 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
GPRL: Gaussian Processes-Based Relative Localization for Multi-Robot Systems
Jul 20, 2023
Relative localization is crucial for multi-robot systems to perform cooperative tasks, especially in GPS-denied environments. Current techniques for multi-robot relative localization rely on expensive or short-range sensors such as cameras and LIDARs. As a result, these algorithms face challenges such as high computational complexity, dependencies on well-structured environments, etc. To overcome these limitations, we propose a new distributed approach to perform relative localization using a Gaussian Processes map of the Radio Signal Strength Indicator (RSSI) values from a single wireless Access Point (AP) to which the robots are connected. Our approach, Gaussian Processes-based Relative Localization (GPRL), combines two pillars. First, the robots locate the AP w.r.t. their local reference frames using novel hierarchical inferencing that significantly reduces computational complexity. Secondly, the robots obtain relative positions of neighbor robots with an AP-oriented vector transformation. The approach readily applies to resource-constrained devices and relies only on the ubiquitously-available RSSI measurement. We extensively validate the performance of the two pillars of the proposed GRPL in Robotarium simulations. We also demonstrate the applicability of GPRL through a multi-robot rendezvous task with a team of three real-world robots. The results demonstrate that GPRL outperformed state-of-the-art approaches regarding accuracy, computation, and real-time performance.
Predicting human motion intention for pHRI assistive control
Jul 20, 2023This work addresses human intention identification during physical Human-Robot Interaction (pHRI) tasks to include this information in an assistive controller. To this purpose, human intention is defined as the desired trajectory that the human wants to follow over a finite rolling prediction horizon so that the robot can assist in pursuing it. This work investigates a Recurrent Neural Network (RNN), specifically, Long-Short Term Memory (LSTM) cascaded with a Fully Connected layer. In particular, we propose an iterative training procedure to adapt the model. Such an iterative procedure is powerful in reducing the prediction error. Still, it has the drawback that it is time-consuming and does not generalize to different users or different co-manipulated objects. To overcome this issue, Transfer Learning (TL) adapts the pre-trained model to new trajectories, users, and co-manipulated objects by freezing the LSTM layer and fine-tuning the last FC layer, which makes the procedure faster. Experiments show that the iterative procedure adapts the model and reduces prediction error. Experiments also show that TL adapts to different users and to the co-manipulation of a large object. Finally, to check the utility of adopting the proposed method, we compare the proposed controller enhanced by the intention prediction with the other two standard controllers of pHRI.
Distilling Large Vision-Language Model with Out-of-Distribution Generalizability
Jul 19, 2023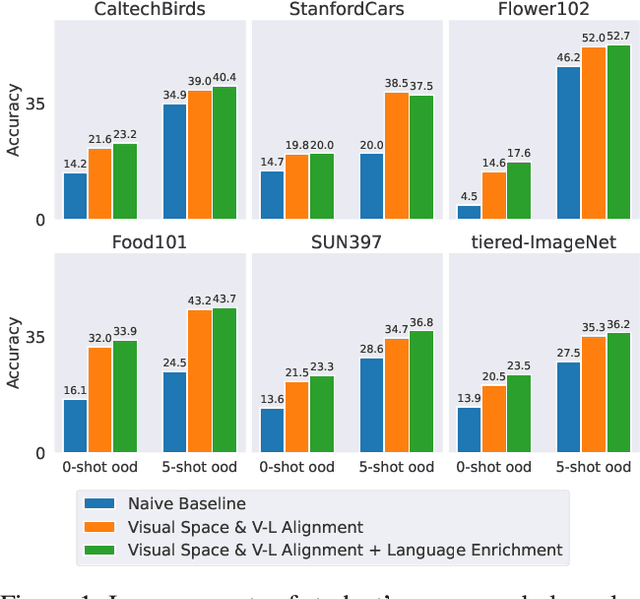
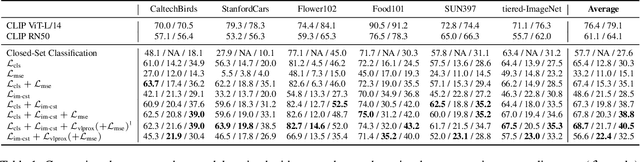
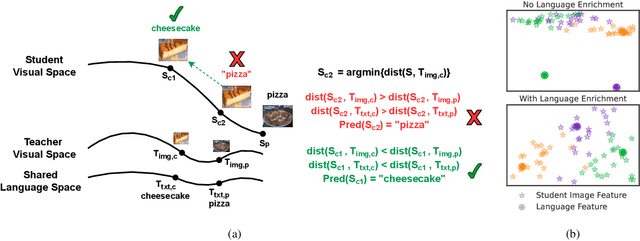
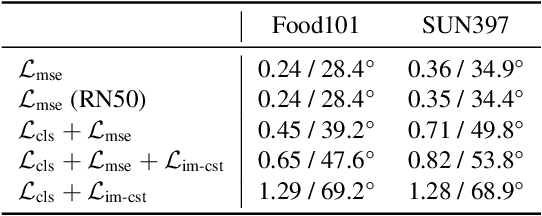
Large vision-language models have achieved outstanding performance, but their size and computational requirements make their deployment on resource-constrained devices and time-sensitive tasks impractical. Model distillation, the process of creating smaller, faster models that maintain the performance of larger models, is a promising direction towards the solution. This paper investigates the distillation of visual representations in large teacher vision-language models into lightweight student models using a small- or mid-scale dataset. Notably, this study focuses on open-vocabulary out-of-distribution (OOD) generalization, a challenging problem that has been overlooked in previous model distillation literature. We propose two principles from vision and language modality perspectives to enhance student's OOD generalization: (1) by better imitating teacher's visual representation space, and carefully promoting better coherence in vision-language alignment with the teacher; (2) by enriching the teacher's language representations with informative and finegrained semantic attributes to effectively distinguish between different labels. We propose several metrics and conduct extensive experiments to investigate their techniques. The results demonstrate significant improvements in zero-shot and few-shot student performance on open-vocabulary out-of-distribution classification, highlighting the effectiveness of our proposed approaches. Code released at https://github.com/xuanlinli17/large_vlm_distillation_ood
Generating Redstone Style Cities in Minecraft
Jul 19, 2023

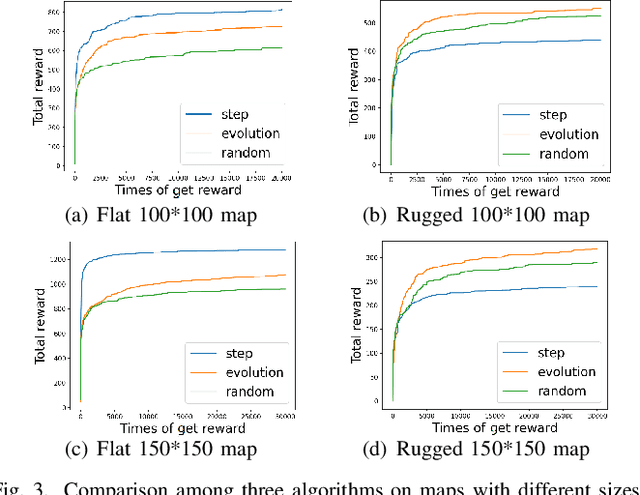
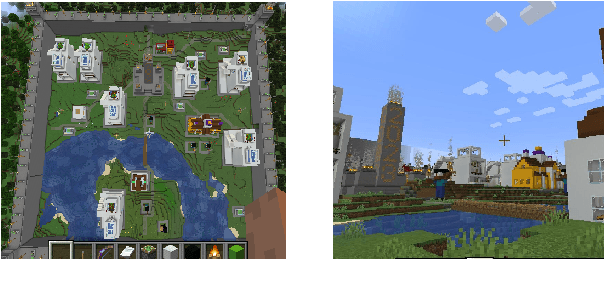
Procedurally generating cities in Minecraft provides players more diverse scenarios and could help understand and improve the design of cities in other digital worlds and the real world. This paper presents a city generator that was submitted as an entry to the 2023 Edition of Minecraft Settlement Generation Competition for Minecraft. The generation procedure is composed of six main steps, namely vegetation clearing, terrain reshaping, building layout generation, route planning, streetlight placement, and wall construction. Three algorithms, including a heuristic-based algorithm, an evolving layout algorithm, and a random one are applied to generate the building layout, thus determining where to place different redstone style buildings, and tested by generating cities on random maps in limited time. Experimental results show that the heuristic-based algorithm is capable of finding an acceptable building layout faster for flat maps, while the evolving layout algorithm performs better in evolving layout for rugged maps. A user study is conducted to compare our generator with outstanding entries of the competition's 2022 edition using the competition's evaluation criteria and shows that our generator performs well in the adaptation and functionality criteria
Lazy Visual Localization via Motion Averaging
Jul 19, 2023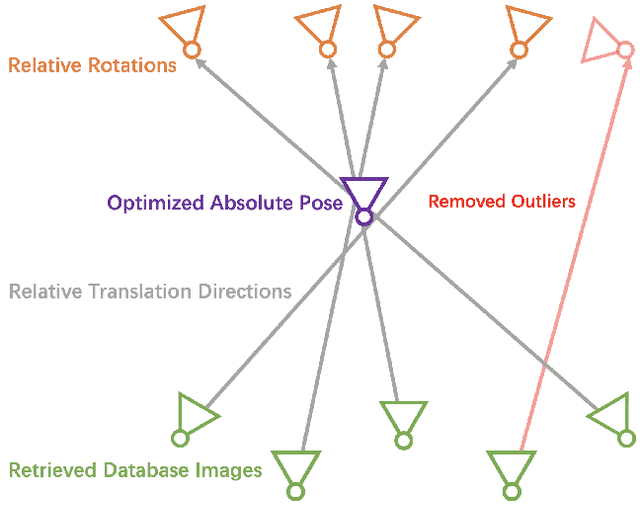
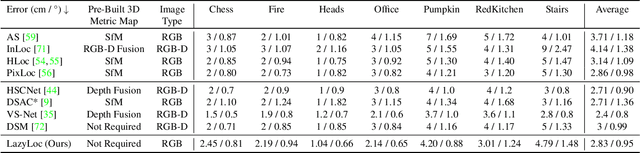
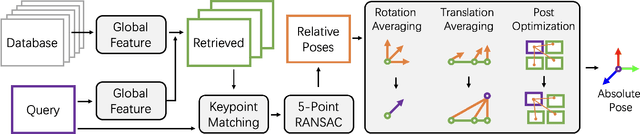
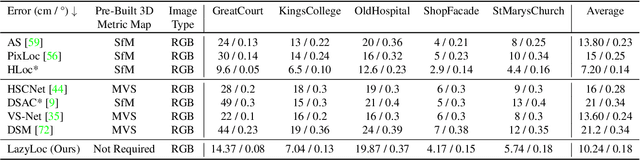
Visual (re)localization is critical for various applications in computer vision and robotics. Its goal is to estimate the 6 degrees of freedom (DoF) camera pose for each query image, based on a set of posed database images. Currently, all leading solutions are structure-based that either explicitly construct 3D metric maps from the database with structure-from-motion, or implicitly encode the 3D information with scene coordinate regression models. On the contrary, visual localization without reconstructing the scene in 3D offers clear benefits. It makes deployment more convenient by reducing database pre-processing time, releasing storage requirements, and remaining unaffected by imperfect reconstruction, etc. In this technical report, we demonstrate that it is possible to achieve high localization accuracy without reconstructing the scene from the database. The key to achieving this owes to a tailored motion averaging over database-query pairs. Experiments show that our visual localization proposal, LazyLoc, achieves comparable performance against state-of-the-art structure-based methods. Furthermore, we showcase the versatility of LazyLoc, which can be easily extended to handle complex configurations such as multi-query co-localization and camera rigs.
Online Continual Learning for Robust Indoor Object Recognition
Jul 19, 2023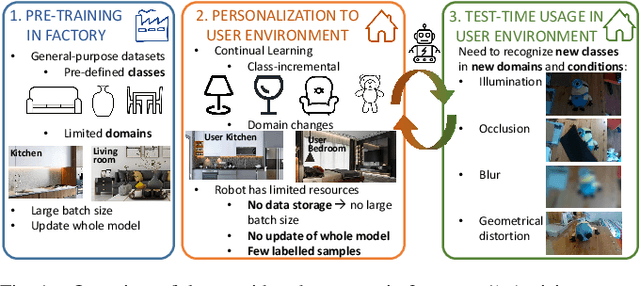
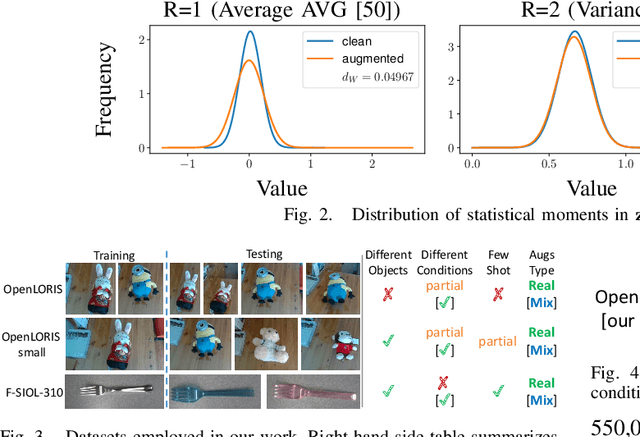
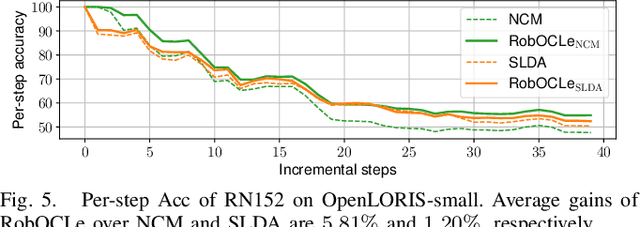
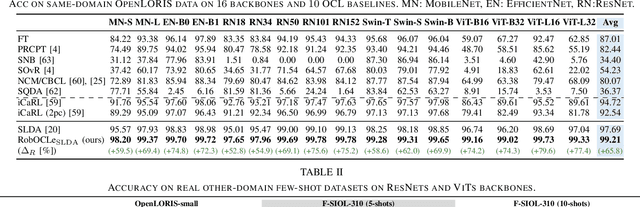
Vision systems mounted on home robots need to interact with unseen classes in changing environments. Robots have limited computational resources, labelled data and storage capability. These requirements pose some unique challenges: models should adapt without forgetting past knowledge in a data- and parameter-efficient way. We characterize the problem as few-shot (FS) online continual learning (OCL), where robotic agents learn from a non-repeated stream of few-shot data updating only a few model parameters. Additionally, such models experience variable conditions at test time, where objects may appear in different poses (e.g., horizontal or vertical) and environments (e.g., day or night). To improve robustness of CL agents, we propose RobOCLe, which; 1) constructs an enriched feature space computing high order statistical moments from the embedded features of samples; and 2) computes similarity between high order statistics of the samples on the enriched feature space, and predicts their class labels. We evaluate robustness of CL models to train/test augmentations in various cases. We show that different moments allow RobOCLe to capture different properties of deformations, providing higher robustness with no decrease of inference speed.
Information Retrieval Meets Large Language Models: A Strategic Report from Chinese IR Community
Jul 19, 2023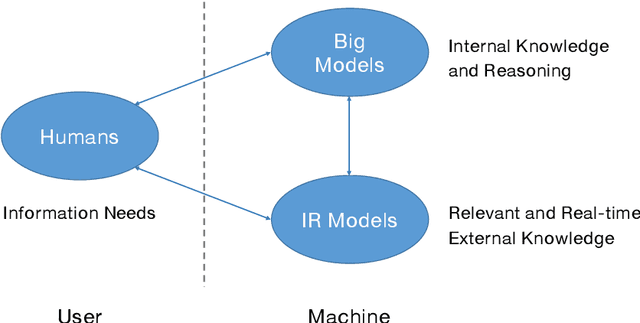
The research field of Information Retrieval (IR) has evolved significantly, expanding beyond traditional search to meet diverse user information needs. Recently, Large Language Models (LLMs) have demonstrated exceptional capabilities in text understanding, generation, and knowledge inference, opening up exciting avenues for IR research. LLMs not only facilitate generative retrieval but also offer improved solutions for user understanding, model evaluation, and user-system interactions. More importantly, the synergistic relationship among IR models, LLMs, and humans forms a new technical paradigm that is more powerful for information seeking. IR models provide real-time and relevant information, LLMs contribute internal knowledge, and humans play a central role of demanders and evaluators to the reliability of information services. Nevertheless, significant challenges exist, including computational costs, credibility concerns, domain-specific limitations, and ethical considerations. To thoroughly discuss the transformative impact of LLMs on IR research, the Chinese IR community conducted a strategic workshop in April 2023, yielding valuable insights. This paper provides a summary of the workshop's outcomes, including the rethinking of IR's core values, the mutual enhancement of LLMs and IR, the proposal of a novel IR technical paradigm, and open challenges.
Technical Challenges of Deploying Reinforcement Learning Agents for Game Testing in AAA Games
Jul 19, 2023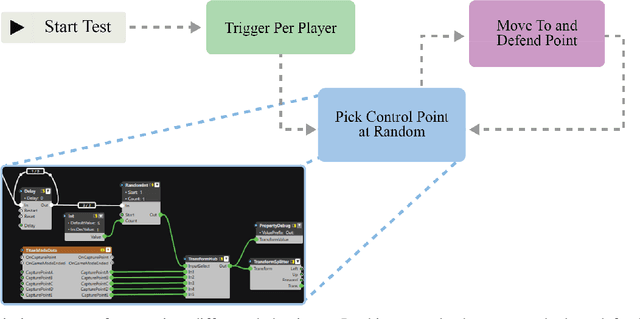
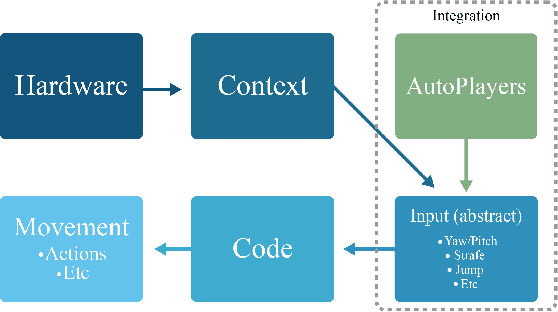


Going from research to production, especially for large and complex software systems, is fundamentally a hard problem. In large-scale game production, one of the main reasons is that the development environment can be very different from the final product. In this technical paper we describe an effort to add an experimental reinforcement learning system to an existing automated game testing solution based on scripted bots in order to increase its capacity. We report on how this reinforcement learning system was integrated with the aim to increase test coverage similar to [1] in a set of AAA games including Battlefield 2042 and Dead Space (2023). The aim of this technical paper is to show a use-case of leveraging reinforcement learning in game production and cover some of the largest time sinks anyone who wants to make the same journey for their game may encounter. Furthermore, to help the game industry to adopt this technology faster, we propose a few research directions that we believe will be valuable and necessary for making machine learning, and especially reinforcement learning, an effective tool in game production.
From West to East: Who can understand the music of the others better?
Jul 19, 2023Recent developments in MIR have led to several benchmark deep learning models whose embeddings can be used for a variety of downstream tasks. At the same time, the vast majority of these models have been trained on Western pop/rock music and related styles. This leads to research questions on whether these models can be used to learn representations for different music cultures and styles, or whether we can build similar music audio embedding models trained on data from different cultures or styles. To that end, we leverage transfer learning methods to derive insights about the similarities between the different music cultures to which the data belongs to. We use two Western music datasets, two traditional/folk datasets coming from eastern Mediterranean cultures, and two datasets belonging to Indian art music. Three deep audio embedding models are trained and transferred across domains, including two CNN-based and a Transformer-based architecture, to perform auto-tagging for each target domain dataset. Experimental results show that competitive performance is achieved in all domains via transfer learning, while the best source dataset varies for each music culture. The implementation and the trained models are both provided in a public repository.
Contextual Reliability: When Different Features Matter in Different Contexts
Jul 19, 2023
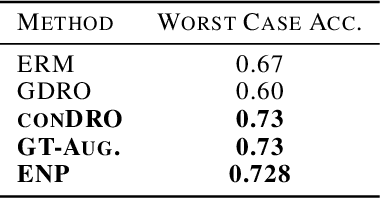
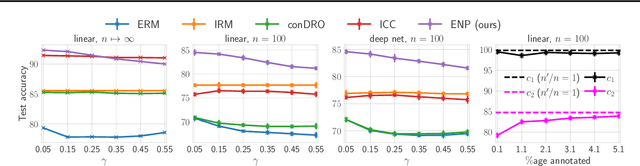

Deep neural networks often fail catastrophically by relying on spurious correlations. Most prior work assumes a clear dichotomy into spurious and reliable features; however, this is often unrealistic. For example, most of the time we do not want an autonomous car to simply copy the speed of surrounding cars -- we don't want our car to run a red light if a neighboring car does so. However, we cannot simply enforce invariance to next-lane speed, since it could provide valuable information about an unobservable pedestrian at a crosswalk. Thus, universally ignoring features that are sometimes (but not always) reliable can lead to non-robust performance. We formalize a new setting called contextual reliability which accounts for the fact that the "right" features to use may vary depending on the context. We propose and analyze a two-stage framework called Explicit Non-spurious feature Prediction (ENP) which first identifies the relevant features to use for a given context, then trains a model to rely exclusively on these features. Our work theoretically and empirically demonstrates the advantages of ENP over existing methods and provides new benchmarks for contextual reliability.