 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlorence-2: Advancing a Unified Representation for a Variety of Vision Tasks
Nov 10, 2023



We introduce Florence-2, a novel vision foundation model with a unified, prompt-based representation for a variety of computer vision and vision-language tasks. While existing large vision models excel in transfer learning, they struggle to perform a diversity of tasks with simple instructions, a capability that implies handling the complexity of various spatial hierarchy and semantic granularity. Florence-2 was designed to take text-prompt as task instructions and generate desirable results in text forms, whether it be captioning, object detection, grounding or segmentation. This multi-task learning setup demands large-scale, high-quality annotated data. To this end, we co-developed FLD-5B that consists of 5.4 billion comprehensive visual annotations on 126 million images, using an iterative strategy of automated image annotation and model refinement. We adopted a sequence-to-sequence structure to train Florence-2 to perform versatile and comprehensive vision tasks. Extensive evaluations on numerous tasks demonstrated Florence-2 to be a strong vision foundation model contender with unprecedented zero-shot and fine-tuning capabilities.
MM-VID: Advancing Video Understanding with GPT-4V
Oct 30, 2023



We present MM-VID, an integrated system that harnesses the capabilities of GPT-4V, combined with specialized tools in vision, audio, and speech, to facilitate advanced video understanding. MM-VID is designed to address the challenges posed by long-form videos and intricate tasks such as reasoning within hour-long content and grasping storylines spanning multiple episodes. MM-VID uses a video-to-script generation with GPT-4V to transcribe multimodal elements into a long textual script. The generated script details character movements, actions, expressions, and dialogues, paving the way for large language models (LLMs) to achieve video understanding. This enables advanced capabilities, including audio description, character identification, and multimodal high-level comprehension. Experimental results demonstrate the effectiveness of MM-VID in handling distinct video genres with various video lengths. Additionally, we showcase its potential when applied to interactive environments, such as video games and graphic user interfaces.
SwinBERT: End-to-End Transformers with Sparse Attention for Video Captioning
Nov 25, 2021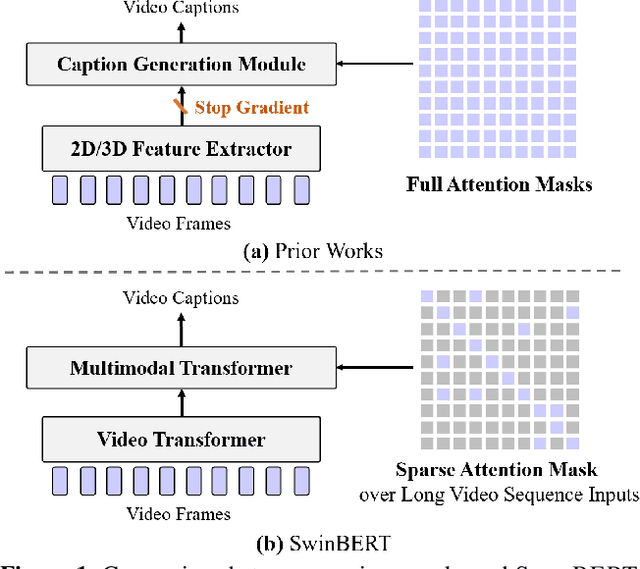

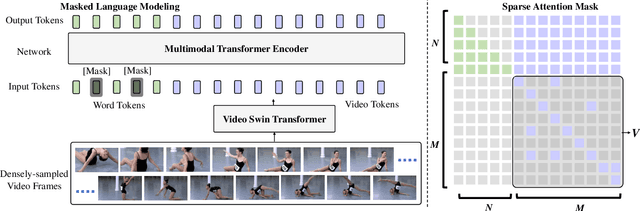
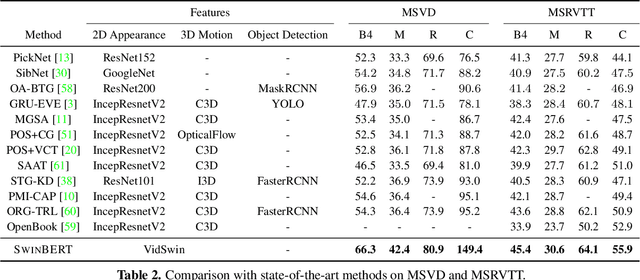
The canonical approach to video captioning dictates a caption generation model to learn from offline-extracted dense video features. These feature extractors usually operate on video frames sampled at a fixed frame rate and are often trained on image/video understanding tasks, without adaption to video captioning data. In this work, we present SwinBERT, an end-to-end transformer-based model for video captioning, which takes video frame patches directly as inputs, and outputs a natural language description. Instead of leveraging multiple 2D/3D feature extractors, our method adopts a video transformer to encode spatial-temporal representations that can adapt to variable lengths of video input without dedicated design for different frame rates. Based on this model architecture, we show that video captioning can benefit significantly from more densely sampled video frames as opposed to previous successes with sparsely sampled video frames for video-and-language understanding tasks (e.g., video question answering). Moreover, to avoid the inherent redundancy in consecutive video frames, we propose adaptively learning a sparse attention mask and optimizing it for task-specific performance improvement through better long-range video sequence modeling. Through extensive experiments on 5 video captioning datasets, we show that SwinBERT achieves across-the-board performance improvements over previous methods, often by a large margin. The learned sparse attention masks in addition push the limit to new state of the arts, and can be transferred between different video lengths and between different datasets.
Scaling Up Vision-Language Pre-training for Image Captioning
Nov 24, 2021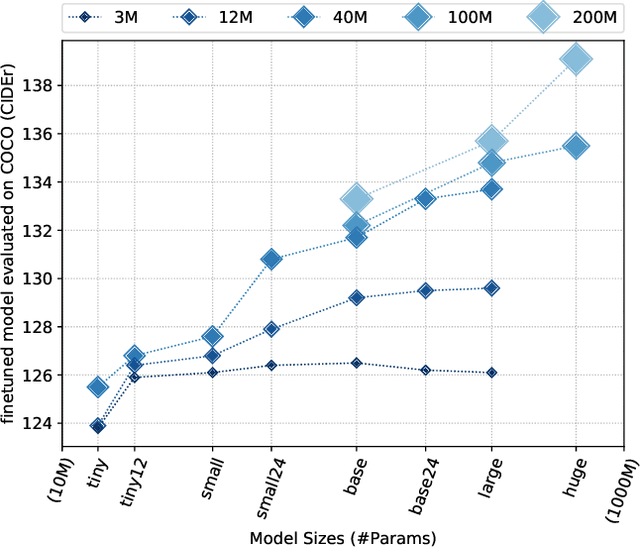

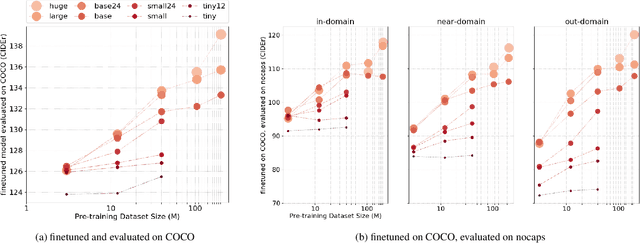
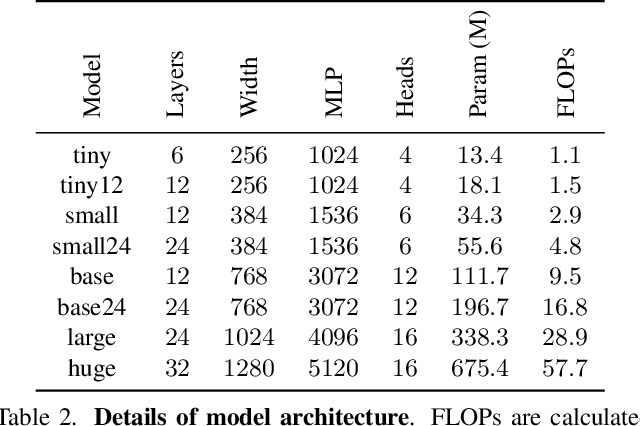
In recent years, we have witnessed significant performance boost in the image captioning task based on vision-language pre-training (VLP). Scale is believed to be an important factor for this advance. However, most existing work only focuses on pre-training transformers with moderate sizes (e.g., 12 or 24 layers) on roughly 4 million images. In this paper, we present LEMON, a LargE-scale iMage captiONer, and provide the first empirical study on the scaling behavior of VLP for image captioning. We use the state-of-the-art VinVL model as our reference model, which consists of an image feature extractor and a transformer model, and scale the transformer both up and down, with model sizes ranging from 13 to 675 million parameters. In terms of data, we conduct experiments with up to 200 million image-text pairs which are automatically collected from web based on the alt attribute of the image (dubbed as ALT200M). Extensive analysis helps to characterize the performance trend as the model size and the pre-training data size increase. We also compare different training recipes, especially for training on large-scale noisy data. As a result, LEMON achieves new state of the arts on several major image captioning benchmarks, including COCO Caption, nocaps, and Conceptual Captions. We also show LEMON can generate captions with long-tail visual concepts when used in a zero-shot manner.
Crossing the Format Boundary of Text and Boxes: Towards Unified Vision-Language Modeling
Nov 23, 2021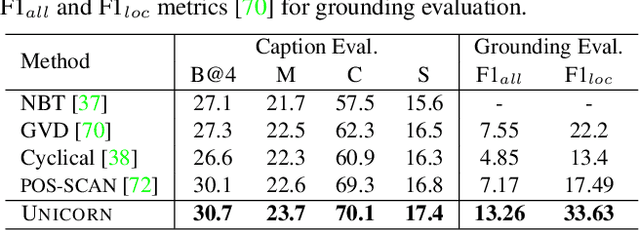
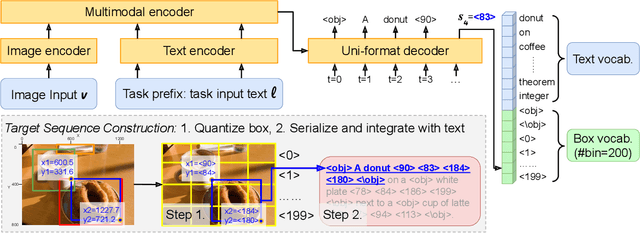
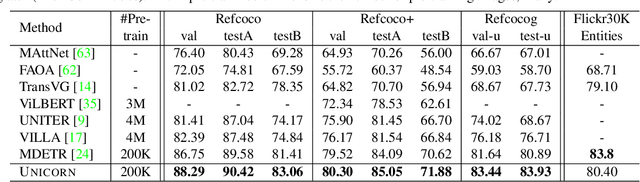
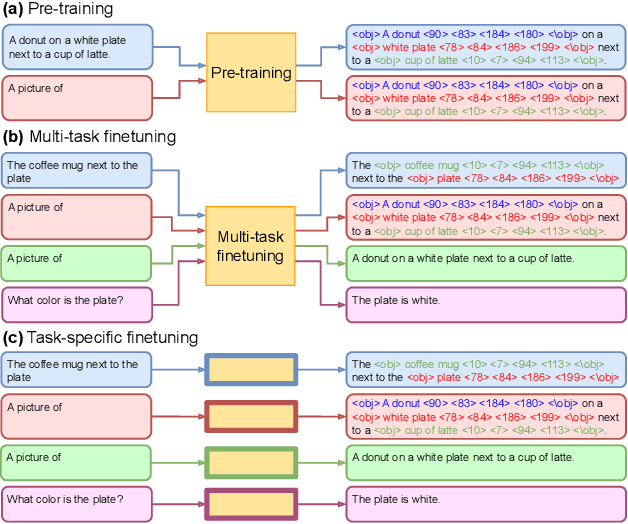
In this paper, we propose UNICORN, a vision-language (VL) model that unifies text generation and bounding box prediction into a single architecture. Specifically, we quantize each box into four discrete box tokens and serialize them as a sequence, which can be integrated with text tokens. We formulate all VL problems as a generation task, where the target sequence consists of the integrated text and box tokens. We then train a transformer encoder-decoder to predict the target in an auto-regressive manner. With such a unified framework and input-output format, UNICORN achieves comparable performance to task-specific state of the art on 7 VL benchmarks, covering the visual grounding, grounded captioning, visual question answering, and image captioning tasks. When trained with multi-task finetuning, UNICORN can approach different VL tasks with a single set of parameters, thus crossing downstream task boundary. We show that having a single model not only saves parameters, but also further boosts the model performance on certain tasks. Finally, UNICORN shows the capability of generalizing to new tasks such as ImageNet object localization.
Florence: A New Foundation Model for Computer Vision
Nov 22, 2021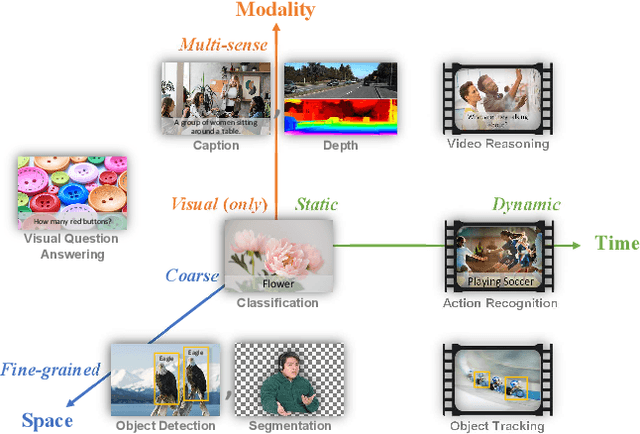
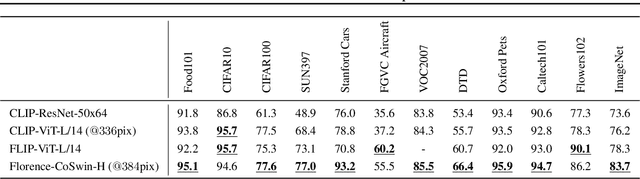
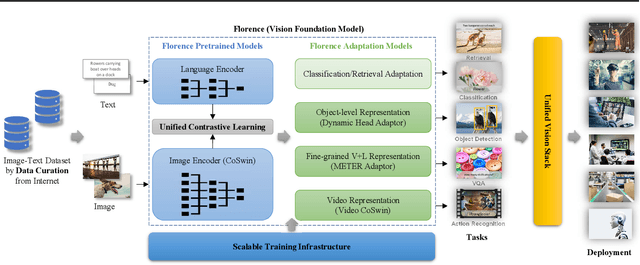
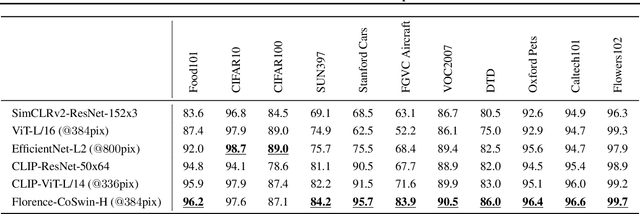
Automated visual understanding of our diverse and open world demands computer vision models to generalize well with minimal customization for specific tasks, similar to human vision. Computer vision foundation models, which are trained on diverse, large-scale dataset and can be adapted to a wide range of downstream tasks, are critical for this mission to solve real-world computer vision applications. While existing vision foundation models such as CLIP, ALIGN, and Wu Dao 2.0 focus mainly on mapping images and textual representations to a cross-modal shared representation, we introduce a new computer vision foundation model, Florence, to expand the representations from coarse (scene) to fine (object), from static (images) to dynamic (videos), and from RGB to multiple modalities (caption, depth). By incorporating universal visual-language representations from Web-scale image-text data, our Florence model can be easily adapted for various computer vision tasks, such as classification, retrieval, object detection, VQA, image caption, video retrieval and action recognition. Moreover, Florence demonstrates outstanding performance in many types of transfer learning: fully sampled fine-tuning, linear probing, few-shot transfer and zero-shot transfer for novel images and objects. All of these properties are critical for our vision foundation model to serve general purpose vision tasks. Florence achieves new state-of-the-art results in majority of 44 representative benchmarks, e.g., ImageNet-1K zero-shot classification with top-1 accuracy of 83.74 and the top-5 accuracy of 97.18, 62.4 mAP on COCO fine tuning, 80.36 on VQA, and 87.8 on Kinetics-600.
UFO: A UniFied TransfOrmer for Vision-Language Representation Learning
Nov 19, 2021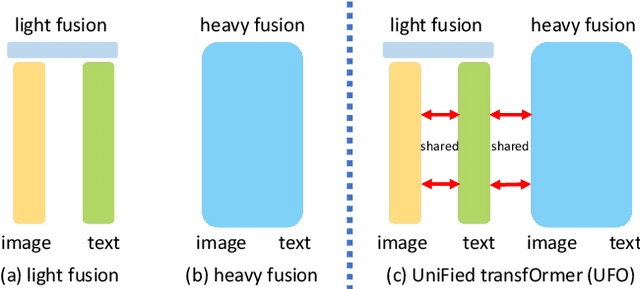
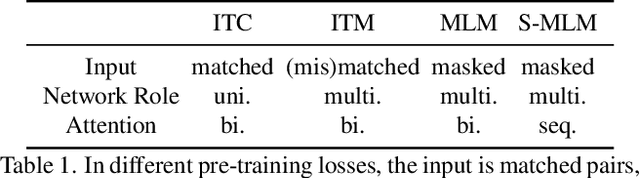
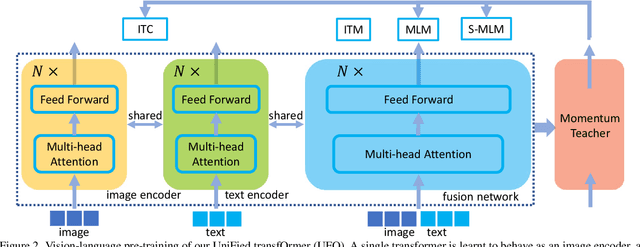
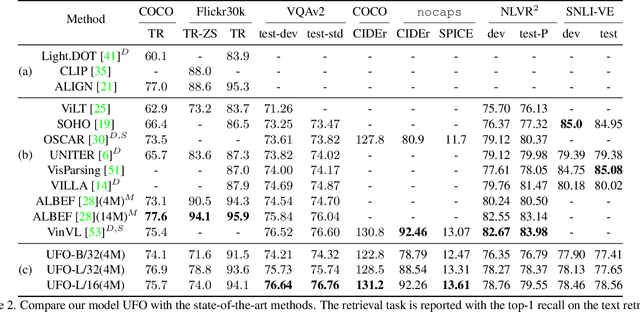
In this paper, we propose a single UniFied transfOrmer (UFO), which is capable of processing either unimodal inputs (e.g., image or language) or multimodal inputs (e.g., the concatenation of the image and the question), for vision-language (VL) representation learning. Existing approaches typically design an individual network for each modality and/or a specific fusion network for multimodal tasks. To simplify the network architecture, we use a single transformer network and enforce multi-task learning during VL pre-training, which includes the image-text contrastive loss, image-text matching loss, and masked language modeling loss based on the bidirectional and the seq2seq attention mask. The same transformer network is used as the image encoder, the text encoder, or the fusion network in different pre-training tasks. Empirically, we observe less conflict among different tasks and achieve new state of the arts on visual question answering, COCO image captioning (cross-entropy optimization) and nocaps (in SPICE). On other downstream tasks, e.g., image-text retrieval, we also achieve competitive performance.
An Empirical Study of GPT-3 for Few-Shot Knowledge-Based VQA
Sep 10, 2021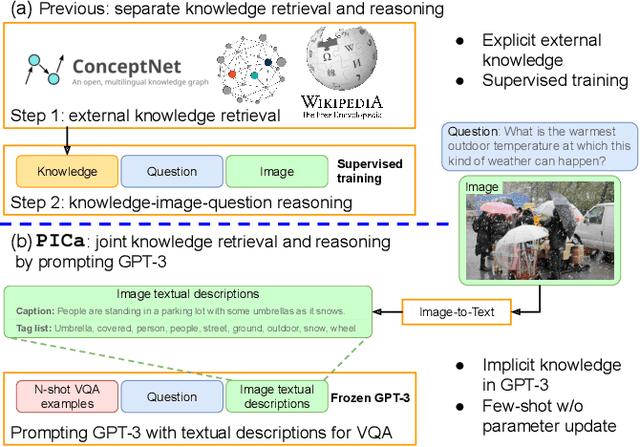

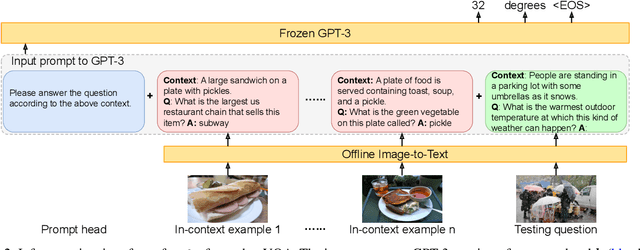

Knowledge-based visual question answering (VQA) involves answering questions that require external knowledge not present in the image. Existing methods first retrieve knowledge from external resources, then reason over the selected knowledge, the input image, and question for answer prediction. However, this two-step approach could lead to mismatches that potentially limit the VQA performance. For example, the retrieved knowledge might be noisy and irrelevant to the question, and the re-embedded knowledge features during reasoning might deviate from their original meanings in the knowledge base (KB). To address this challenge, we propose PICa, a simple yet effective method that Prompts GPT3 via the use of Image Captions, for knowledge-based VQA. Inspired by GPT-3's power in knowledge retrieval and question answering, instead of using structured KBs as in previous work, we treat GPT-3 as an implicit and unstructured KB that can jointly acquire and process relevant knowledge. Specifically, we first convert the image into captions (or tags) that GPT-3 can understand, then adapt GPT-3 to solve the VQA task in a few-shot manner by just providing a few in-context VQA examples. We further boost performance by carefully investigating: (i) what text formats best describe the image content, and (ii) how in-context examples can be better selected and used. PICa unlocks the first use of GPT-3 for multimodal tasks. By using only 16 examples, PICa surpasses the supervised state of the art by an absolute +8.6 points on the OK-VQA dataset. We also benchmark PICa on VQAv2, where PICa also shows a decent few-shot performance.