 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
HistoKT: Cross Knowledge Transfer in Computational Pathology
Jan 27, 2022
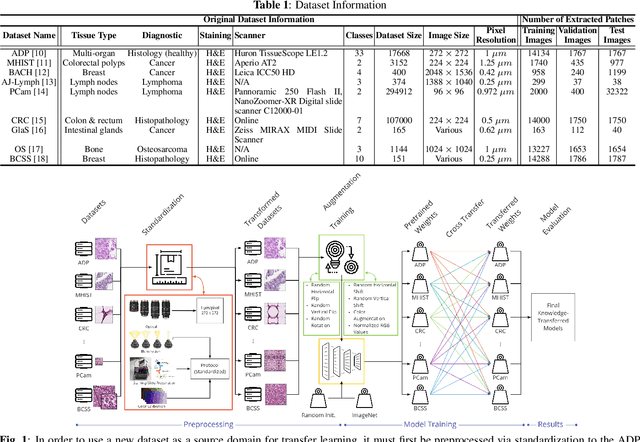
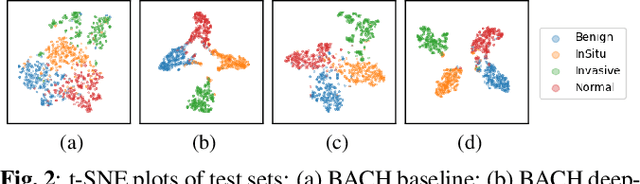
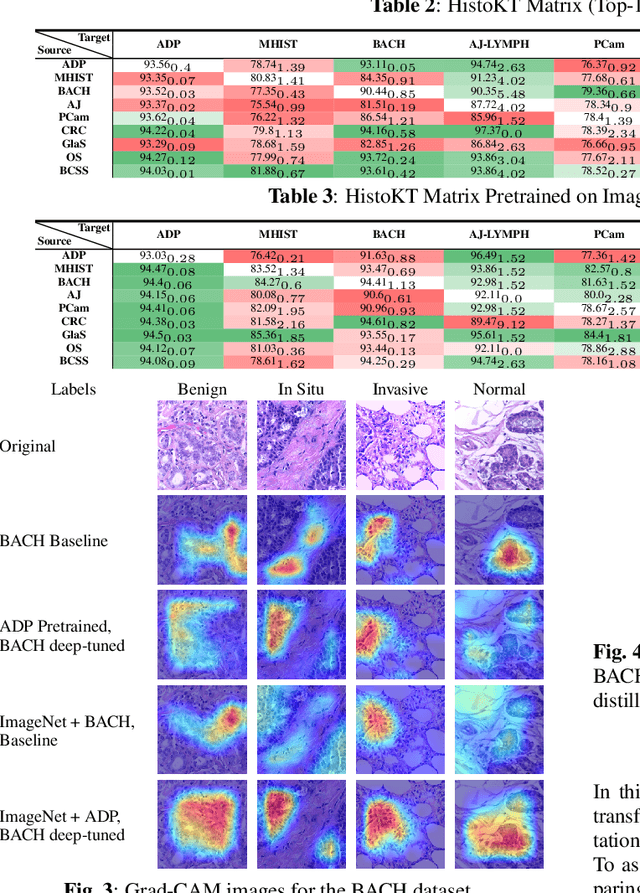
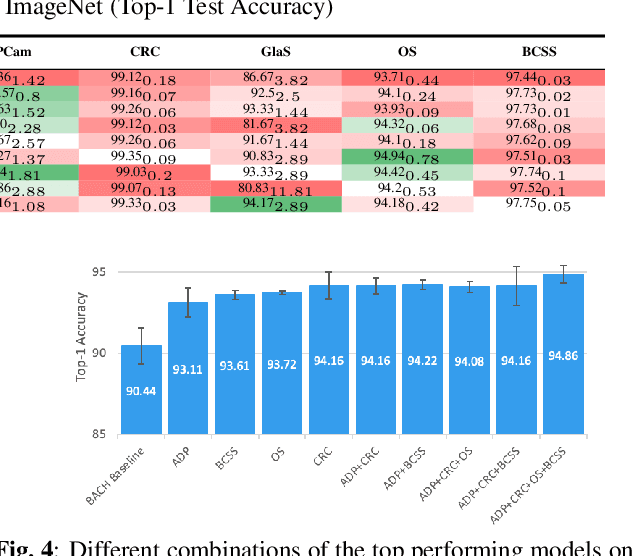
The lack of well-annotated datasets in computational pathology (CPath) obstructs the application of deep learning techniques for classifying medical images. %Since pathologist time is expensive, dataset curation is intrinsically difficult. Many CPath workflows involve transferring learned knowledge between various image domains through transfer learning. Currently, most transfer learning research follows a model-centric approach, tuning network parameters to improve transfer results over few datasets. In this paper, we take a data-centric approach to the transfer learning problem and examine the existence of generalizable knowledge between histopathological datasets. First, we create a standardization workflow for aggregating existing histopathological data. We then measure inter-domain knowledge by training ResNet18 models across multiple histopathological datasets, and cross-transferring between them to determine the quantity and quality of innate shared knowledge. Additionally, we use weight distillation to share knowledge between models without additional training. We find that hard to learn, multi-class datasets benefit most from pretraining, and a two stage learning framework incorporating a large source domain such as ImageNet allows for better utilization of smaller datasets. Furthermore, we find that weight distillation enables models trained on purely histopathological features to outperform models using external natural image data.
Is It a Plausible Colour? UCapsNet for Image Colourisation
Dec 04, 2020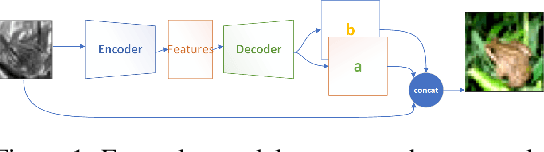
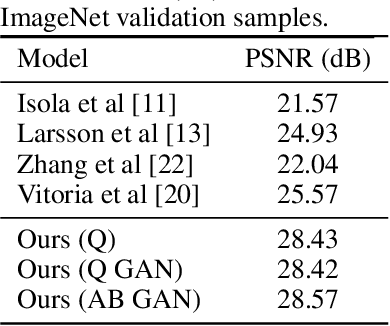
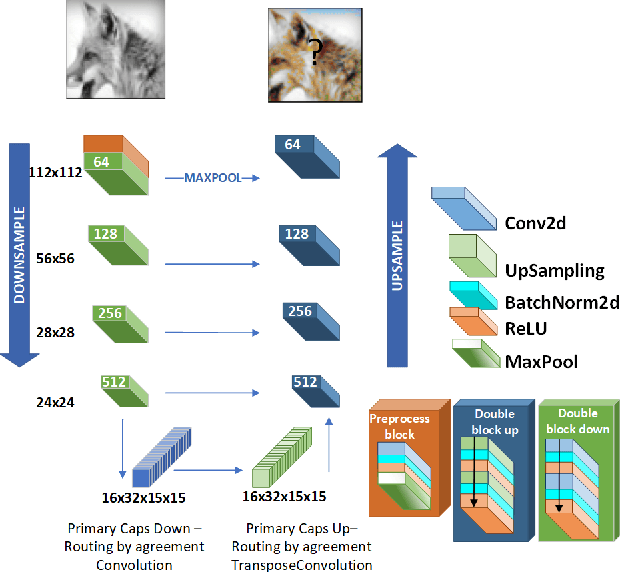

Human beings can imagine the colours of a grayscale image with no particular effort thanks to their ability of semantic feature extraction. Can an autonomous system achieve that? Can it hallucinate plausible and vibrant colours? This is the colourisation problem. Different from existing works relying on convolutional neural network models pre-trained with supervision, we cast such colourisation problem as a self-supervised learning task. We tackle the problem with the introduction of a novel architecture based on Capsules trained following the adversarial learning paradigm. Capsule networks are able to extract a semantic representation of the entities in the image but loose details about their spatial information, which is important for colourising a grayscale image. Thus our UCapsNet structure comes with an encoding phase that extracts entities through capsules and spatial details through convolutional neural networks. A decoding phase merges the entity features with the spatial features to hallucinate a plausible colour version of the input datum. Results on the ImageNet benchmark show that our approach is able to generate more vibrant and plausible colours than exiting solutions and achieves superior performance than models pre-trained with supervision.
The Overlooked Classifier in Human-Object Interaction Recognition
Mar 10, 2022
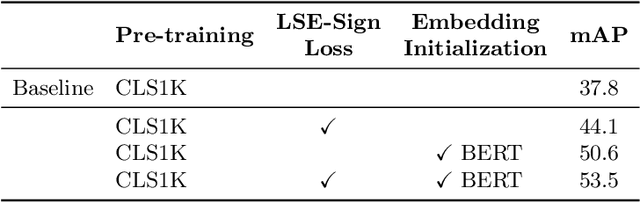
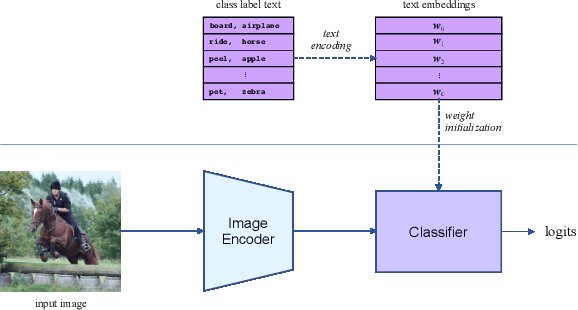

Human-Object Interaction (HOI) recognition is challenging due to two factors: (1) significant imbalance across classes and (2) requiring multiple labels per image. This paper shows that these two challenges can be effectively addressed by improving the classifier with the backbone architecture untouched. Firstly, we encode the semantic correlation among classes into the classification head by initializing the weights with language embeddings of HOIs. As a result, the performance is boosted significantly, especially for the few-shot subset. Secondly, we propose a new loss named LSE-Sign to enhance multi-label learning on a long-tailed dataset. Our simple yet effective method enables detection-free HOI classification, outperforming the state-of-the-arts that require object detection and human pose by a clear margin. Moreover, we transfer the classification model to instance-level HOI detection by connecting it with an off-the-shelf object detector. We achieve state-of-the-art without additional fine-tuning.
pi-GAN: Periodic Implicit Generative Adversarial Networks for 3D-Aware Image Synthesis
Dec 02, 2020

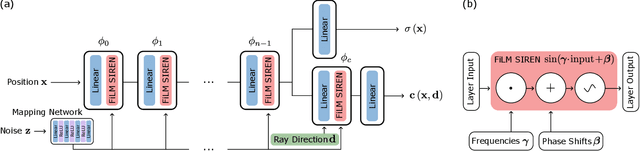

We have witnessed rapid progress on 3D-aware image synthesis, leveraging recent advances in generative visual models and neural rendering. Existing approaches however fall short in two ways: first, they may lack an underlying 3D representation or rely on view-inconsistent rendering, hence synthesizing images that are not multi-view consistent; second, they often depend upon representation network architectures that are not expressive enough, and their results thus lack in image quality. We propose a novel generative model, named Periodic Implicit Generative Adversarial Networks ($\pi$-GAN or pi-GAN), for high-quality 3D-aware image synthesis. $\pi$-GAN leverages neural representations with periodic activation functions and volumetric rendering to represent scenes as view-consistent 3D representations with fine detail. The proposed approach obtains state-of-the-art results for 3D-aware image synthesis with multiple real and synthetic datasets.
The Abduction of Sherlock Holmes: A Dataset for Visual Abductive Reasoning
Feb 10, 2022
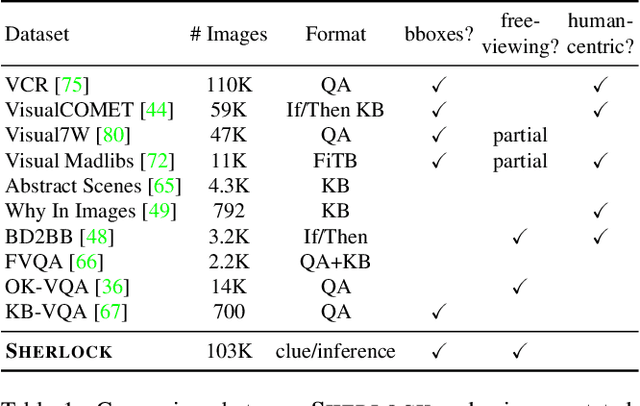

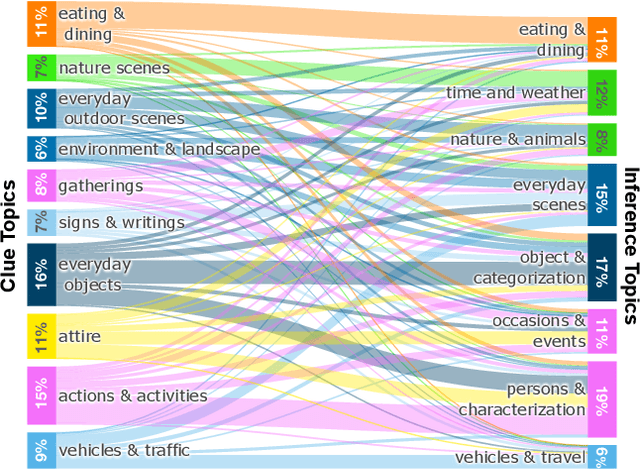
Humans have remarkable capacity to reason abductively and hypothesize about what lies beyond the literal content of an image. By identifying concrete visual clues scattered throughout a scene, we almost can't help but draw probable inferences beyond the literal scene based on our everyday experience and knowledge about the world. For example, if we see a "20 mph" sign alongside a road, we might assume the street sits in a residential area (rather than on a highway), even if no houses are pictured. Can machines perform similar visual reasoning? We present Sherlock, an annotated corpus of 103K images for testing machine capacity for abductive reasoning beyond literal image contents. We adopt a free-viewing paradigm: participants first observe and identify salient clues within images (e.g., objects, actions) and then provide a plausible inference about the scene, given the clue. In total, we collect 363K (clue, inference) pairs, which form a first-of-its-kind abductive visual reasoning dataset. Using our corpus, we test three complementary axes of abductive reasoning. We evaluate the capacity of models to: i) retrieve relevant inferences from a large candidate corpus; ii) localize evidence for inferences via bounding boxes, and iii) compare plausible inferences to match human judgments on a newly-collected diagnostic corpus of 19K Likert-scale judgments. While we find that fine-tuning CLIP-RN50x64 with a multitask objective outperforms strong baselines, significant headroom exists between model performance and human agreement. We provide analysis that points towards future work.
GLEAN: Generative Latent Bank for Large-Factor Image Super-Resolution
Dec 01, 2020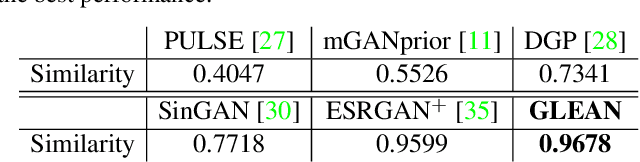
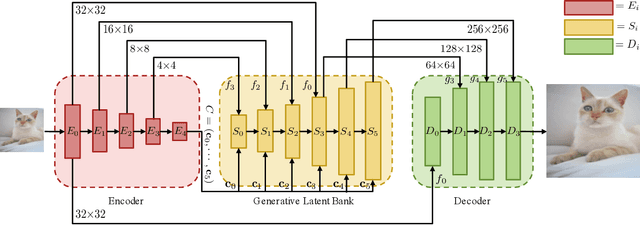


We show that pre-trained Generative Adversarial Networks (GANs), e.g., StyleGAN, can be used as a latent bank to improve the restoration quality of large-factor image super-resolution (SR). While most existing SR approaches attempt to generate realistic textures through learning with adversarial loss, our method, Generative LatEnt bANk (GLEAN), goes beyond existing practices by directly leveraging rich and diverse priors encapsulated in a pre-trained GAN. But unlike prevalent GAN inversion methods that require expensive image-specific optimization at runtime, our approach only needs a single forward pass to generate the upscaled image. GLEAN can be easily incorporated in a simple encoder-bank-decoder architecture with multi-resolution skip connections. Switching the bank allows the method to deal with images from diverse categories, e.g., cat, building, human face, and car. Images upscaled by GLEAN show clear improvements in terms of fidelity and texture faithfulness in comparison to existing methods.
WSSS4LUAD: Grand Challenge on Weakly-supervised Tissue Semantic Segmentation for Lung Adenocarcinoma
Apr 13, 2022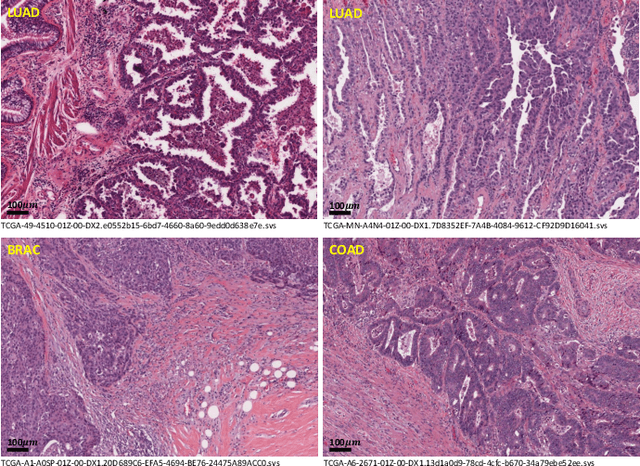
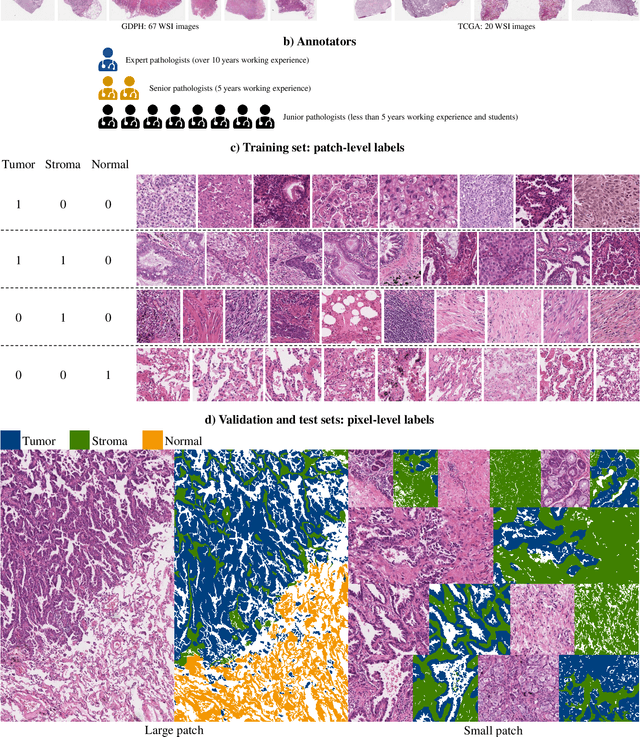
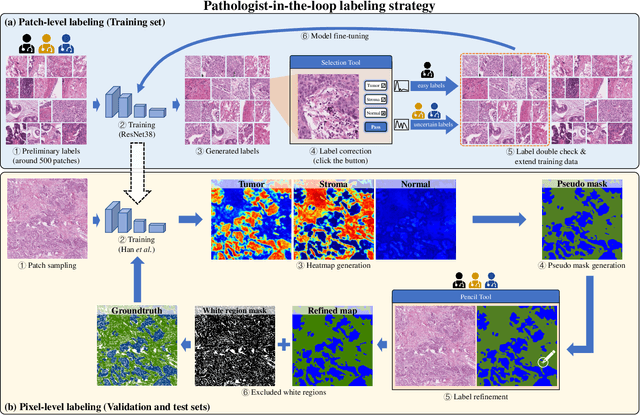
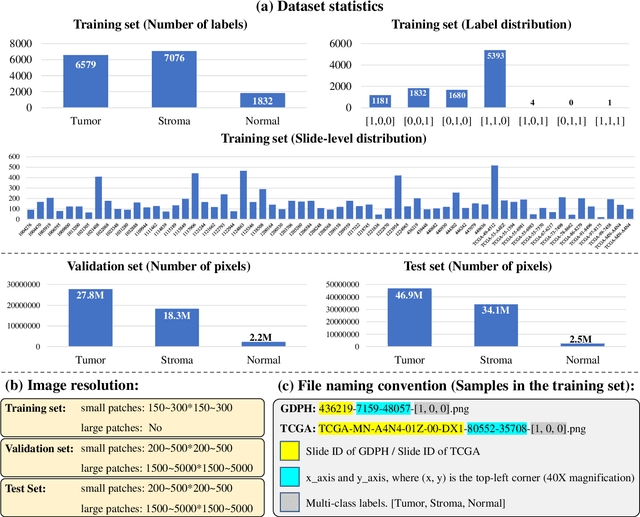
Lung cancer is the leading cause of cancer death worldwide, and adenocarcinoma (LUAD) is the most common subtype. Exploiting the potential value of the histopathology images can promote precision medicine in oncology. Tissue segmentation is the basic upstream task of histopathology image analysis. Existing deep learning models have achieved superior segmentation performance but require sufficient pixel-level annotations, which is time-consuming and expensive. To enrich the label resources of LUAD and to alleviate the annotation efforts, we organize this challenge WSSS4LUAD to call for the outstanding weakly-supervised semantic segmentation techniques for histopathology images of LUAD. Participants have to design the algorithm to segment tumor epithelial, tumor-associated stroma and normal tissue with only patch-level labels. This challenge includes 10,091 patch-level annotations (the training set) and over 130 million labeled pixels (the validation and test sets), from 67 WSIs (47 from GDPH, 20 from TCGA). All the labels were generated by a pathologist-in-the-loop pipeline with the help of AI models and checked by the label review board. Among 532 registrations, 28 teams submitted the results in the test phase with over 1,000 submissions. Finally, the first place team achieved mIoU of 0.8413 (tumor: 0.8389, stroma: 0.7931, normal: 0.8919). According to the technical reports of the top-tier teams, CAM is still the most popular approach in WSSS. Cutmix data augmentation has been widely adopted to generate more reliable samples. With the success of this challenge, we believe that WSSS approaches with patch-level annotations can replace the traditional pixel annotations while reducing the annotation efforts. The entire dataset has been released to encourage more researches on computational pathology in LUAD and more novel WSSS techniques.
BED: A Real-Time Object Detection System for Edge Devices
Feb 14, 2022


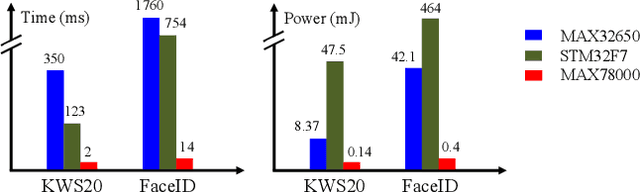
Deploying machine learning models to edge devices has many real-world applications, especially for the scenarios that demand low latency, low power, or data privacy. However, it requires substantial research and engineering efforts due to the limited computational resources and memory of edge devices. In this demo, we present BED, an object detection system for edge devices practiced on the MAX78000 DNN accelerator. BED integrates on-device DNN inference with a camera and a screen for image acquisition and output exhibition, respectively. Experiment results indicate BED can provide accurate detection with an only 300KB tiny DNN model.
Unsupervised Semantic Segmentation by Distilling Feature Correspondences
Mar 16, 2022Unsupervised semantic segmentation aims to discover and localize semantically meaningful categories within image corpora without any form of annotation. To solve this task, algorithms must produce features for every pixel that are both semantically meaningful and compact enough to form distinct clusters. Unlike previous works which achieve this with a single end-to-end framework, we propose to separate feature learning from cluster compactification. Empirically, we show that current unsupervised feature learning frameworks already generate dense features whose correlations are semantically consistent. This observation motivates us to design STEGO ($\textbf{S}$elf-supervised $\textbf{T}$ransformer with $\textbf{E}$nergy-based $\textbf{G}$raph $\textbf{O}$ptimization), a novel framework that distills unsupervised features into high-quality discrete semantic labels. At the core of STEGO is a novel contrastive loss function that encourages features to form compact clusters while preserving their relationships across the corpora. STEGO yields a significant improvement over the prior state of the art, on both the CocoStuff ($\textbf{+14 mIoU}$) and Cityscapes ($\textbf{+9 mIoU}$) semantic segmentation challenges.
Graph Neural Networks in Particle Physics: Implementations, Innovations, and Challenges
Mar 25, 2022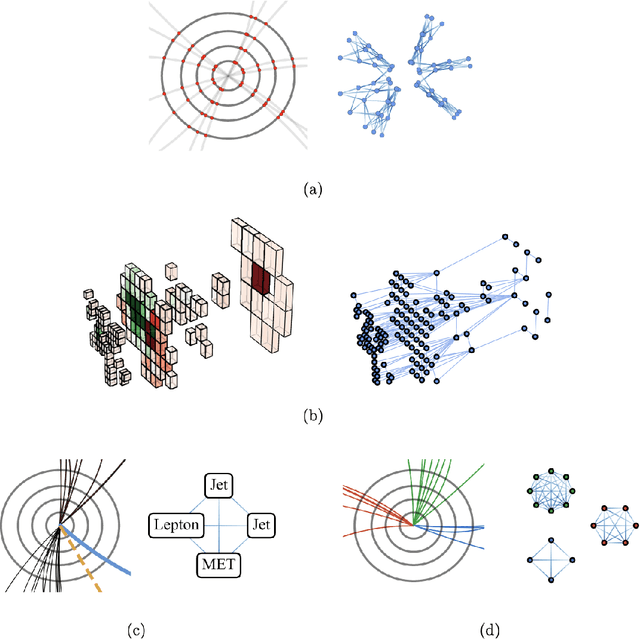
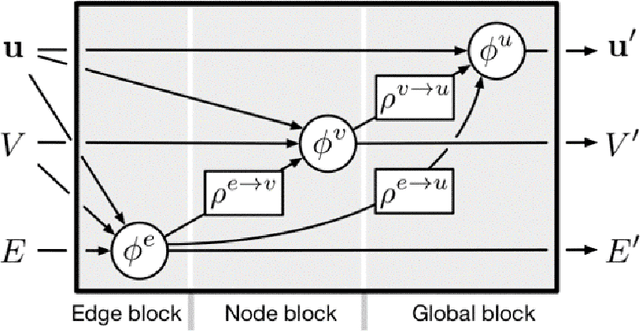
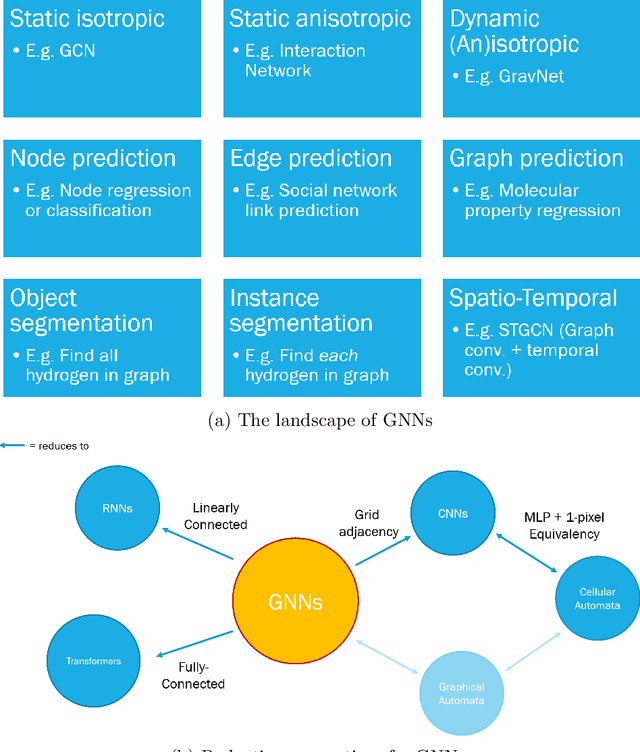
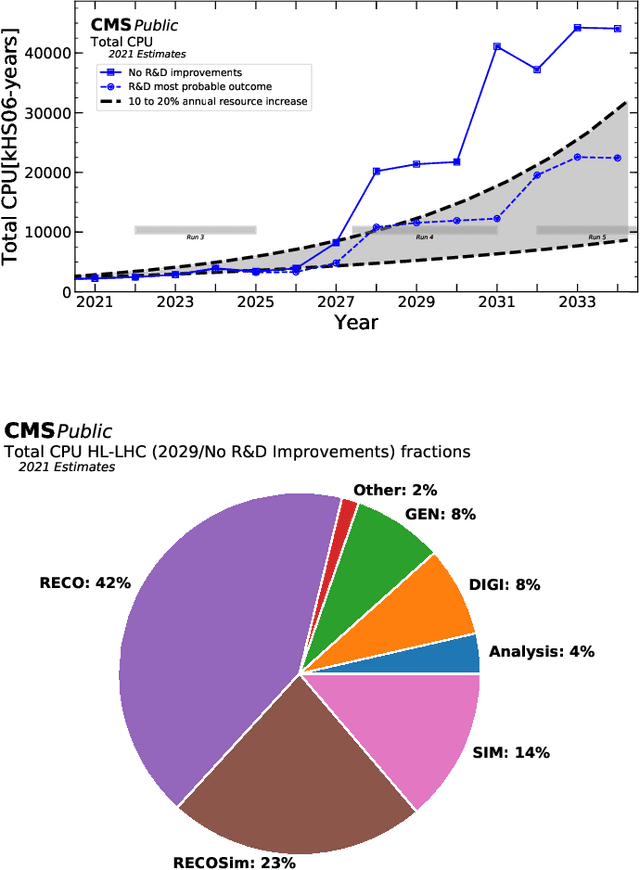
Many physical systems can be best understood as sets of discrete data with associated relationships. Where previously these sets of data have been formulated as series or image data to match the available machine learning architectures, with the advent of graph neural networks (GNNs), these systems can be learned natively as graphs. This allows a wide variety of high- and low-level physical features to be attached to measurements and, by the same token, a wide variety of HEP tasks to be accomplished by the same GNN architectures. GNNs have found powerful use-cases in reconstruction, tagging, generation and end-to-end analysis. With the wide-spread adoption of GNNs in industry, the HEP community is well-placed to benefit from rapid improvements in GNN latency and memory usage. However, industry use-cases are not perfectly aligned with HEP and much work needs to be done to best match unique GNN capabilities to unique HEP obstacles. We present here a range of these capabilities, predictions of which are currently being well-adopted in HEP communities, and which are still immature. We hope to capture the landscape of graph techniques in machine learning as well as point out the most significant gaps that are inhibiting potentially large leaps in research.