 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeX-Palm: Paired Multispectral-to-Smartphone Dataset for Cross-Domain Palmprint Authentication
Jun 07, 2026Palmprint modality offers a privacy-preserving biometric solution, yet its deployment is hindered by the domain gap between controlled enrollment and unconstrained authentication. Existing datasets are largely restricted to controlled setups and fail to capture the compound variability of real-world environments. In this paper, we introduce X-Palm, a cross-domain dataset comprising 6,006 palm images from 103 individuals (206 hands). To the best of our knowledge, X-Palm is the first palmprint dataset providing novel paired-identity acquisition specifically designed to bridge the gap between reliably controlled multispectral enrollment and unconstrained mobile authentication while encompassing a broad spectrum of in-the-wild variability. Unlike existing datasets that focus on single to a few variations, X-Palm addresses the massive modality and environmental shifts encountered in practical deployments by capturing paired data for identities across two distinct domains: (1) a controlled Multispectral Palmprint setting using our custom-developed scanner, and (2) an unconstrained smartphone palmprint setting that is participant-driven, incorporating simultaneous variations in hardware, hand pose, illumination, background, camera-to-hand distance, perspective, and palm surface conditions (e.g., moisture and occlusions). Our extensive benchmarks of 12 SOTA models reveal that while existing methods achieve high performance on controlled data, they experience severe performance collapse on X-Palm. Conversely, models trained on X-Palm demonstrate consistent robustness across domains, positioning X-Palm as a valuable resource for training a model towards real-world, cross-domain generalization. Data access instructions and the related benchmarking codes are publicly available at: https://github.com/X-Palm/X-Palm-2026
HistoKT: Cross Knowledge Transfer in Computational Pathology
Jan 27, 2022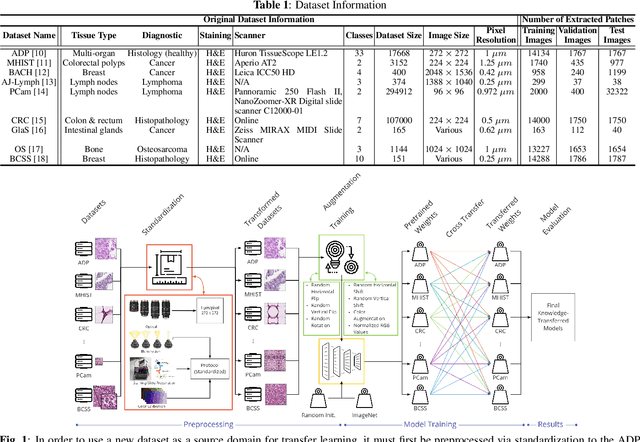
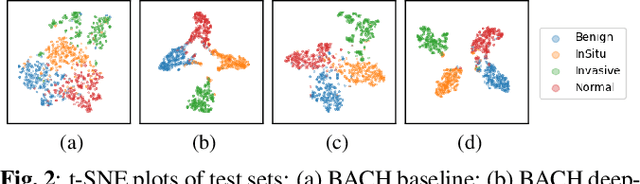
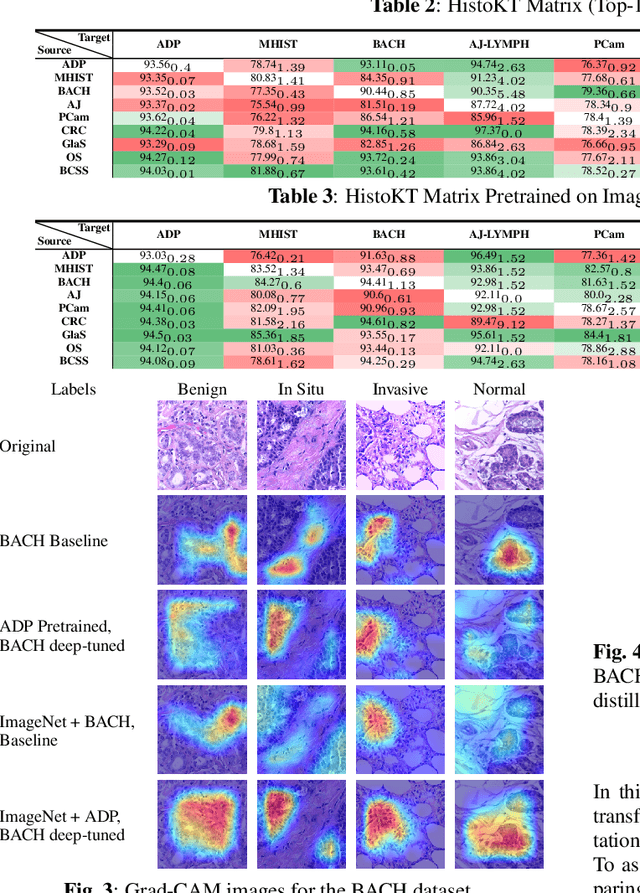
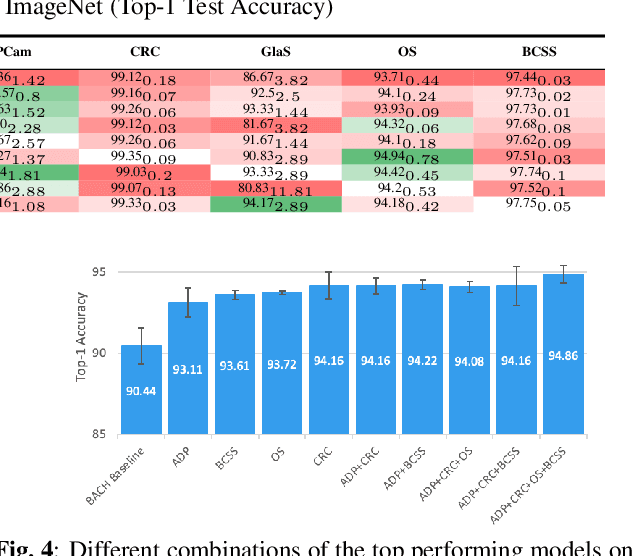
The lack of well-annotated datasets in computational pathology (CPath) obstructs the application of deep learning techniques for classifying medical images. %Since pathologist time is expensive, dataset curation is intrinsically difficult. Many CPath workflows involve transferring learned knowledge between various image domains through transfer learning. Currently, most transfer learning research follows a model-centric approach, tuning network parameters to improve transfer results over few datasets. In this paper, we take a data-centric approach to the transfer learning problem and examine the existence of generalizable knowledge between histopathological datasets. First, we create a standardization workflow for aggregating existing histopathological data. We then measure inter-domain knowledge by training ResNet18 models across multiple histopathological datasets, and cross-transferring between them to determine the quantity and quality of innate shared knowledge. Additionally, we use weight distillation to share knowledge between models without additional training. We find that hard to learn, multi-class datasets benefit most from pretraining, and a two stage learning framework incorporating a large source domain such as ImageNet allows for better utilization of smaller datasets. Furthermore, we find that weight distillation enables models trained on purely histopathological features to outperform models using external natural image data.