 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
LMT: Longitudinal Mixing Training, a Framework to Predict Disease Progression from a Single Image
Oct 16, 2023
Longitudinal imaging is able to capture both static anatomical structures and dynamic changes in disease progression toward earlier and better patient-specific pathology management. However, conventional approaches rarely take advantage of longitudinal information for detection and prediction purposes, especially for Diabetic Retinopathy (DR). In the past years, Mix-up training and pretext tasks with longitudinal context have effectively enhanced DR classification results and captured disease progression. In the meantime, a novel type of neural network named Neural Ordinary Differential Equation (NODE) has been proposed for solving ordinary differential equations, with a neural network treated as a black box. By definition, NODE is well suited for solving time-related problems. In this paper, we propose to combine these three aspects to detect and predict DR progression. Our framework, Longitudinal Mixing Training (LMT), can be considered both as a regularizer and as a pretext task that encodes the disease progression in the latent space. Additionally, we evaluate the trained model weights on a downstream task with a longitudinal context using standard and longitudinal pretext tasks. We introduce a new way to train time-aware models using $t_{mix}$, a weighted average time between two consecutive examinations. We compare our approach to standard mixing training on DR classification using OPHDIAT a longitudinal retinal Color Fundus Photographs (CFP) dataset. We were able to predict whether an eye would develop a severe DR in the following visit using a single image, with an AUC of 0.798 compared to baseline results of 0.641. Our results indicate that our longitudinal pretext task can learn the progression of DR disease and that introducing $t_{mix}$ augmentation is beneficial for time-aware models.
Contextual Emotion Estimation from Image Captions
Sep 22, 2023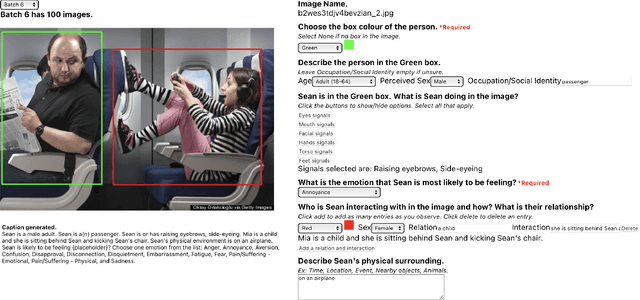

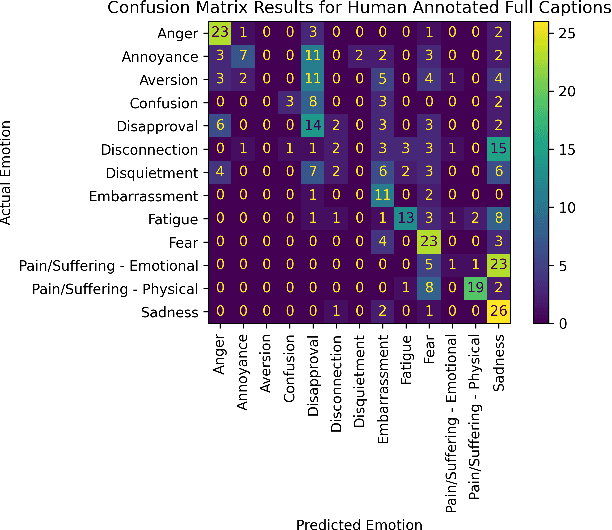
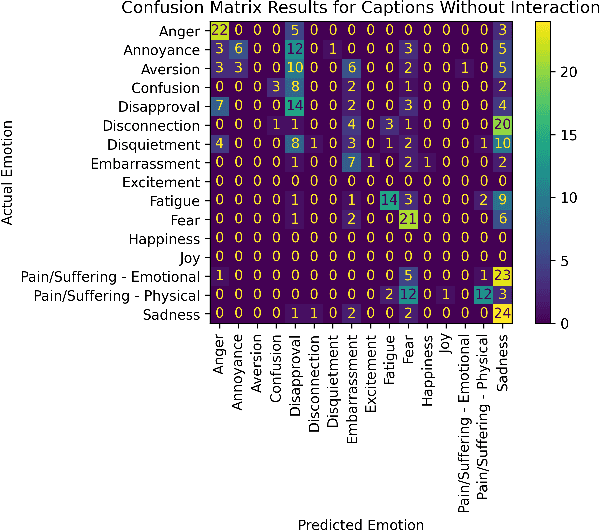
Emotion estimation in images is a challenging task, typically using computer vision methods to directly estimate people's emotions using face, body pose and contextual cues. In this paper, we explore whether Large Language Models (LLMs) can support the contextual emotion estimation task, by first captioning images, then using an LLM for inference. First, we must understand: how well do LLMs perceive human emotions? And which parts of the information enable them to determine emotions? One initial challenge is to construct a caption that describes a person within a scene with information relevant for emotion perception. Towards this goal, we propose a set of natural language descriptors for faces, bodies, interactions, and environments. We use them to manually generate captions and emotion annotations for a subset of 331 images from the EMOTIC dataset. These captions offer an interpretable representation for emotion estimation, towards understanding how elements of a scene affect emotion perception in LLMs and beyond. Secondly, we test the capability of a large language model to infer an emotion from the resulting image captions. We find that GPT-3.5, specifically the text-davinci-003 model, provides surprisingly reasonable emotion predictions consistent with human annotations, but accuracy can depend on the emotion concept. Overall, the results suggest promise in the image captioning and LLM approach.
SPHINX: The Joint Mixing of Weights, Tasks, and Visual Embeddings for Multi-modal Large Language Models
Nov 13, 2023We present SPHINX, a versatile multi-modal large language model (MLLM) with a joint mixing of model weights, tuning tasks, and visual embeddings. First, for stronger vision-language alignment, we unfreeze the large language model (LLM) during pre-training, and introduce a weight mix strategy between LLMs trained by real-world and synthetic data. By directly integrating the weights from two domains, the mixed LLM can efficiently incorporate diverse semantics with favorable robustness. Then, to enable multi-purpose capabilities, we mix a variety of tasks for joint visual instruction tuning, and design task-specific instructions to avoid inter-task conflict. In addition to the basic visual question answering, we include more challenging tasks such as region-level understanding, caption grounding, document layout detection, and human pose estimation, contributing to mutual enhancement over different scenarios. Additionally, we propose to extract comprehensive visual embeddings from various network architectures, pre-training paradigms, and information granularity, providing language models with more robust image representations. Based on our proposed joint mixing, SPHINX exhibits superior multi-modal understanding capabilities on a wide range of applications. On top of this, we further propose an efficient strategy aiming to better capture fine-grained appearances of high-resolution images. With a mixing of different scales and high-resolution sub-images, SPHINX attains exceptional visual parsing and reasoning performance on existing evaluation benchmarks. We hope our work may cast a light on the exploration of joint mixing in future MLLM research. Code is released at https://github.com/Alpha-VLLM/LLaMA2-Accessory.
GPT-4V(ision) as A Social Media Analysis Engine
Nov 13, 2023Recent research has offered insights into the extraordinary capabilities of Large Multimodal Models (LMMs) in various general vision and language tasks. There is growing interest in how LMMs perform in more specialized domains. Social media content, inherently multimodal, blends text, images, videos, and sometimes audio. Understanding social multimedia content remains a challenging problem for contemporary machine learning frameworks. In this paper, we explore GPT-4V(ision)'s capabilities for social multimedia analysis. We select five representative tasks, including sentiment analysis, hate speech detection, fake news identification, demographic inference, and political ideology detection, to evaluate GPT-4V. Our investigation begins with a preliminary quantitative analysis for each task using existing benchmark datasets, followed by a careful review of the results and a selection of qualitative samples that illustrate GPT-4V's potential in understanding multimodal social media content. GPT-4V demonstrates remarkable efficacy in these tasks, showcasing strengths such as joint understanding of image-text pairs, contextual and cultural awareness, and extensive commonsense knowledge. Despite the overall impressive capacity of GPT-4V in the social media domain, there remain notable challenges. GPT-4V struggles with tasks involving multilingual social multimedia comprehension and has difficulties in generalizing to the latest trends in social media. Additionally, it exhibits a tendency to generate erroneous information in the context of evolving celebrity and politician knowledge, reflecting the known hallucination problem. The insights gleaned from our findings underscore a promising future for LMMs in enhancing our comprehension of social media content and its users through the analysis of multimodal information.
The Development of LLMs for Embodied Navigation
Nov 10, 2023In recent years, the rapid advancement of Large Language Models (LLMs) such as the Generative Pre-trained Transformer (GPT) has attracted increasing attention due to their potential in a variety of practical applications. The application of LLMs with Embodied Intelligence has emerged as a significant area of focus. Among the myriad applications of LLMs, navigation tasks are particularly noteworthy because they demand a deep understanding of the environment and quick, accurate decision-making. LLMs can augment embodied intelligence systems with sophisticated environmental perception and decision-making support, leveraging their robust language and image-processing capabilities. This article offers an exhaustive summary of the symbiosis between LLMs and embodied intelligence with a focus on navigation. It reviews state-of-the-art models, research methodologies, and assesses the advantages and disadvantages of existing embodied navigation models and datasets. Finally, the article elucidates the role of LLMs in embodied intelligence, based on current research, and forecasts future directions in the field. A comprehensive list of studies in this survey is available at https://github.com/Rongtao-Xu/Awesome-LLM-EN
Instant3D: Fast Text-to-3D with Sparse-View Generation and Large Reconstruction Model
Nov 10, 2023

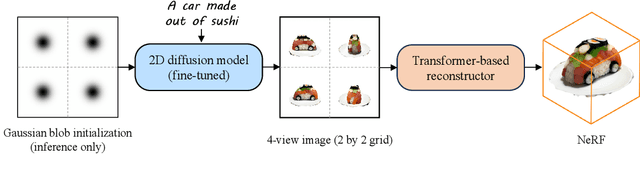
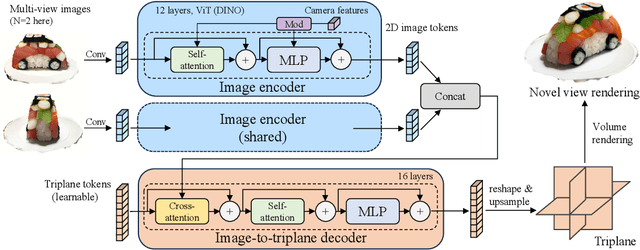
Text-to-3D with diffusion models have achieved remarkable progress in recent years. However, existing methods either rely on score distillation-based optimization which suffer from slow inference, low diversity and Janus problems, or are feed-forward methods that generate low quality results due to the scarcity of 3D training data. In this paper, we propose Instant3D, a novel method that generates high-quality and diverse 3D assets from text prompts in a feed-forward manner. We adopt a two-stage paradigm, which first generates a sparse set of four structured and consistent views from text in one shot with a fine-tuned 2D text-to-image diffusion model, and then directly regresses the NeRF from the generated images with a novel transformer-based sparse-view reconstructor. Through extensive experiments, we demonstrate that our method can generate high-quality, diverse and Janus-free 3D assets within 20 seconds, which is two order of magnitude faster than previous optimization-based methods that can take 1 to 10 hours. Our project webpage: https://jiahao.ai/instant3d/.
TacIPC: Intersection- and Inversion-free FEM-based Elastomer Simulation For Optical Tactile Sensors
Nov 10, 2023Tactile perception stands as a critical sensory modality for human interaction with the environment. Among various tactile sensor techniques, optical sensor-based approaches have gained traction, notably for producing high-resolution tactile images. This work explores gel elastomer deformation simulation through a physics-based approach. While previous works in this direction usually adopt the explicit material point method (MPM), which has certain limitations in force simulation and rendering, we adopt the finite element method (FEM) and address the challenges in penetration and mesh distortion with incremental potential contact (IPC) method. As a result, we present a simulator named TacIPC, which can ensure numerically stable simulations while accommodating direct rendering and friction modeling. To evaluate TacIPC, we conduct three tasks: pseudo-image quality assessment, deformed geometry estimation, and marker displacement prediction. These tasks show its superior efficacy in reducing the sim-to-real gap. Our method can also seamlessly integrate with existing simulators. More experiments and videos can be found in the supplementary materials and on the website: https://sites.google.com/view/tac-ipc.
Parameter-Efficient Orthogonal Finetuning via Butterfly Factorization
Nov 10, 2023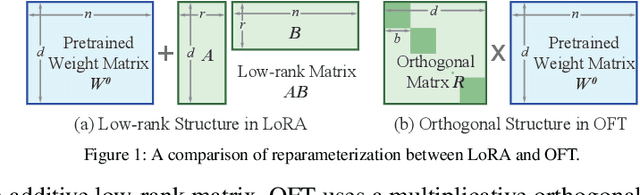
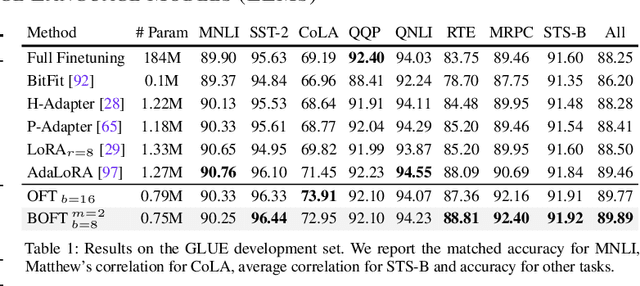
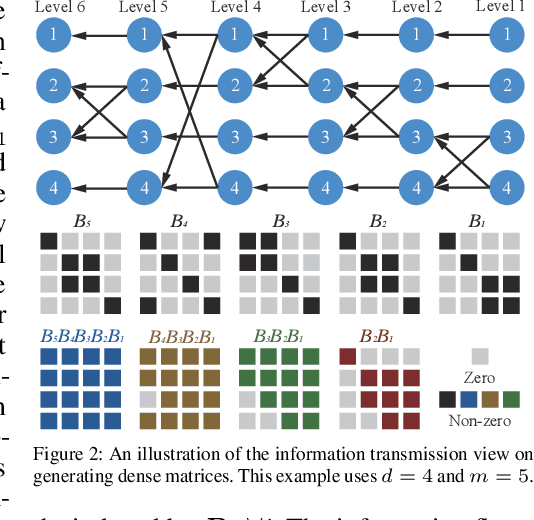
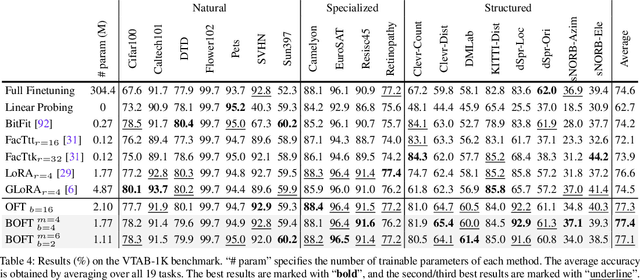
Large foundation models are becoming ubiquitous, but training them from scratch is prohibitively expensive. Thus, efficiently adapting these powerful models to downstream tasks is increasingly important. In this paper, we study a principled finetuning paradigm -- Orthogonal Finetuning (OFT) -- for downstream task adaptation. Despite demonstrating good generalizability, OFT still uses a fairly large number of trainable parameters due to the high dimensionality of orthogonal matrices. To address this, we start by examining OFT from an information transmission perspective, and then identify a few key desiderata that enable better parameter-efficiency. Inspired by how the Cooley-Tukey fast Fourier transform algorithm enables efficient information transmission, we propose an efficient orthogonal parameterization using butterfly structures. We apply this parameterization to OFT, creating a novel parameter-efficient finetuning method, called Orthogonal Butterfly (BOFT). By subsuming OFT as a special case, BOFT introduces a generalized orthogonal finetuning framework. Finally, we conduct an extensive empirical study of adapting large vision transformers, large language models, and text-to-image diffusion models to various downstream tasks in vision and language.
Florence-2: Advancing a Unified Representation for a Variety of Vision Tasks
Nov 10, 2023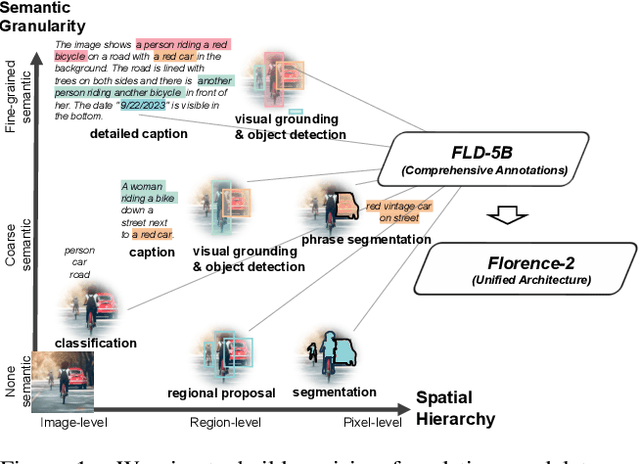
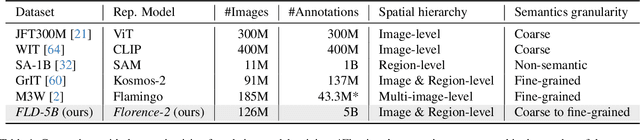
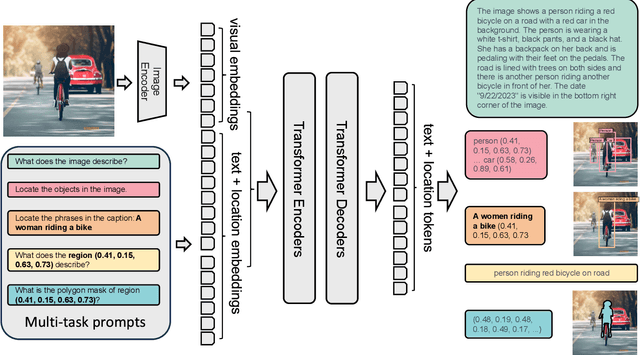
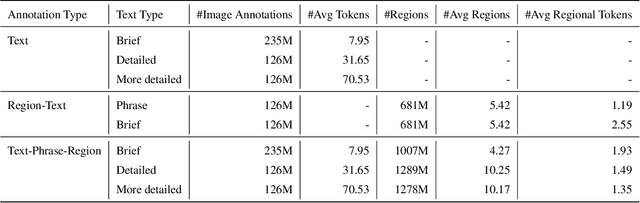
We introduce Florence-2, a novel vision foundation model with a unified, prompt-based representation for a variety of computer vision and vision-language tasks. While existing large vision models excel in transfer learning, they struggle to perform a diversity of tasks with simple instructions, a capability that implies handling the complexity of various spatial hierarchy and semantic granularity. Florence-2 was designed to take text-prompt as task instructions and generate desirable results in text forms, whether it be captioning, object detection, grounding or segmentation. This multi-task learning setup demands large-scale, high-quality annotated data. To this end, we co-developed FLD-5B that consists of 5.4 billion comprehensive visual annotations on 126 million images, using an iterative strategy of automated image annotation and model refinement. We adopted a sequence-to-sequence structure to train Florence-2 to perform versatile and comprehensive vision tasks. Extensive evaluations on numerous tasks demonstrated Florence-2 to be a strong vision foundation model contender with unprecedented zero-shot and fine-tuning capabilities.
GCS-ICHNet: Assessment of Intracerebral Hemorrhage Prognosis using Self-Attention with Domain Knowledge Integration
Nov 08, 2023Intracerebral Hemorrhage (ICH) is a severe condition resulting from damaged brain blood vessel ruptures, often leading to complications and fatalities. Timely and accurate prognosis and management are essential due to its high mortality rate. However, conventional methods heavily rely on subjective clinician expertise, which can lead to inaccurate diagnoses and delays in treatment. Artificial intelligence (AI) models have been explored to assist clinicians, but many prior studies focused on model modification without considering domain knowledge. This paper introduces a novel deep learning algorithm, GCS-ICHNet, which integrates multimodal brain CT image data and the Glasgow Coma Scale (GCS) score to improve ICH prognosis. The algorithm utilizes a transformer-based fusion module for assessment. GCS-ICHNet demonstrates high sensitivity 81.03% and specificity 91.59%, outperforming average clinicians and other state-of-the-art methods.