 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorldMemArena: Evaluating Multimodal Agent Memory Through Action-World Interaction
May 28, 2026Multimodal large language models are increasingly deployed as long-horizon agents, where memory must do more than recall: it must track an evolving world, revise what has gone stale, and surface the right evidence at decision time. Existing benchmarks measure recall over static dialogue, collapse memory into a single end-of-task accuracy, and reduce visual observations to captions, leaving us unable to localize failures to writing, maintenance, retrieval, or use. The rise of agent harnesses that author their own memory sharpens this gap, since we have no principled way to compare hand-designed pipelines with self-managing alternatives. To close these gaps, we formulate multimodal agent memory as an Action-World Interaction Loop with an observable four-stage lifecycle, and instantiate it in WorldMemArena: 400 multi-session multimodal tasks spanning Lifelong Evolution (evolving personal and task states) and Agentic Execution (memory from real observations, actions, and feedback), annotated with gold memory points, updates, distractors, and evidence chains for stage-level diagnosis. This enables the first head-to-head comparison of long-context, manually designed (RAG and external memory systems), and harness-based memory agents. Results show that: (1) better memory writing and storage do not guarantee better performance; (2) multimodal memory still struggles to fully use visual evidence; (3) systems are unstable across domains and degrade on realistic agentic trajectories; and (4) harness memory is more flexible but remains costly and less reliable.
Sensor2Sensor: Cross-Embodiment Sensor Conversion for Autonomous Driving
May 21, 2026Robust training and validation of Autonomous Driving Systems (ADS) require massive, diverse datasets. Proprietary data collected by Autonomous Vehicle (AV) fleets, while high-fidelity, are limited in scale, diversity of sensor configurations, as well as geographic and long-tail-behavioral coverage. In contrast, in-the-wild data from sources like dashcams offers immense scale and diversity, capturing critical long-tail scenarios and novel environments. However, this unstructured, in-the-wild video data is incompatible with ADS expecting structured, multi-modal sensor inputs for validation and training. To bridge this data gap, we propose Sensor2Sensor, a novel generative modeling paradigm that translates in-the-wild monocular dashcam videos into a high-fidelity, multi-modal sensor suite (AV logs) comprising multi-view camera images and LiDAR point clouds. A core challenge is the lack of paired training data. We address this by converting real AV logs into dashcam-style videos via 4D Gaussian Splatting (4DGS) reconstruction and novel-view rendering. Sensor2Sensor then utilizes a diffusion architecture to perform the generative conversion. We perform comprehensive quantitative evaluations on the fidelity and realism of the generated sensor data. We demonstrate Sensor2Sensor's practical utility by converting challenging in-the-wild internet and dashcam footage into realistic, multi-modal data formats, further unlocking vast external data sources for AV development.
GeoFlow: Enforcing Implicit Geometric Consistency in Video Generation
May 18, 2026Generating geometrically consistent videos remains an open challenge: text-to-video diffusion models trained on web-scale data treat geometry only implicitly, leading to object deformation, texture drift, and non-rigid backgrounds under camera motion. Existing solutions either improve consistency as a byproduct, apply only to static scenes or realign the latent space of the model completely. We introduce a geometry-consistency reward that directly measures whether motion in a generated video is compatible with a coherent scene. Our key insight is that in physically consistent videos, background motion should be explainable by rigid camera-induced flow, while independently moving objects should preserve appearance identity along motion trajectories. We operationalize this using optical flow, depth--pose predictions, and feature-based correspondence to separate rigid and dynamic regions and evaluate their respective consistency. Integrating this reward with reinforcement fine-tuning transforms geometric consistency from an emergent property into an explicit optimization objective for video generators. The approach is model agnostic and applies to diverse dynamic scenes containing both camera and object motion. Experiments show substantial reductions in temporal geometric artifacts over strong baselines while preserving perceptual quality. Code and model weights are published.
Image Generators are Generalist Vision Learners
Apr 22, 2026Recent works show that image and video generators exhibit zero-shot visual understanding behaviors, in a way reminiscent of how LLMs develop emergent capabilities of language understanding and reasoning from generative pretraining. While it has long been conjectured that the ability to create visual content implies an ability to understand it, there has been limited evidence that generative vision models have developed strong understanding capabilities. In this work, we demonstrate that image generation training serves a role similar to LLM pretraining, and lets models learn powerful and general visual representations that enable SOTA performance on various vision tasks. We introduce Vision Banana, a generalist model built by instruction-tuning Nano Banana Pro (NBP) on a mixture of its original training data alongside a small amount of vision task data. By parameterizing the output space of vision tasks as RGB images, we seamlessly reframe perception as image generation. Our generalist model, Vision Banana, achieves SOTA results on a variety of vision tasks involving both 2D and 3D understanding, beating or rivaling zero-shot domain-specialists, including Segment Anything Model 3 on segmentation tasks, and the Depth Anything series on metric depth estimation. We show that these results can be achieved with lightweight instruction-tuning without sacrificing the base model's image generation capabilities. The superior results suggest that image generation pretraining is a generalist vision learner. It also shows that image generation serves as a unified and universal interface for vision tasks, similar to text generation's role in language understanding and reasoning. We could be witnessing a major paradigm shift for computer vision, where generative vision pretraining takes a central role in building Foundational Vision Models for both generation and understanding.
CityRAG: Stepping Into a City via Spatially-Grounded Video Generation
Apr 21, 2026We address the problem of generating a 3D-consistent, navigable environment that is spatially grounded: a simulation of a real location. Existing video generative models can produce a plausible sequence that is consistent with a text (T2V) or image (I2V) prompt. However, the capability to reconstruct the real world under arbitrary weather conditions and dynamic object configurations is essential for downstream applications including autonomous driving and robotics simulation. To this end, we present CityRAG, a video generative model that leverages large corpora of geo-registered data as context to ground generation to the physical scene, while maintaining learned priors for complex motion and appearance changes. CityRAG relies on temporally unaligned training data, which teaches the model to semantically disentangle the underlying scene from its transient attributes. Our experiments demonstrate that CityRAG can generate coherent minutes-long, physically grounded video sequences, maintain weather and lighting conditions over thousands of frames, achieve loop closure, and navigate complex trajectories to reconstruct real-world geography.
Feed-Forward 3D Scene Modeling: A Problem-Driven Perspective
Apr 15, 2026Reconstructing 3D representations from 2D inputs is a fundamental task in computer vision and graphics, serving as a cornerstone for understanding and interacting with the physical world. While traditional methods achieve high fidelity, they are limited by slow per-scene optimization or category-specific training, which hinders their practical deployment and scalability. Hence, generalizable feed-forward 3D reconstruction has witnessed rapid development in recent years. By learning a model that maps images directly to 3D representations in a single forward pass, these methods enable efficient reconstruction and robust cross-scene generalization. Our survey is motivated by a critical observation: despite the diverse geometric output representations, ranging from implicit fields to explicit primitives, existing feed-forward approaches share similar high-level architectural patterns, such as image feature extraction backbones, multi-view information fusion mechanisms, and geometry-aware design principles. Consequently, we abstract away from these representation differences and instead focus on model design, proposing a novel taxonomy centered on model design strategies that are agnostic to the output format. Our proposed taxonomy organizes the research directions into five key problems that drive recent research development: feature enhancement, geometry awareness, model efficiency, augmentation strategies and temporal-aware models. To support this taxonomy with empirical grounding and standardized evaluation, we further comprehensively review related benchmarks and datasets, and extensively discuss and categorize real-world applications based on feed-forward 3D models. Finally, we outline future directions to address open challenges such as scalability, evaluation standards, and world modeling.
UFO-4D: Unposed Feedforward 4D Reconstruction from Two Images
Mar 05, 2026Dense 4D reconstruction from unposed images remains a critical challenge, with current methods relying on slow test-time optimization or fragmented, task-specific feedforward models. We introduce UFO-4D, a unified feedforward framework to reconstruct a dense, explicit 4D representation from just a pair of unposed images. UFO-4D directly estimates dynamic 3D Gaussian Splats, enabling the joint and consistent estimation of 3D geometry, 3D motion, and camera pose in a feedforward manner. Our core insight is that differentiably rendering multiple signals from a single Dynamic 3D Gaussian representation offers major training advantages. This approach enables a self-supervised image synthesis loss while tightly coupling appearance, depth, and motion. Since all modalities share the same geometric primitives, supervising one inherently regularizes and improves the others. This synergy overcomes data scarcity, allowing UFO-4D to outperform prior work by up to 3 times in joint geometry, motion, and camera pose estimation. Our representation also enables high-fidelity 4D interpolation across novel views and time. Please visit our project page for visual results: https://ufo-4d.github.io/
Selfi: Self Improving Reconstruction Engine via 3D Geometric Feature Alignment
Dec 21, 2025Novel View Synthesis (NVS) has traditionally relied on models with explicit 3D inductive biases combined with known camera parameters from Structure-from-Motion (SfM) beforehand. Recent vision foundation models like VGGT take an orthogonal approach -- 3D knowledge is gained implicitly through training data and loss objectives, enabling feed-forward prediction of both camera parameters and 3D representations directly from a set of uncalibrated images. While flexible, VGGT features lack explicit multi-view geometric consistency, and we find that improving such 3D feature consistency benefits both NVS and pose estimation tasks. We introduce Selfi, a self-improving 3D reconstruction pipeline via feature alignment, transforming a VGGT backbone into a high-fidelity 3D reconstruction engine by leveraging its own outputs as pseudo-ground-truth. Specifically, we train a lightweight feature adapter using a reprojection-based consistency loss, which distills VGGT outputs into a new geometrically-aligned feature space that captures spatial proximity in 3D. This enables state-of-the-art performance in both NVS and camera pose estimation, demonstrating that feature alignment is a highly beneficial step for downstream 3D reasoning.
Splat4D: Diffusion-Enhanced 4D Gaussian Splatting for Temporally and Spatially Consistent Content Creation
Aug 11, 2025Generating high-quality 4D content from monocular videos for applications such as digital humans and AR/VR poses challenges in ensuring temporal and spatial consistency, preserving intricate details, and incorporating user guidance effectively. To overcome these challenges, we introduce Splat4D, a novel framework enabling high-fidelity 4D content generation from a monocular video. Splat4D achieves superior performance while maintaining faithful spatial-temporal coherence by leveraging multi-view rendering, inconsistency identification, a video diffusion model, and an asymmetric U-Net for refinement. Through extensive evaluations on public benchmarks, Splat4D consistently demonstrates state-of-the-art performance across various metrics, underscoring the efficacy of our approach. Additionally, the versatility of Splat4D is validated in various applications such as text/image conditioned 4D generation, 4D human generation, and text-guided content editing, producing coherent outcomes following user instructions.
LODGE: Level-of-Detail Large-Scale Gaussian Splatting with Efficient Rendering
May 29, 2025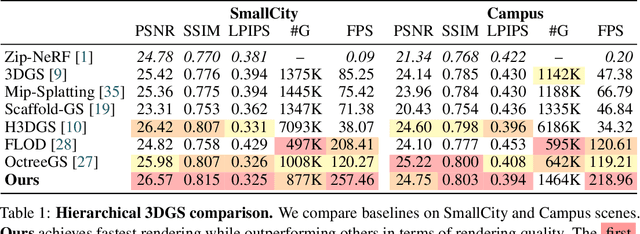
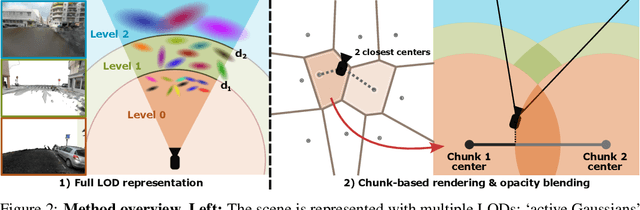
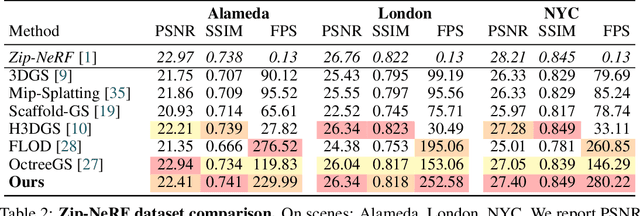
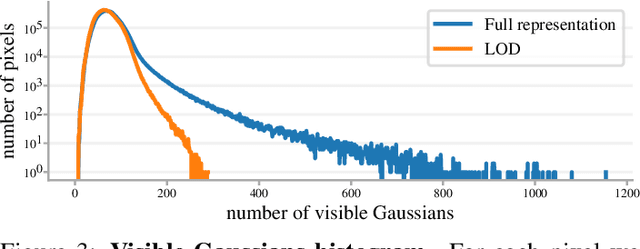
In this work, we present a novel level-of-detail (LOD) method for 3D Gaussian Splatting that enables real-time rendering of large-scale scenes on memory-constrained devices. Our approach introduces a hierarchical LOD representation that iteratively selects optimal subsets of Gaussians based on camera distance, thus largely reducing both rendering time and GPU memory usage. We construct each LOD level by applying a depth-aware 3D smoothing filter, followed by importance-based pruning and fine-tuning to maintain visual fidelity. To further reduce memory overhead, we partition the scene into spatial chunks and dynamically load only relevant Gaussians during rendering, employing an opacity-blending mechanism to avoid visual artifacts at chunk boundaries. Our method achieves state-of-the-art performance on both outdoor (Hierarchical 3DGS) and indoor (Zip-NeRF) datasets, delivering high-quality renderings with reduced latency and memory requirements.