 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMathNet: a Global Multimodal Benchmark for Mathematical Reasoning and Retrieval
Apr 20, 2026Mathematical problem solving remains a challenging test of reasoning for large language and multimodal models, yet existing benchmarks are limited in size, language coverage, and task diversity. We introduce MathNet, a high-quality, large-scale, multimodal, and multilingual dataset of Olympiad-level math problems together with a benchmark for evaluating mathematical reasoning in generative models and mathematical retrieval in embedding-based systems. MathNet spans 47 countries, 17 languages, and two decades of competitions, comprising 30,676 expert-authored problems with solutions across diverse domains. In addition to the core dataset, we construct a retrieval benchmark consisting of mathematically equivalent and structurally similar problem pairs curated by human experts. MathNet supports three tasks: (i) Problem Solving, (ii) Math-Aware Retrieval, and (iii) Retrieval-Augmented Problem Solving. Experimental results show that even state-of-the-art reasoning models (78.4% for Gemini-3.1-Pro and 69.3% for GPT-5) remain challenged, while embedding models struggle to retrieve equivalent problems. We further show that retrieval-augmented generation performance is highly sensitive to retrieval quality; for example, DeepSeek-V3.2-Speciale achieves gains of up to 12%, obtaining the highest scores on the benchmark. MathNet provides the largest high-quality Olympiad dataset together with the first benchmark for evaluating mathematical problem retrieval, and we publicly release both the dataset and benchmark at https://mathnet.mit.edu.
* ICLR 2026; Website: http://mathnet.mit.edu
Beyond I-Con: Exploring New Dimension of Distance Measures in Representation Learning
Sep 05, 2025The Information Contrastive (I-Con) framework revealed that over 23 representation learning methods implicitly minimize KL divergence between data and learned distributions that encode similarities between data points. However, a KL-based loss may be misaligned with the true objective, and properties of KL divergence such as asymmetry and unboundedness may create optimization challenges. We present Beyond I-Con, a framework that enables systematic discovery of novel loss functions by exploring alternative statistical divergences and similarity kernels. Key findings: (1) on unsupervised clustering of DINO-ViT embeddings, we achieve state-of-the-art results by modifying the PMI algorithm to use total variation (TV) distance; (2) on supervised contrastive learning, we outperform the standard approach by using TV and a distance-based similarity kernel instead of KL and an angular kernel; (3) on dimensionality reduction, we achieve superior qualitative results and better performance on downstream tasks than SNE by replacing KL with a bounded f-divergence. Our results highlight the importance of considering divergence and similarity kernel choices in representation learning optimization.
I-Con: A Unifying Framework for Representation Learning
Apr 23, 2025



As the field of representation learning grows, there has been a proliferation of different loss functions to solve different classes of problems. We introduce a single information-theoretic equation that generalizes a large collection of modern loss functions in machine learning. In particular, we introduce a framework that shows that several broad classes of machine learning methods are precisely minimizing an integrated KL divergence between two conditional distributions: the supervisory and learned representations. This viewpoint exposes a hidden information geometry underlying clustering, spectral methods, dimensionality reduction, contrastive learning, and supervised learning. This framework enables the development of new loss functions by combining successful techniques from across the literature. We not only present a wide array of proofs, connecting over 23 different approaches, but we also leverage these theoretical results to create state-of-the-art unsupervised image classifiers that achieve a +8% improvement over the prior state-of-the-art on unsupervised classification on ImageNet-1K. We also demonstrate that I-Con can be used to derive principled debiasing methods which improve contrastive representation learners.
Seeing Faces in Things: A Model and Dataset for Pareidolia
Sep 24, 2024



The human visual system is well-tuned to detect faces of all shapes and sizes. While this brings obvious survival advantages, such as a better chance of spotting unknown predators in the bush, it also leads to spurious face detections. ``Face pareidolia'' describes the perception of face-like structure among otherwise random stimuli: seeing faces in coffee stains or clouds in the sky. In this paper, we study face pareidolia from a computer vision perspective. We present an image dataset of ``Faces in Things'', consisting of five thousand web images with human-annotated pareidolic faces. Using this dataset, we examine the extent to which a state-of-the-art human face detector exhibits pareidolia, and find a significant behavioral gap between humans and machines. We find that the evolutionary need for humans to detect animal faces, as well as human faces, may explain some of this gap. Finally, we propose a simple statistical model of pareidolia in images. Through studies on human subjects and our pareidolic face detectors we confirm a key prediction of our model regarding what image conditions are most likely to induce pareidolia. Dataset and Website: https://aka.ms/faces-in-things
Separating the "Chirp" from the "Chat": Self-supervised Visual Grounding of Sound and Language
Jun 09, 2024



We present DenseAV, a novel dual encoder grounding architecture that learns high-resolution, semantically meaningful, and audio-visually aligned features solely through watching videos. We show that DenseAV can discover the ``meaning'' of words and the ``location'' of sounds without explicit localization supervision. Furthermore, it automatically discovers and distinguishes between these two types of associations without supervision. We show that DenseAV's localization abilities arise from a new multi-head feature aggregation operator that directly compares dense image and audio representations for contrastive learning. In contrast, many other systems that learn ``global'' audio and video representations cannot localize words and sound. Finally, we contribute two new datasets to improve the evaluation of AV representations through speech and sound prompted semantic segmentation. On these and other datasets we show DenseAV dramatically outperforms the prior art on speech and sound prompted semantic segmentation. DenseAV outperforms the previous state-of-the-art, ImageBind, on cross-modal retrieval using fewer than half of the parameters. Project Page: \href{https://aka.ms/denseav}{https://aka.ms/denseav}
FeatUp: A Model-Agnostic Framework for Features at Any Resolution
Mar 15, 2024



Deep features are a cornerstone of computer vision research, capturing image semantics and enabling the community to solve downstream tasks even in the zero- or few-shot regime. However, these features often lack the spatial resolution to directly perform dense prediction tasks like segmentation and depth prediction because models aggressively pool information over large areas. In this work, we introduce FeatUp, a task- and model-agnostic framework to restore lost spatial information in deep features. We introduce two variants of FeatUp: one that guides features with high-resolution signal in a single forward pass, and one that fits an implicit model to a single image to reconstruct features at any resolution. Both approaches use a multi-view consistency loss with deep analogies to NeRFs. Our features retain their original semantics and can be swapped into existing applications to yield resolution and performance gains even without re-training. We show that FeatUp significantly outperforms other feature upsampling and image super-resolution approaches in class activation map generation, transfer learning for segmentation and depth prediction, and end-to-end training for semantic segmentation.
Large-Scale Automatic Audiobook Creation
Sep 07, 2023
An audiobook can dramatically improve a work of literature's accessibility and improve reader engagement. However, audiobooks can take hundreds of hours of human effort to create, edit, and publish. In this work, we present a system that can automatically generate high-quality audiobooks from online e-books. In particular, we leverage recent advances in neural text-to-speech to create and release thousands of human-quality, open-license audiobooks from the Project Gutenberg e-book collection. Our method can identify the proper subset of e-book content to read for a wide collection of diversely structured books and can operate on hundreds of books in parallel. Our system allows users to customize an audiobook's speaking speed and style, emotional intonation, and can even match a desired voice using a small amount of sample audio. This work contributed over five thousand open-license audiobooks and an interactive demo that allows users to quickly create their own customized audiobooks. To listen to the audiobook collection visit \url{https://aka.ms/audiobook}.
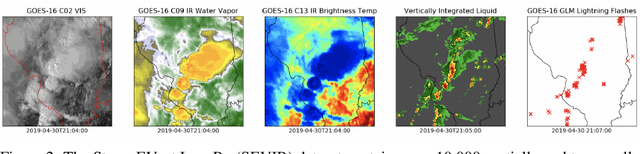
MultiEarth 2023 -- Multimodal Learning for Earth and Environment Workshop and Challenge
Jun 07, 2023

The Multimodal Learning for Earth and Environment Workshop (MultiEarth 2023) is the second annual CVPR workshop aimed at the monitoring and analysis of the health of Earth ecosystems by leveraging the vast amount of remote sensing data that is continuously being collected. The primary objective of this workshop is to bring together the Earth and environmental science communities as well as the multimodal representation learning communities to explore new ways of harnessing technological advancements in support of environmental monitoring. The MultiEarth Workshop also seeks to provide a common benchmark for processing multimodal remote sensing information by organizing public challenges focused on monitoring the Amazon rainforest. These challenges include estimating deforestation, detecting forest fires, translating synthetic aperture radar (SAR) images to the visible domain, and projecting environmental trends. This paper presents the challenge guidelines, datasets, and evaluation metrics. Our challenge website is available at https://sites.google.com/view/rainforest-challenge/multiearth-2023.
Exploring Gender and Race Biases in the NFT Market
Mar 29, 2023



Non-Fungible Tokens (NFTs) are non-interchangeable assets, usually digital art, which are stored on the blockchain. Preliminary studies find that female and darker-skinned NFTs are valued less than their male and lighter-skinned counterparts. However, these studies analyze only the CryptoPunks collection. We test the statistical significance of race and gender biases in the prices of CryptoPunks and present the first study of gender bias in the broader NFT market. We find evidence of racial bias but not gender bias. Our work also introduces a dataset of gender-labeled NFT collections to advance the broader study of social equity in this emerging market.
Developing a Series of AI Challenges for the United States Department of the Air Force
Jul 14, 2022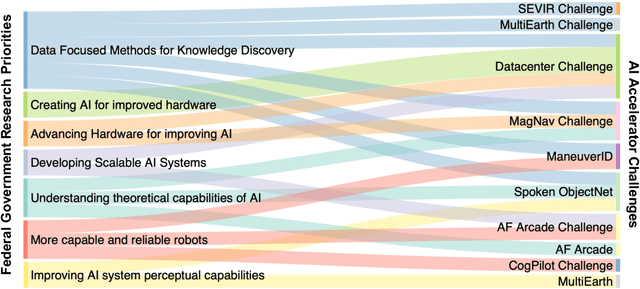

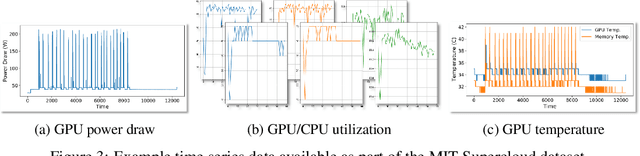
Through a series of federal initiatives and orders, the U.S. Government has been making a concerted effort to ensure American leadership in AI. These broad strategy documents have influenced organizations such as the United States Department of the Air Force (DAF). The DAF-MIT AI Accelerator is an initiative between the DAF and MIT to bridge the gap between AI researchers and DAF mission requirements. Several projects supported by the DAF-MIT AI Accelerator are developing public challenge problems that address numerous Federal AI research priorities. These challenges target priorities by making large, AI-ready datasets publicly available, incentivizing open-source solutions, and creating a demand signal for dual use technologies that can stimulate further research. In this article, we describe these public challenges being developed and how their application contributes to scientific advances.