 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRigPI: Dynamic Parameter Identification of Rigid Body via VLM-Seeded Differentiable Simulation
Jun 25, 2026Accurate physical parameter identification of manipulated objects is fundamental to advanced robotic manipulation and the construction of faithful digital twins. However, acquiring physically consistent inertial and frictional properties from real-world interactions remains challenging due to sensing noise, modeling errors, and limited prior knowledge. This paper presents RigPI, a systematic framework for identifying dynamic parameters of both unconstrained rigid bodies and multi-link rigid bodies during robot-object interaction. RigPI integrates vision-based semantic priors, force-torque measurements, and motion observations within a differentiable simulation pipeline. A vision-language model (VLM) provides informed initialization and a constrained search space, while gradient information from a differentiable physics simulator enables efficient and stable parameter refinement. The proposed two-stage optimization strategy alleviates sensitivity to noise and avoids physically implausible solutions. Extensive real-world experiments on objects with revolute and prismatic joints demonstrate that RigPI achieves accurate and stable parameter estimates, and successfully reproduces manipulation trajectories on a real robot with parameter-aware predictive validity. These results highlight the effectiveness and robustness of RigPI for real-world robotic system identification tasks.
Towards Human-Like Manipulation through RL-Augmented Teleoperation and Mixture-of-Dexterous-Experts VLA
Mar 09, 2026While Vision-Language-Action (VLA) models have demonstrated remarkable success in robotic manipulation, their application has largely been confined to low-degree-of-freedom end-effectors performing simple, vision-guided pick-and-place tasks. Extending these models to human-like, bimanual dexterous manipulation-specifically contact-rich in-hand operations-introduces critical challenges in high-fidelity data acquisition, multi-skill learning, and multimodal sensory fusion. In this paper, we propose an integrated framework to address these bottlenecks, built upon two components. First, we introduce IMCopilot (In-hand Manipulation Copilot), a suite of reinforcement learning-trained atomic skills that plays a dual role: it acts as a shared-autonomy assistant to simplify teleoperation data collection, and it serves as a callable low-level execution primitive for the VLA. Second, we present MoDE-VLA (Mixture-of-Dexterous-Experts VLA), an architecture that seamlessly integrates heterogeneous force and tactile modalities into a pretrained VLA backbone. By utilizing a residual injection mechanism, MoDE-VLA enables contact-aware refinement without degrading the model's pretrained knowledge. We validate our approach on four tasks of escalating complexity, demonstrating doubled success rate improvement over the baseline in dexterous contact-rich tasks.
Stereo-Inertial Poser: Towards Metric-Accurate Shape-Aware Motion Capture Using Sparse IMUs and a Single Stereo Camera
Mar 02, 2026Recent advancements in visual-inertial motion capture systems have demonstrated the potential of combining monocular cameras with sparse inertial measurement units (IMUs) as cost-effective solutions, which effectively mitigate occlusion and drift issues inherent in single-modality systems. However, they are still limited by metric inaccuracies in global translations stemming from monocular depth ambiguity, and shape-agnostic local motion estimations that ignore anthropometric variations. We present Stereo-Inertial Poser, a real-time motion capture system that leverages a single stereo camera and six IMUs to estimate metric-accurate and shape-aware 3D human motion. By replacing the monocular RGB with stereo vision, our system resolves depth ambiguity through calibrated baseline geometry, enabling direct 3D keypoint extraction and body shape parameter estimation. IMU data and visual cues are fused for predicting drift-compensated joint positions and root movements, while a novel shape-aware fusion module dynamically harmonizes anthropometry variations with global translations. Our end-to-end pipeline achieves over 200 FPS without optimization-based post-processing, enabling real-time deployment. Quantitative evaluations across various datasets demonstrate state-of-the-art performance. Qualitative results show our method produces drift-free global translation under a long recording time and reduces foot-skating effects.
Equipping Retrieval-Augmented Large Language Models with Document Structure Awareness
Oct 05, 2025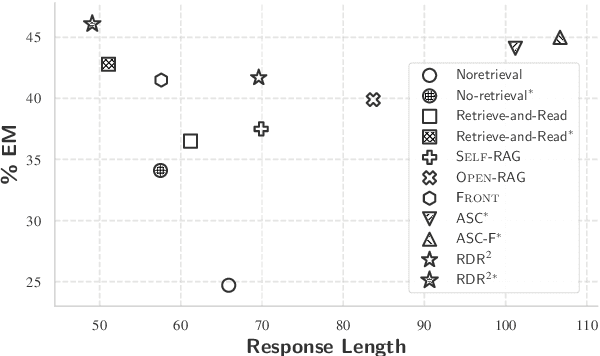
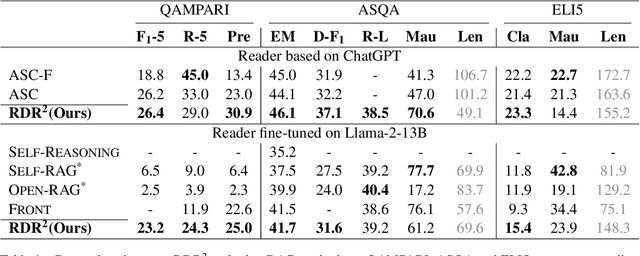
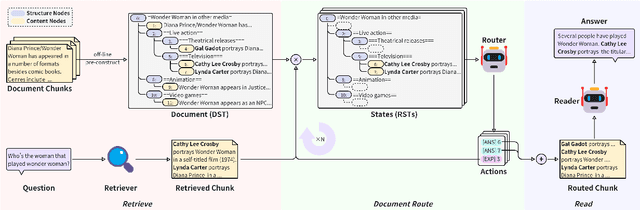
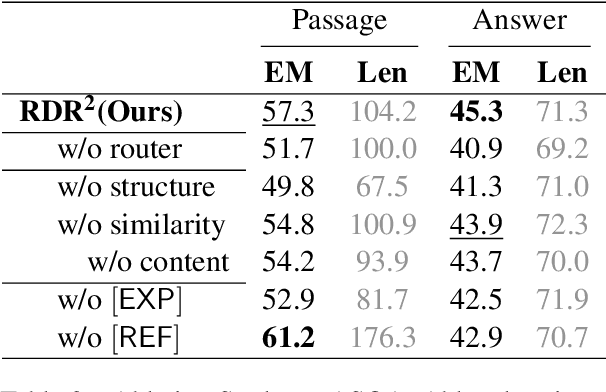
While large language models (LLMs) demonstrate impressive capabilities, their reliance on parametric knowledge often leads to factual inaccuracies. Retrieval-Augmented Generation (RAG) mitigates this by leveraging external documents, yet existing approaches treat retrieved passages as isolated chunks, ignoring valuable structure that is crucial for document organization. Motivated by this gap, we propose Retrieve-DocumentRoute-Read (RDR2), a novel framework that explicitly incorporates structural information throughout the RAG process. RDR2 employs an LLM-based router to dynamically navigate document structure trees, jointly evaluating content relevance and hierarchical relationships to assemble optimal evidence. Our key innovation lies in formulating document routing as a trainable task, with automatic action curation and structure-aware passage selection inspired by human reading strategies. Through comprehensive evaluation on five challenging datasets, RDR2 achieves state-of-the-art performance, demonstrating that explicit structural awareness significantly enhances RAG systems' ability to acquire and utilize knowledge, particularly in complex scenarios requiring multi-document synthesis.
FBI: Learning Dexterous In-hand Manipulation with Dynamic Visuotactile Shortcut Policy
Aug 20, 2025



Dexterous in-hand manipulation is a long-standing challenge in robotics due to complex contact dynamics and partial observability. While humans synergize vision and touch for such tasks, robotic approaches often prioritize one modality, therefore limiting adaptability. This paper introduces Flow Before Imitation (FBI), a visuotactile imitation learning framework that dynamically fuses tactile interactions with visual observations through motion dynamics. Unlike prior static fusion methods, FBI establishes a causal link between tactile signals and object motion via a dynamics-aware latent model. FBI employs a transformer-based interaction module to fuse flow-derived tactile features with visual inputs, training a one-step diffusion policy for real-time execution. Extensive experiments demonstrate that the proposed method outperforms the baseline methods in both simulation and the real world on two customized in-hand manipulation tasks and three standard dexterous manipulation tasks. Code, models, and more results are available in the website https://sites.google.com/view/dex-fbi.
DexTOG: Learning Task-Oriented Dexterous Grasp with Language
Apr 06, 2025This study introduces a novel language-guided diffusion-based learning framework, DexTOG, aimed at advancing the field of task-oriented grasping (TOG) with dexterous hands. Unlike existing methods that mainly focus on 2-finger grippers, this research addresses the complexities of dexterous manipulation, where the system must identify non-unique optimal grasp poses under specific task constraints, cater to multiple valid grasps, and search in a high degree-of-freedom configuration space in grasp planning. The proposed DexTOG includes a diffusion-based grasp pose generation model, DexDiffu, and a data engine to support the DexDiffu. By leveraging DexTOG, we also proposed a new dataset, DexTOG-80K, which was developed using a shadow robot hand to perform various tasks on 80 objects from 5 categories, showcasing the dexterity and multi-tasking capabilities of the robotic hand. This research not only presents a significant leap in dexterous TOG but also provides a comprehensive dataset and simulation validation, setting a new benchmark in robotic manipulation research.
Dynamic Trend Fusion Module for Traffic Flow Prediction
Jan 18, 2025Accurate traffic flow prediction is essential for applications like transport logistics but remains challenging due to complex spatio-temporal correlations and non-linear traffic patterns. Existing methods often model spatial and temporal dependencies separately, failing to effectively fuse them. To overcome this limitation, the Dynamic Spatial-Temporal Trend Transformer DST2former is proposed to capture spatio-temporal correlations through adaptive embedding and to fuse dynamic and static information for learning multi-view dynamic features of traffic networks. The approach employs the Dynamic Trend Representation Transformer (DTRformer) to generate dynamic trends using encoders for both temporal and spatial dimensions, fused via Cross Spatial-Temporal Attention. Predefined graphs are compressed into a representation graph to extract static attributes and reduce redundancy. Experiments on four real-world traffic datasets demonstrate that our framework achieves state-of-the-art performance.
Point Cloud Resampling with Learnable Heat Diffusion
Nov 21, 2024Generative diffusion models have shown empirical successes in point cloud resampling, generating a denser and more uniform distribution of points from sparse or noisy 3D point clouds by progressively refining noise into structure. However, existing diffusion models employ manually predefined schemes, which often fail to recover the underlying point cloud structure due to the rigid and disruptive nature of the geometric degradation. To address this issue, we propose a novel learnable heat diffusion framework for point cloud resampling, which directly parameterizes the marginal distribution for the forward process by learning the adaptive heat diffusion schedules and local filtering scales of the time-varying heat kernel, and consequently, generates an adaptive conditional prior for the reverse process. Unlike previous diffusion models with a fixed prior, the adaptive conditional prior selectively preserves geometric features of the point cloud by minimizing a refined variational lower bound, guiding the points to evolve towards the underlying surface during the reverse process. Extensive experimental results demonstrate that the proposed point cloud resampling achieves state-of-the-art performance in representative reconstruction tasks including point cloud denoising and upsampling.
Point Cloud Denoising With Fine-Granularity Dynamic Graph Convolutional Networks
Nov 21, 2024Due to limitations in acquisition equipment, noise perturbations often corrupt 3-D point clouds, hindering down-stream tasks such as surface reconstruction, rendering, and further processing. Existing 3-D point cloud denoising methods typically fail to reliably fit the underlying continuous surface, resulting in a degradation of reconstruction performance. This paper introduces fine-granularity dynamic graph convolutional networks called GD-GCN, a novel approach to denoising in 3-D point clouds. The GD-GCN employs micro-step temporal graph convolution (MST-GConv) to perform feature learning in a gradual manner. Compared with the conventional GCN, which commonly uses discrete integer-step graph convolution, this modification introduces a more adaptable and nuanced approach to feature learning within graph convolution networks. It more accurately depicts the process of fitting the point cloud with noise to the underlying surface by and the learning process for MST-GConv acts like a changing system and is managed through a type of neural network known as neural Partial Differential Equations (PDEs). This means it can adapt and improve over time. GD-GCN approximates the Riemannian metric, calculating distances between points along a low-dimensional manifold. This capability allows it to understand the local geometric structure and effectively capture diverse relationships between points from different geometric regions through geometric graph construction based on Riemannian distances. Additionally, GD-GCN incorporates robust graph spectral filters based on the Bernstein polynomial approximation, which modulate eigenvalues for complex and arbitrary spectral responses, providing theoretical guarantees for BIBO stability. Symmetric channel mixing matrices further enhance filter flexibility by enabling channel-level scaling and shifting in the spectral domain.
Dynamic Reconstruction of Hand-Object Interaction with Distributed Force-aware Contact Representation
Nov 14, 2024



We present ViTaM-D, a novel visual-tactile framework for dynamic hand-object interaction reconstruction, integrating distributed tactile sensing for more accurate contact modeling. While existing methods focus primarily on visual inputs, they struggle with capturing detailed contact interactions such as object deformation. Our approach leverages distributed tactile sensors to address this limitation by introducing DF-Field. This distributed force-aware contact representation models both kinetic and potential energy in hand-object interaction. ViTaM-D first reconstructs hand-object interactions using a visual-only network, VDT-Net, and then refines contact details through a force-aware optimization (FO) process, enhancing object deformation modeling. To benchmark our approach, we introduce the HOT dataset, which features 600 sequences of hand-object interactions, including deformable objects, built in a high-precision simulation environment. Extensive experiments on both the DexYCB and HOT datasets demonstrate significant improvements in accuracy over previous state-of-the-art methods such as gSDF and HOTrack. Our results highlight the superior performance of ViTaM-D in both rigid and deformable object reconstruction, as well as the effectiveness of DF-Field in refining hand poses. This work offers a comprehensive solution to dynamic hand-object interaction reconstruction by seamlessly integrating visual and tactile data. Codes, models, and datasets will be available.