 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPT-4o System Card
Oct 25, 2024GPT-4o is an autoregressive omni model that accepts as input any combination of text, audio, image, and video, and generates any combination of text, audio, and image outputs. It's trained end-to-end across text, vision, and audio, meaning all inputs and outputs are processed by the same neural network. GPT-4o can respond to audio inputs in as little as 232 milliseconds, with an average of 320 milliseconds, which is similar to human response time in conversation. It matches GPT-4 Turbo performance on text in English and code, with significant improvement on text in non-English languages, while also being much faster and 50\% cheaper in the API. GPT-4o is especially better at vision and audio understanding compared to existing models. In line with our commitment to building AI safely and consistent with our voluntary commitments to the White House, we are sharing the GPT-4o System Card, which includes our Preparedness Framework evaluations. In this System Card, we provide a detailed look at GPT-4o's capabilities, limitations, and safety evaluations across multiple categories, focusing on speech-to-speech while also evaluating text and image capabilities, and measures we've implemented to ensure the model is safe and aligned. We also include third-party assessments on dangerous capabilities, as well as discussion of potential societal impacts of GPT-4o's text and vision capabilities.
MAUVE Scores for Generative Models: Theory and Practice
Dec 30, 2022
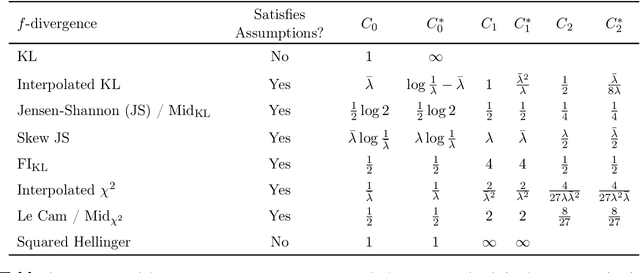
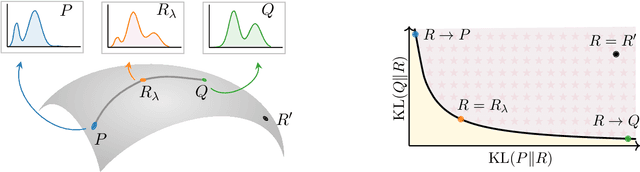

Generative AI has matured to a point where large-scale models can generate text that seems indistinguishable from human-written text and remarkably photorealistic images. Automatically measuring how close the distribution of generated data is to the target real data distribution is a key step in diagnosing existing models and developing better models. We present MAUVE, a family of comparison measures between pairs of distributions such as those encountered in the generative modeling of text or images. These scores are statistical summaries of divergence frontiers capturing two types of errors in generative modeling. We explore four approaches to statistically estimate these scores: vector quantization, non-parametric estimation, classifier-based estimation, and parametric Gaussian approximations. We provide statistical bounds for the vector quantization approach. Empirically, we find that the proposed scores paired with a range of $f$-divergences and statistical estimation methods can quantify the gaps between the distributions of human-written text and those of modern neural language models by correlating with human judgments and identifying known properties of the generated texts. We conclude the paper by demonstrating its applications to other AI domains and discussing practical recommendations.
Do Androids Laugh at Electric Sheep? Humor "Understanding" Benchmarks from The New Yorker Caption Contest
Sep 13, 2022

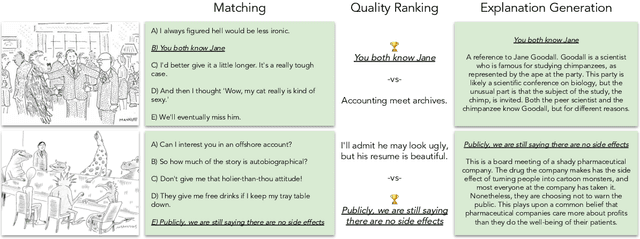
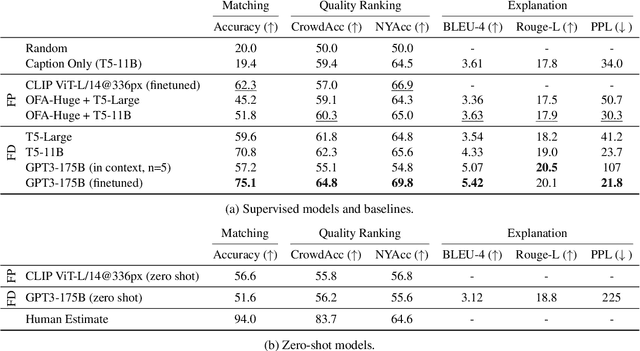
We challenge AI models to "demonstrate understanding" of the sophisticated multimodal humor of The New Yorker Caption Contest. Concretely, we develop three carefully circumscribed tasks for which it suffices (but is not necessary) to grasp potentially complex and unexpected relationships between image and caption, and similarly complex and unexpected allusions to the wide varieties of human experience; these are the hallmarks of a New Yorker-caliber cartoon. We investigate vision-and-language models that take as input the cartoon pixels and caption directly, as well as language-only models for which we circumvent image-processing by providing textual descriptions of the image. Even with the rich multifaceted annotations we provide for the cartoon images, we identify performance gaps between high-quality machine learning models (e.g., a fine-tuned, 175B parameter language model) and humans. We publicly release our corpora including annotations describing the image's locations/entities, what's unusual about the scene, and an explanation of the joke.
Unified-IO: A Unified Model for Vision, Language, and Multi-Modal Tasks
Jun 17, 2022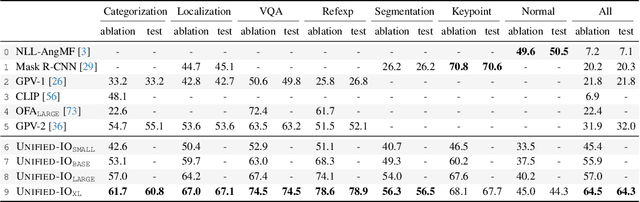
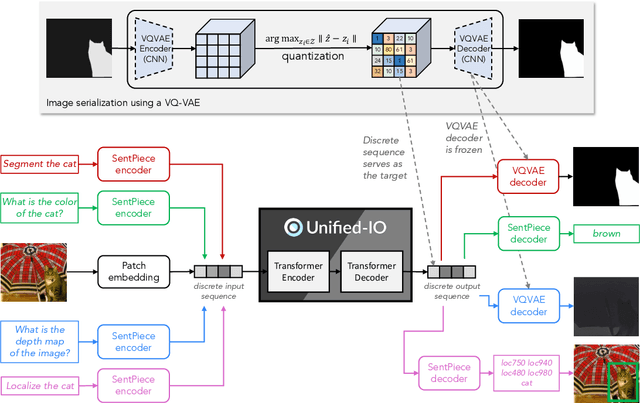
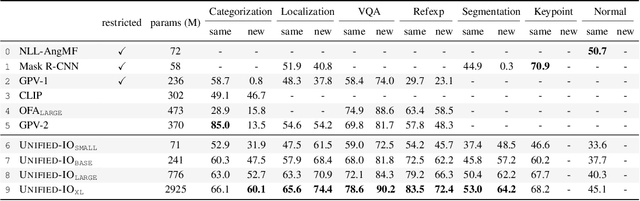
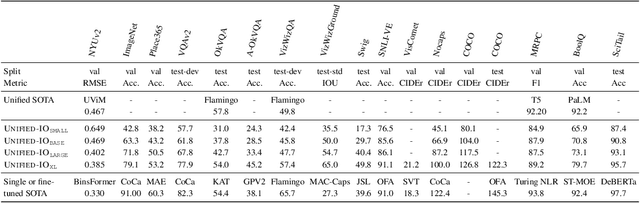
We propose Unified-IO, a model that performs a large variety of AI tasks spanning classical computer vision tasks, including pose estimation, object detection, depth estimation and image generation, vision-and-language tasks such as region captioning and referring expression comprehension, to natural language processing tasks such as question answering and paraphrasing. Developing a single unified model for such a large variety of tasks poses unique challenges due to the heterogeneous inputs and outputs pertaining to each task, including RGB images, per-pixel maps, binary masks, bounding boxes, and language. We achieve this unification by homogenizing every supported input and output into a sequence of discrete vocabulary tokens. This common representation across all tasks allows us to train a single transformer-based architecture, jointly on over 80 diverse datasets in the vision and language fields. Unified-IO is the first model capable of performing all 7 tasks on the GRIT benchmark and produces strong results across 16 diverse benchmarks like NYUv2-Depth, ImageNet, VQA2.0, OK-VQA, Swig, VizWizGround, BoolQ, and SciTail, with no task or benchmark specific fine-tuning. Demos for Unified-IO are available at https://unified-io.allenai.org.
Multimodal Knowledge Alignment with Reinforcement Learning
May 25, 2022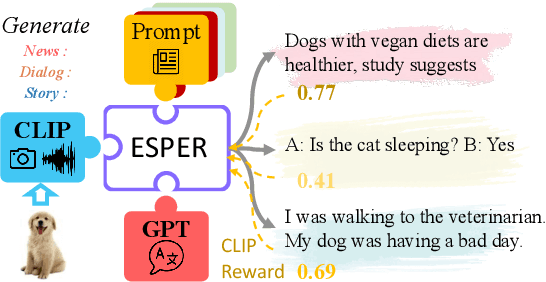
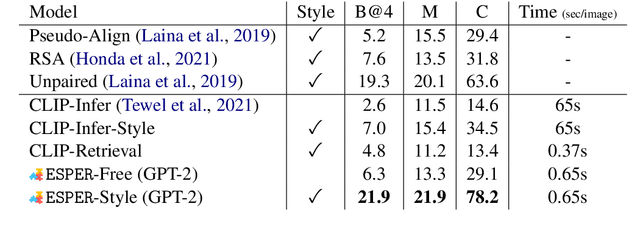
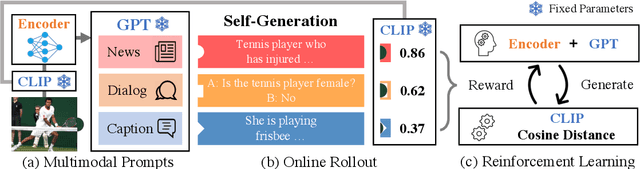
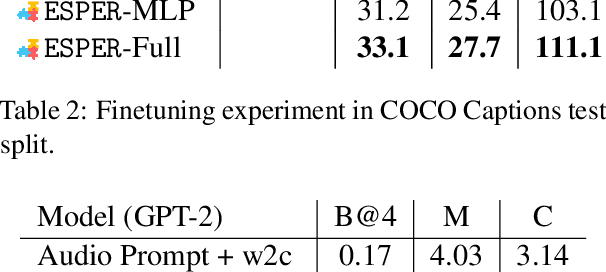
Large language models readily adapt to novel settings, even without task-specific training data. Can their zero-shot capacity be extended to multimodal inputs? In this work, we propose ESPER which extends language-only zero-shot models to unseen multimodal tasks, like image and audio captioning. Our key novelty is to use reinforcement learning to align multimodal inputs to language model generations without direct supervision: for example, in the image case our reward optimization relies only on cosine similarity derived from CLIP, and thus requires no additional explicitly paired (image, caption) data. Because the parameters of the language model are left unchanged, the model maintains its capacity for zero-shot generalization. Experiments demonstrate that ESPER outperforms baselines and prior work on a variety of zero-shot tasks; these include a new benchmark we collect+release, ESP dataset, which tasks models with generating several diversely-styled captions for each image.
The Abduction of Sherlock Holmes: A Dataset for Visual Abductive Reasoning
Feb 10, 2022
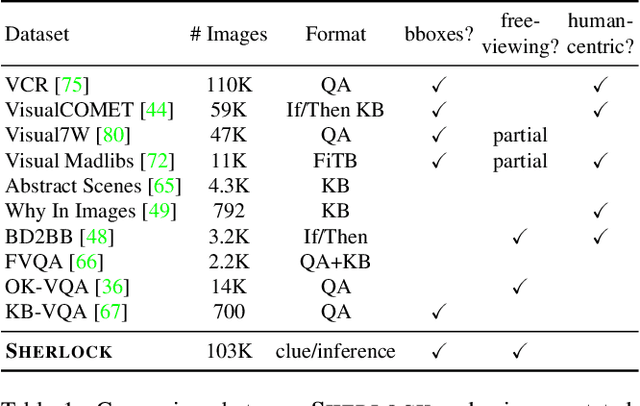

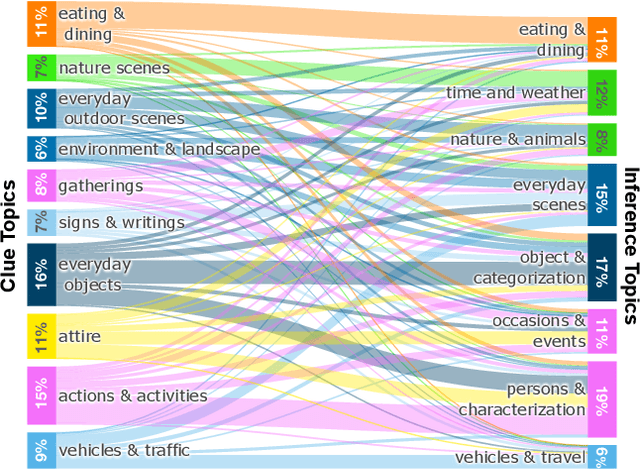
Humans have remarkable capacity to reason abductively and hypothesize about what lies beyond the literal content of an image. By identifying concrete visual clues scattered throughout a scene, we almost can't help but draw probable inferences beyond the literal scene based on our everyday experience and knowledge about the world. For example, if we see a "20 mph" sign alongside a road, we might assume the street sits in a residential area (rather than on a highway), even if no houses are pictured. Can machines perform similar visual reasoning? We present Sherlock, an annotated corpus of 103K images for testing machine capacity for abductive reasoning beyond literal image contents. We adopt a free-viewing paradigm: participants first observe and identify salient clues within images (e.g., objects, actions) and then provide a plausible inference about the scene, given the clue. In total, we collect 363K (clue, inference) pairs, which form a first-of-its-kind abductive visual reasoning dataset. Using our corpus, we test three complementary axes of abductive reasoning. We evaluate the capacity of models to: i) retrieve relevant inferences from a large candidate corpus; ii) localize evidence for inferences via bounding boxes, and iii) compare plausible inferences to match human judgments on a newly-collected diagnostic corpus of 19K Likert-scale judgments. While we find that fine-tuning CLIP-RN50x64 with a multitask objective outperforms strong baselines, significant headroom exists between model performance and human agreement. We provide analysis that points towards future work.
MERLOT Reserve: Neural Script Knowledge through Vision and Language and Sound
Jan 07, 2022
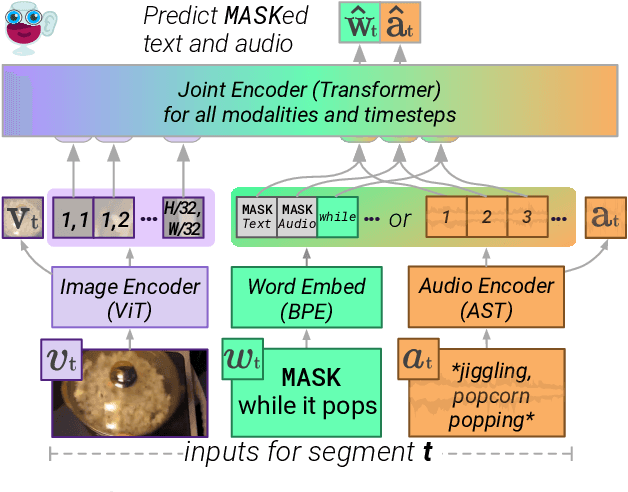

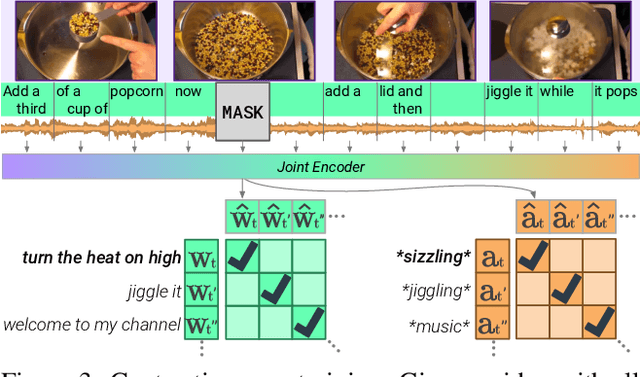
As humans, we navigate the world through all our senses, using perceptual input from each one to correct the others. We introduce MERLOT Reserve, a model that represents videos jointly over time -- through a new training objective that learns from audio, subtitles, and video frames. Given a video, we replace snippets of text and audio with a MASK token; the model learns by choosing the correct masked-out snippet. Our objective learns faster than alternatives, and performs well at scale: we pretrain on 20 million YouTube videos. Empirical results show that MERLOT Reserve learns strong representations about videos through all constituent modalities. When finetuned, it sets a new state-of-the-art on both VCR and TVQA, outperforming prior work by 5% and 7% respectively. Ablations show that both tasks benefit from audio pretraining -- even VCR, a QA task centered around images (without sound). Moreover, our objective enables out-of-the-box prediction, revealing strong multimodal commonsense understanding. In a fully zero-shot setting, our model obtains competitive results on four video understanding tasks, even outperforming supervised approaches on the recently proposed Situated Reasoning (STAR) benchmark. We analyze why incorporating audio leads to better vision-language representations, suggesting significant opportunities for future research. We conclude by discussing ethical and societal implications of multimodal pretraining.
Connecting the Dots between Audio and Text without Parallel Data through Visual Knowledge Transfer
Dec 16, 2021

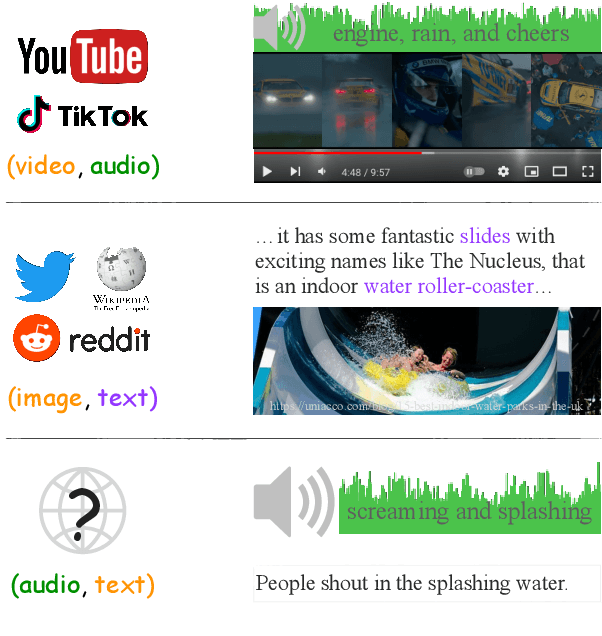

Machines that can represent and describe environmental soundscapes have practical potential, e.g., for audio tagging and captioning systems. Prevailing learning paradigms have been relying on parallel audio-text data, which is, however, scarcely available on the web. We propose VIP-ANT that induces \textbf{A}udio-\textbf{T}ext alignment without using any parallel audio-text data. Our key idea is to share the image modality between bi-modal image-text representations and bi-modal image-audio representations; the image modality functions as a pivot and connects audio and text in a tri-modal embedding space implicitly. In a difficult zero-shot setting with no paired audio-text data, our model demonstrates state-of-the-art zero-shot performance on the ESC50 and US8K audio classification tasks, and even surpasses the supervised state of the art for Clotho caption retrieval (with audio queries) by 2.2\% R@1. We further investigate cases of minimal audio-text supervision, finding that, e.g., just a few hundred supervised audio-text pairs increase the zero-shot audio classification accuracy by 8\% on US8K. However, to match human parity on some zero-shot tasks, our empirical scaling experiments suggest that we would need about $2^{21} \approx 2M$ supervised audio-caption pairs. Our work opens up new avenues for learning audio-text connections with little to no parallel audio-text data.
NeuroLogic A*esque Decoding: Constrained Text Generation with Lookahead Heuristics
Dec 16, 2021

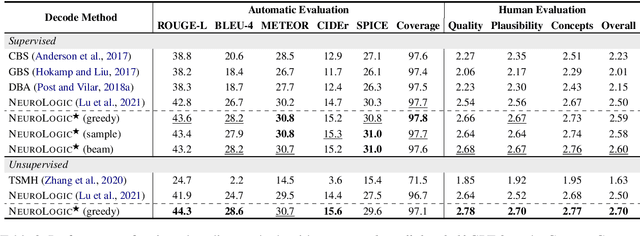
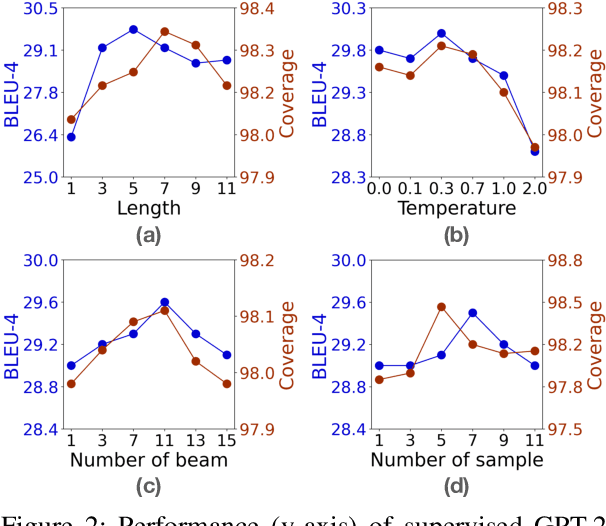
The dominant paradigm for neural text generation is left-to-right decoding from autoregressive language models. Constrained or controllable generation under complex lexical constraints, however, requires foresight to plan ahead feasible future paths. Drawing inspiration from the A* search algorithm, we propose NeuroLogic A*esque, a decoding algorithm that incorporates heuristic estimates of future cost. We develop efficient lookahead heuristics that are efficient for large-scale language models, making our method a drop-in replacement for common techniques such as beam search and top-k sampling. To enable constrained generation, we build on NeuroLogic decoding (Lu et al., 2021), combining its flexibility in incorporating logical constraints with A*esque estimates of future constraint satisfaction. Our approach outperforms competitive baselines on five generation tasks, and achieves new state-of-the-art performance on table-to-text generation, constrained machine translation, and keyword-constrained generation. The improvements are particularly notable on tasks that require complex constraint satisfaction or in few-shot or zero-shot settings. NeuroLogic A*esque illustrates the power of decoding for improving and enabling new capabilities of large-scale language models.
MERLOT: Multimodal Neural Script Knowledge Models
Jun 10, 2021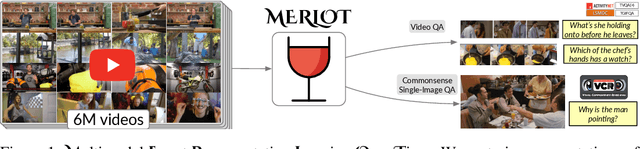
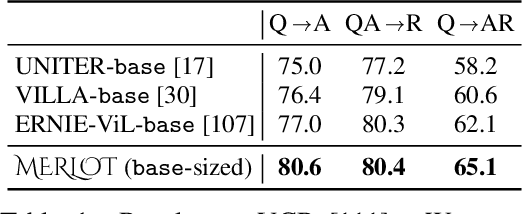
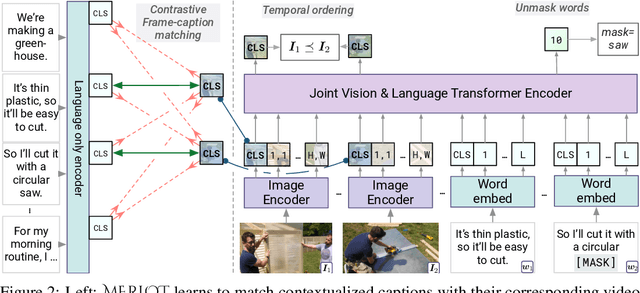
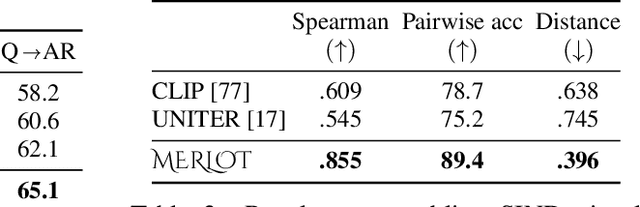
As humans, we understand events in the visual world contextually, performing multimodal reasoning across time to make inferences about the past, present, and future. We introduce MERLOT, a model that learns multimodal script knowledge by watching millions of YouTube videos with transcribed speech -- in an entirely label-free, self-supervised manner. By pretraining with a mix of both frame-level (spatial) and video-level (temporal) objectives, our model not only learns to match images to temporally corresponding words, but also to contextualize what is happening globally over time. As a result, MERLOT exhibits strong out-of-the-box representations of temporal commonsense, and achieves state-of-the-art performance on 12 different video QA datasets when finetuned. It also transfers well to the world of static images, allowing models to reason about the dynamic context behind visual scenes. On Visual Commonsense Reasoning, MERLOT answers questions correctly with 80.6% accuracy, outperforming state-of-the-art models of similar size by over 3%, even those that make heavy use of auxiliary supervised data (like object bounding boxes). Ablation analyses demonstrate the complementary importance of: 1) training on videos versus static images; 2) scaling the magnitude and diversity of the pretraining video corpus; and 3) using diverse objectives that encourage full-stack multimodal reasoning, from the recognition to cognition level.