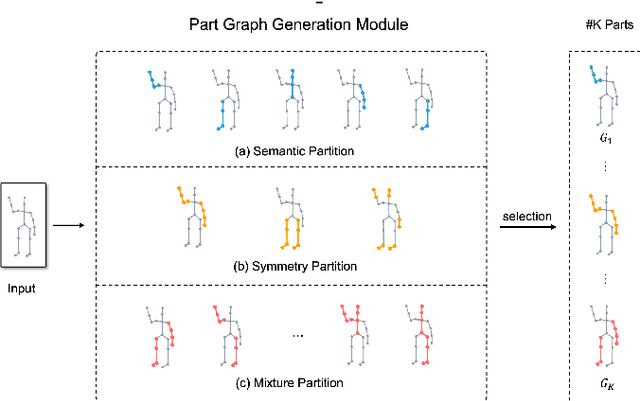
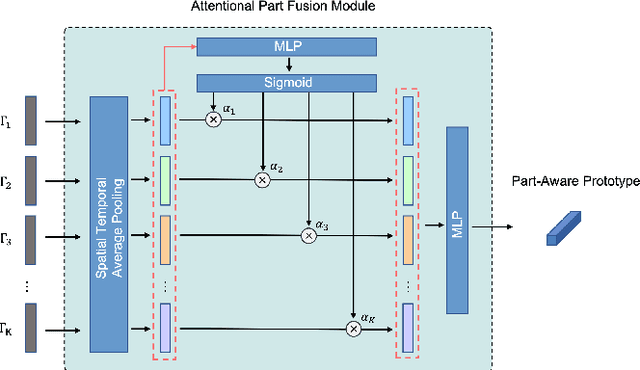
In this paper, we study the problem of one-shot skeleton-based action recognition, which poses unique challenges in learning transferable representation from base classes to novel classes, particularly for fine-grained actions. Existing meta-learning frameworks typically rely on the body-level representations in spatial dimension, which limits the generalisation to capture subtle visual differences in the fine-grained label space. To overcome the above limitation, we propose a part-aware prototypical representation for one-shot skeleton-based action recognition. Our method captures skeleton motion patterns at two distinctive spatial levels, one for global contexts among all body joints, referred to as body level, and the other attends to local spatial regions of body parts, referred to as the part level. We also devise a class-agnostic attention mechanism to highlight important parts for each action class. Specifically, we develop a part-aware prototypical graph network consisting of three modules: a cascaded embedding module for our dual-level modelling, an attention-based part fusion module to fuse parts and generate part-aware prototypes, and a matching module to perform classification with the part-aware representations. We demonstrate the effectiveness of our method on two public skeleton-based action recognition datasets: NTU RGB+D 120 and NW-UCLA.
LSTA-Net: Long short-term Spatio-Temporal Aggregation Network for Skeleton-based Action Recognition
Nov 01, 2021
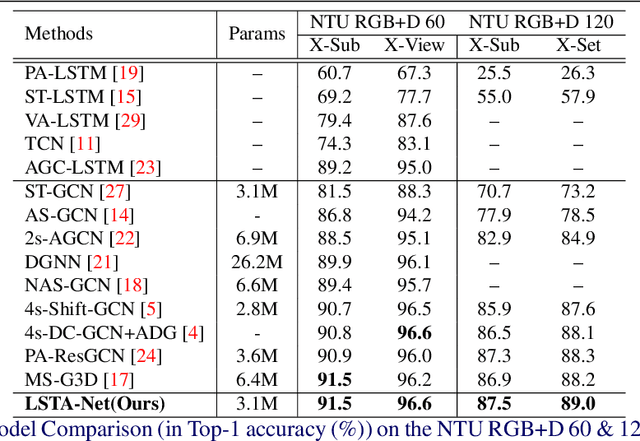


Modelling various spatio-temporal dependencies is the key to recognising human actions in skeleton sequences. Most existing methods excessively relied on the design of traversal rules or graph topologies to draw the dependencies of the dynamic joints, which is inadequate to reflect the relationships of the distant yet important joints. Furthermore, due to the locally adopted operations, the important long-range temporal information is therefore not well explored in existing works. To address this issue, in this work we propose LSTA-Net: a novel Long short-term Spatio-Temporal Aggregation Network, which can effectively capture the long/short-range dependencies in a spatio-temporal manner. We devise our model into a pure factorised architecture which can alternately perform spatial feature aggregation and temporal feature aggregation. To improve the feature aggregation effect, a channel-wise attention mechanism is also designed and employed. Extensive experiments were conducted on three public benchmark datasets, and the results suggest that our approach can capture both long-and-short range dependencies in the space and time domain, yielding higher results than other state-of-the-art methods. Code available at https://github.com/tailin1009/LSTA-Net.
Learning Multi-Granular Spatio-Temporal Graph Network for Skeleton-based Action Recognition
Aug 10, 2021
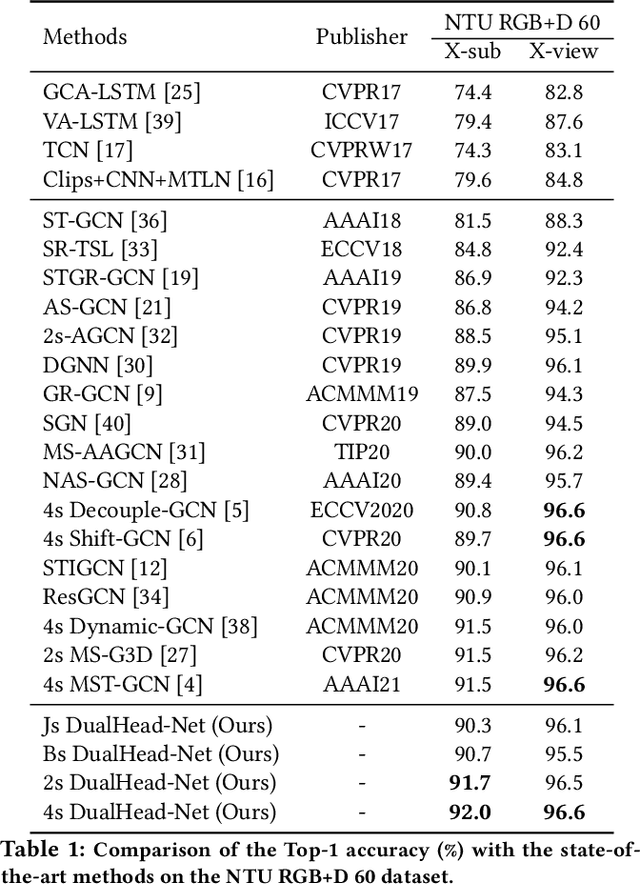
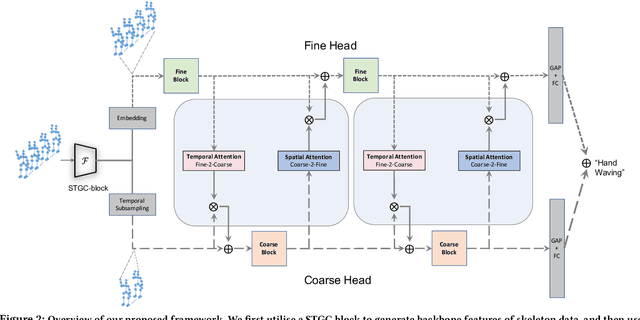
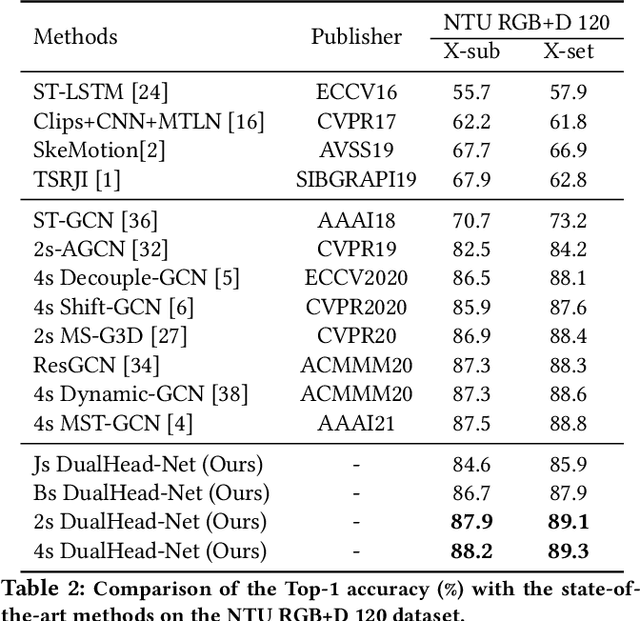
The task of skeleton-based action recognition remains a core challenge in human-centred scene understanding due to the multiple granularities and large variation in human motion. Existing approaches typically employ a single neural representation for different motion patterns, which has difficulty in capturing fine-grained action classes given limited training data. To address the aforementioned problems, we propose a novel multi-granular spatio-temporal graph network for skeleton-based action classification that jointly models the coarse- and fine-grained skeleton motion patterns. To this end, we develop a dual-head graph network consisting of two interleaved branches, which enables us to extract features at two spatio-temporal resolutions in an effective and efficient manner. Moreover, our network utilises a cross-head communication strategy to mutually enhance the representations of both heads. We conducted extensive experiments on three large-scale datasets, namely NTU RGB+D 60, NTU RGB+D 120, and Kinetics-Skeleton, and achieves the state-of-the-art performance on all the benchmarks, which validates the effectiveness of our method.