 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeF2HDR: Two-Stage HDR Video Reconstruction via Flow Adapter and Physical Motion Modeling
Mar 18, 2026Reconstructing High Dynamic Range (HDR) videos from sequences of alternating-exposure Low Dynamic Range (LDR) frames remains highly challenging, especially under dynamic scenes where cross-exposure inconsistencies and complex motion make inter-frame alignment difficult, leading to ghosting and detail loss. Existing methods often suffer from inaccurate alignment, suboptimal feature aggregation, and degraded reconstruction quality in motion-dominated regions. To address these challenges, we propose F2HDR, a two-stage HDR video reconstruction framework that robustly perceives inter-frame motion and restores fine details in complex dynamic scenarios. The proposed framework integrates a flow adapter that adapts generic optical flow for robust cross-exposure alignment, a physical motion modeling to identify salient motion regions, and a motion-aware refinement network that aggregates complementary information while removing ghosting and noise. Extensive experiments demonstrate that F2HDR achieves state-of-the-art performance on real-world HDR video benchmarks, producing ghost-free and high-fidelity results under large motion and exposure variations.
$\text{F}^2\text{HDR}$: Two-Stage HDR Video Reconstruction via Flow Adapter and Physical Motion Modeling
Mar 16, 2026Reconstructing High Dynamic Range (HDR) videos from sequences of alternating-exposure Low Dynamic Range (LDR) frames remains highly challenging, especially under dynamic scenes where cross-exposure inconsistencies and complex motion make inter-frame alignment difficult, leading to ghosting and detail loss. Existing methods often suffer from inaccurate alignment, suboptimal feature aggregation, and degraded reconstruction quality in motion-dominated regions. To address these challenges, we propose $\text{F}^2\text{HDR}$, a two-stage HDR video reconstruction framework that robustly perceives inter-frame motion and restores fine details in complex dynamic scenarios. The proposed framework integrates a flow adapter that adapts generic optical flow for robust cross-exposure alignment, a physical motion modeling to identify salient motion regions, and a motion-aware refinement network that aggregates complementary information while removing ghosting and noise. Extensive experiments demonstrate that $\text{F}^2\text{HDR}$ achieves state-of-the-art performance on real-world HDR video benchmarks, producing ghost-free and high-fidelity results under large motion and exposure variations.
SpiralDiff: Spiral Diffusion with LoRA for RGB-to-RAW Conversion Across Cameras
Mar 16, 2026RAW images preserve superior fidelity and rich scene information compared to RGB, making them essential for tasks in challenging imaging conditions. To alleviate the high cost of data collection, recent RGB-to-RAW conversion methods aim to synthesize RAW images from RGB. However, they overlook two key challenges: (i) the reconstruction difficulty varies with pixel intensity, and (ii) multi-camera conversion requires camera-specific adaptation. To address these issues, we propose SpiralDiff, a diffusion-based framework tailored for RGB-to-RAW conversion with a signal-dependent noise weighting strategy that adapts reconstruction fidelity across intensity levels. In addition, we introduce CamLoRA, a camera-aware lightweight adaptation module that enables a unified model to adapt to different camera-specific ISP characteristics. Extensive experiments on four benchmark datasets demonstrate the superiority of SpiralDiff in RGB-to-RAW conversion quality and its downstream benefits in RAW-based object detection. Our code and model are available at https://github.com/Chuancy-TJU/SpiralDiff.
Distribution-Specific Learning for Joint Salient and Camouflaged Object Detection
Aug 08, 2025Salient object detection (SOD) and camouflaged object detection (COD) are two closely related but distinct computer vision tasks. Although both are class-agnostic segmentation tasks that map from RGB space to binary space, the former aims to identify the most salient objects in the image, while the latter focuses on detecting perfectly camouflaged objects that blend into the background in the image. These two tasks exhibit strong contradictory attributes. Previous works have mostly believed that joint learning of these two tasks would confuse the network, reducing its performance on both tasks. However, here we present an opposite perspective: with the correct approach to learning, the network can simultaneously possess the capability to find both salient and camouflaged objects, allowing both tasks to benefit from joint learning. We propose SCJoint, a joint learning scheme for SOD and COD tasks, assuming that the decoding processes of SOD and COD have different distribution characteristics. The key to our method is to learn the respective means and variances of the decoding processes for both tasks by inserting a minimal amount of task-specific learnable parameters within a fully shared network structure, thereby decoupling the contradictory attributes of the two tasks at a minimal cost. Furthermore, we propose a saliency-based sampling strategy (SBSS) to sample the training set of the SOD task to balance the training set sizes of the two tasks. In addition, SBSS improves the training set quality and shortens the training time. Based on the proposed SCJoint and SBSS, we train a powerful generalist network, named JoNet, which has the ability to simultaneously capture both ``salient" and ``camouflaged". Extensive experiments demonstrate the competitive performance and effectiveness of our proposed method. The code is available at https://github.com/linuxsino/JoNet.
FEALLM: Advancing Facial Emotion Analysis in Multimodal Large Language Models with Emotional Synergy and Reasoning
May 19, 2025Facial Emotion Analysis (FEA) plays a crucial role in visual affective computing, aiming to infer a person's emotional state based on facial data. Scientifically, facial expressions (FEs) result from the coordinated movement of facial muscles, which can be decomposed into specific action units (AUs) that provide detailed emotional insights. However, traditional methods often struggle with limited interpretability, constrained generalization and reasoning abilities. Recently, Multimodal Large Language Models (MLLMs) have shown exceptional performance in various visual tasks, while they still face significant challenges in FEA due to the lack of specialized datasets and their inability to capture the intricate relationships between FEs and AUs. To address these issues, we introduce a novel FEA Instruction Dataset that provides accurate and aligned FE and AU descriptions and establishes causal reasoning relationships between them, followed by constructing a new benchmark, FEABench. Moreover, we propose FEALLM, a novel MLLM architecture designed to capture more detailed facial information, enhancing its capability in FEA tasks. Our model demonstrates strong performance on FEABench and impressive generalization capability through zero-shot evaluation on various datasets, including RAF-DB, AffectNet, BP4D, and DISFA, showcasing its robustness and effectiveness in FEA tasks. The dataset and code will be available at https://github.com/953206211/FEALLM.
DSDNet: Raw Domain Demoiréing via Dual Color-Space Synergy
Apr 22, 2025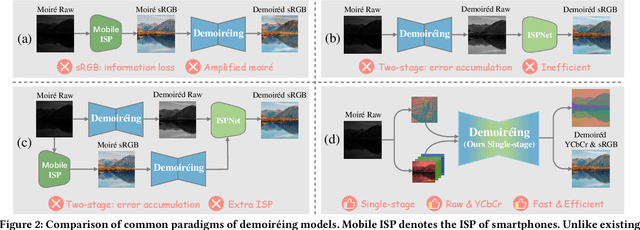
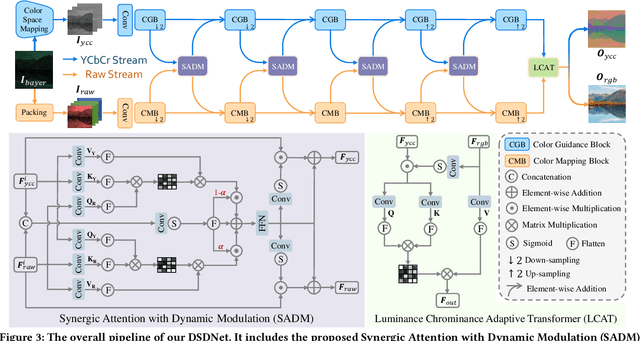
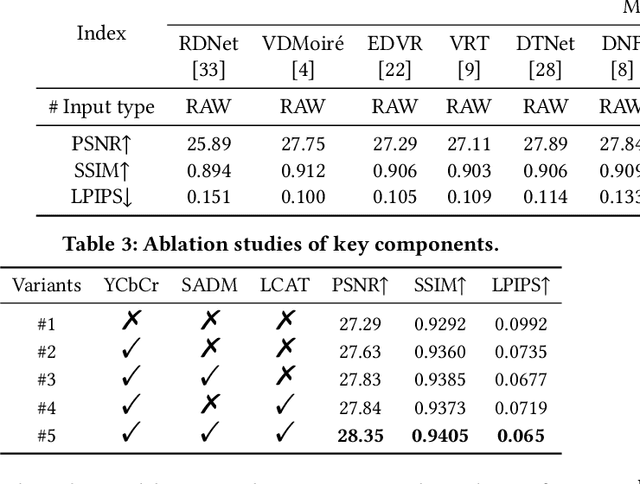

With the rapid advancement of mobile imaging, capturing screens using smartphones has become a prevalent practice in distance learning and conference recording. However, moir\'e artifacts, caused by frequency aliasing between display screens and camera sensors, are further amplified by the image signal processing pipeline, leading to severe visual degradation. Existing sRGB domain demoir\'eing methods struggle with irreversible information loss, while recent two-stage raw domain approaches suffer from information bottlenecks and inference inefficiency. To address these limitations, we propose a single-stage raw domain demoir\'eing framework, Dual-Stream Demoir\'eing Network (DSDNet), which leverages the synergy of raw and YCbCr images to remove moir\'e while preserving luminance and color fidelity. Specifically, to guide luminance correction and moir\'e removal, we design a raw-to-YCbCr mapping pipeline and introduce the Synergic Attention with Dynamic Modulation (SADM) module. This module enriches the raw-to-sRGB conversion with cross-domain contextual features. Furthermore, to better guide color fidelity, we develop a Luminance-Chrominance Adaptive Transformer (LCAT), which decouples luminance and chrominance representations. Extensive experiments demonstrate that DSDNet outperforms state-of-the-art methods in both visual quality and quantitative evaluation, and achieves an inference speed $\mathrm{\textbf{2.4x}}$ faster than the second-best method, highlighting its practical advantages. We provide an anonymous online demo at https://xxxxxxxxdsdnet.github.io/DSDNet/.
NTIRE 2025 Challenge on Day and Night Raindrop Removal for Dual-Focused Images: Methods and Results
Apr 19, 2025



This paper reviews the NTIRE 2025 Challenge on Day and Night Raindrop Removal for Dual-Focused Images. This challenge received a wide range of impressive solutions, which are developed and evaluated using our collected real-world Raindrop Clarity dataset. Unlike existing deraining datasets, our Raindrop Clarity dataset is more diverse and challenging in degradation types and contents, which includes day raindrop-focused, day background-focused, night raindrop-focused, and night background-focused degradations. This dataset is divided into three subsets for competition: 14,139 images for training, 240 images for validation, and 731 images for testing. The primary objective of this challenge is to establish a new and powerful benchmark for the task of removing raindrops under varying lighting and focus conditions. There are a total of 361 participants in the competition, and 32 teams submitting valid solutions and fact sheets for the final testing phase. These submissions achieved state-of-the-art (SOTA) performance on the Raindrop Clarity dataset. The project can be found at https://lixinustc.github.io/CVPR-NTIRE2025-RainDrop-Competition.github.io/.
Learning Differential Pyramid Representation for Tone Mapping
Dec 02, 2024



Previous tone mapping methods mainly focus on how to enhance tones in low-resolution images and recover details using the high-frequent components extracted from the input image. These methods typically rely on traditional feature pyramids to artificially extract high-frequency components, such as Laplacian and Gaussian pyramids with handcrafted kernels. However, traditional handcrafted features struggle to effectively capture the high-frequency components in HDR images, resulting in excessive smoothing and loss of detail in the output image. To mitigate the above issue, we introduce a learnable Differential Pyramid Representation Network (DPRNet). Based on the learnable differential pyramid, our DPRNet can capture detailed textures and structures, which is crucial for high-quality tone mapping recovery. In addition, to achieve global consistency and local contrast harmonization, we design a global tone perception module and a local tone tuning module that ensure the consistency of global tuning and the accuracy of local tuning, respectively. Extensive experiments demonstrate that our method significantly outperforms state-of-the-art methods, improving PSNR by 2.58 dB in the HDR+ dataset and 3.31 dB in the HDRI Haven dataset respectively compared with the second-best method. Notably, our method exhibits the best generalization ability in the non-homologous image and video tone mapping operation. We provide an anonymous online demo at https://xxxxxx2024.github.io/DPRNet/.
Learning Adaptive Lighting via Channel-Aware Guidance
Dec 02, 2024



Learning lighting adaption is a key step in obtaining a good visual perception and supporting downstream vision tasks. There are multiple light-related tasks (e.g., image retouching and exposure correction) and previous studies have mainly investigated these tasks individually. However, we observe that the light-related tasks share fundamental properties: i) different color channels have different light properties, and ii) the channel differences reflected in the time and frequency domains are different. Based on the common light property guidance, we propose a Learning Adaptive Lighting Network (LALNet), a unified framework capable of processing different light-related tasks. Specifically, we introduce the color-separated features that emphasize the light difference of different color channels and combine them with the traditional color-mixed features by Light Guided Attention (LGA). The LGA utilizes color-separated features to guide color-mixed features focusing on channel differences and ensuring visual consistency across channels. We introduce dual domain channel modulation to generate color-separated features and a wavelet followed by a vision state space module to generate color-mixed features. Extensive experiments on four representative light-related tasks demonstrate that LALNet significantly outperforms state-of-the-art methods on benchmark tests and requires fewer computational resources. We provide an anonymous online demo at https://xxxxxx2025.github.io/LALNet/.
Anatomical Consistency Distillation and Inconsistency Synthesis for Brain Tumor Segmentation with Missing Modalities
Aug 25, 2024



Multi-modal Magnetic Resonance Imaging (MRI) is imperative for accurate brain tumor segmentation, offering indispensable complementary information. Nonetheless, the absence of modalities poses significant challenges in achieving precise segmentation. Recognizing the shared anatomical structures between mono-modal and multi-modal representations, it is noteworthy that mono-modal images typically exhibit limited features in specific regions and tissues. In response to this, we present Anatomical Consistency Distillation and Inconsistency Synthesis (ACDIS), a novel framework designed to transfer anatomical structures from multi-modal to mono-modal representations and synthesize modality-specific features. ACDIS consists of two main components: Anatomical Consistency Distillation (ACD) and Modality Feature Synthesis Block (MFSB). ACD incorporates the Anatomical Feature Enhancement Block (AFEB), meticulously mining anatomical information. Simultaneously, Anatomical Consistency ConsTraints (ACCT) are employed to facilitate the consistent knowledge transfer, i.e., the richness of information and the similarity in anatomical structure, ensuring precise alignment of structural features across mono-modality and multi-modality. Complementarily, MFSB produces modality-specific features to rectify anatomical inconsistencies, thereby compensating for missing information in the segmented features. Through validation on the BraTS2018 and BraTS2020 datasets, ACDIS substantiates its efficacy in the segmentation of brain tumors with missing MRI modalities.