 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Fetal Brain Tissue Annotation and Segmentation Challenge Results
Apr 20, 2022
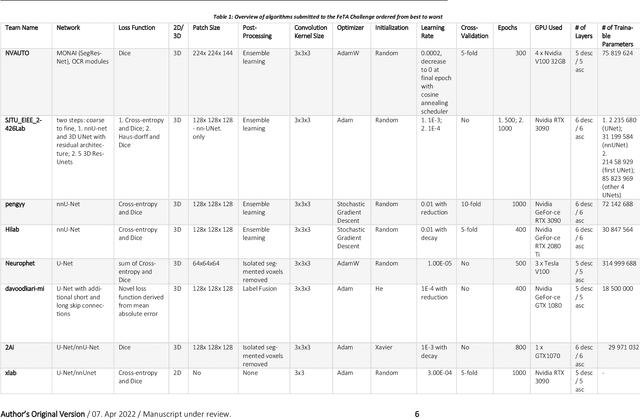
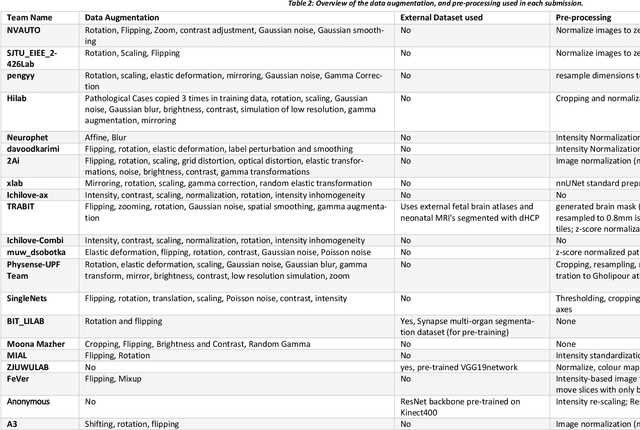
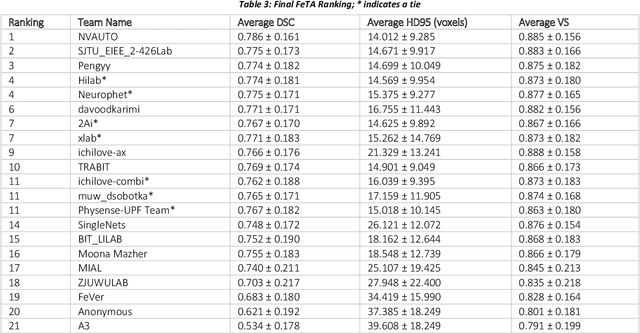
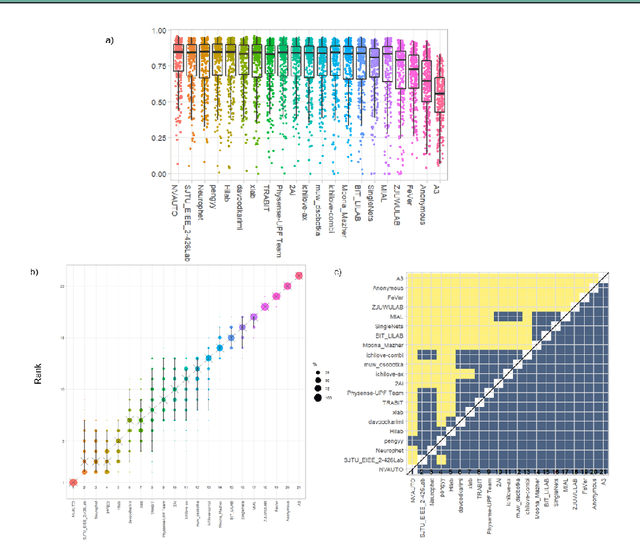
In-utero fetal MRI is emerging as an important tool in the diagnosis and analysis of the developing human brain. Automatic segmentation of the developing fetal brain is a vital step in the quantitative analysis of prenatal neurodevelopment both in the research and clinical context. However, manual segmentation of cerebral structures is time-consuming and prone to error and inter-observer variability. Therefore, we organized the Fetal Tissue Annotation (FeTA) Challenge in 2021 in order to encourage the development of automatic segmentation algorithms on an international level. The challenge utilized FeTA Dataset, an open dataset of fetal brain MRI reconstructions segmented into seven different tissues (external cerebrospinal fluid, grey matter, white matter, ventricles, cerebellum, brainstem, deep grey matter). 20 international teams participated in this challenge, submitting a total of 21 algorithms for evaluation. In this paper, we provide a detailed analysis of the results from both a technical and clinical perspective. All participants relied on deep learning methods, mainly U-Nets, with some variability present in the network architecture, optimization, and image pre- and post-processing. The majority of teams used existing medical imaging deep learning frameworks. The main differences between the submissions were the fine tuning done during training, and the specific pre- and post-processing steps performed. The challenge results showed that almost all submissions performed similarly. Four of the top five teams used ensemble learning methods. However, one team's algorithm performed significantly superior to the other submissions, and consisted of an asymmetrical U-Net network architecture. This paper provides a first of its kind benchmark for future automatic multi-tissue segmentation algorithms for the developing human brain in utero.
Neural Image Representations for Multi-Image Fusion and Layer Separation
Aug 24, 2021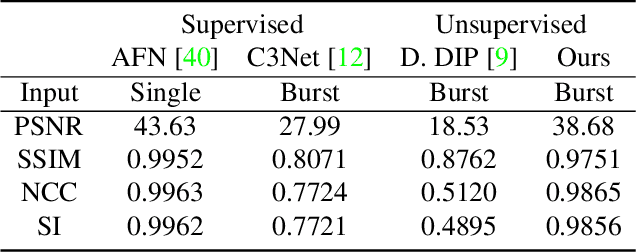
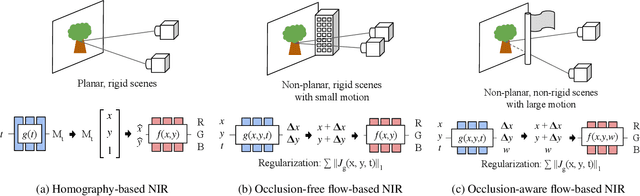
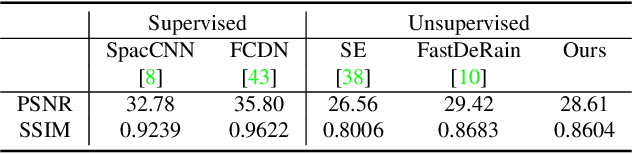
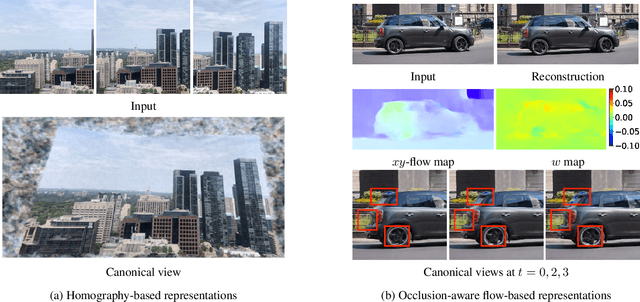
We propose a framework for aligning and fusing multiple images into a single coordinate-based neural representations. Our framework targets burst images that have misalignment due to camera ego motion and small changes in the scene. We describe different strategies for alignment depending on the assumption of the scene motion, namely, perspective planar (i.e., homography), optical flow with minimal scene change, and optical flow with notable occlusion and disocclusion. Our framework effectively combines the multiple inputs into a single neural implicit function without the need for selecting one of the images as a reference frame. We demonstrate how to use this multi-frame fusion framework for various layer separation tasks.
Review of Disentanglement Approaches for Medical Applications -- Towards Solving the Gordian Knot of Generative Models in Healthcare
Mar 21, 2022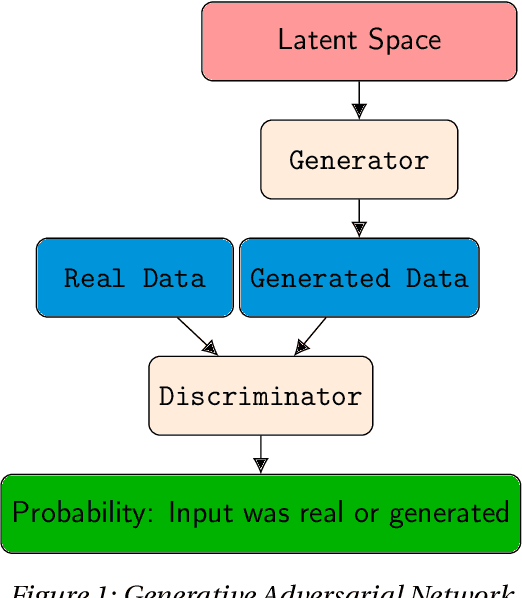
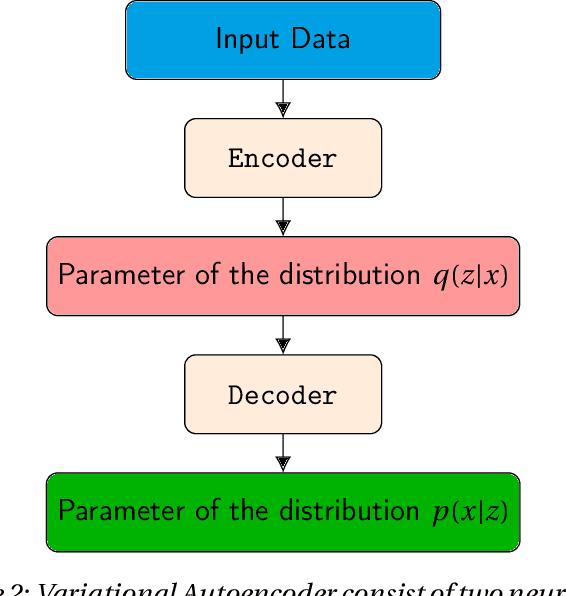
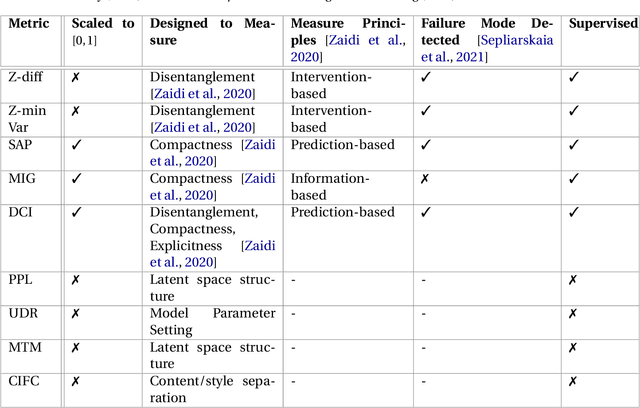
Deep neural networks are commonly used for medical purposes such as image generation, segmentation, or classification. Besides this, they are often criticized as black boxes as their decision process is often not human interpretable. Encouraging the latent representation of a generative model to be disentangled offers new perspectives of control and interpretability. Understanding the data generation process could help to create artificial medical data sets without violating patient privacy, synthesizing different data modalities, or discovering data generating characteristics. These characteristics might unravel novel relationships that can be related to genetic traits or patient outcomes. In this paper, we give a comprehensive overview of popular generative models, like Generative Adversarial Networks (GANs), Variational Autoencoders (VAEs), and Flow-based Models. Furthermore, we summarize the different notions of disentanglement, review approaches to disentangle latent space representations and metrics to evaluate the degree of disentanglement. After introducing the theoretical frameworks, we give an overview of recent medical applications and discuss the impact and importance of disentanglement approaches for medical applications.
Deep learning-assisted imaging through stationary scattering media
Feb 25, 2022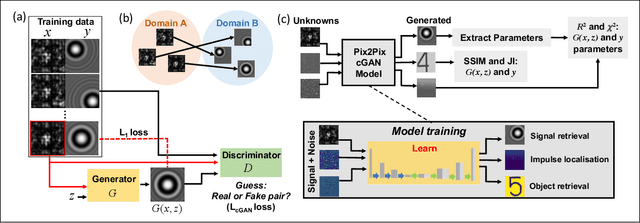
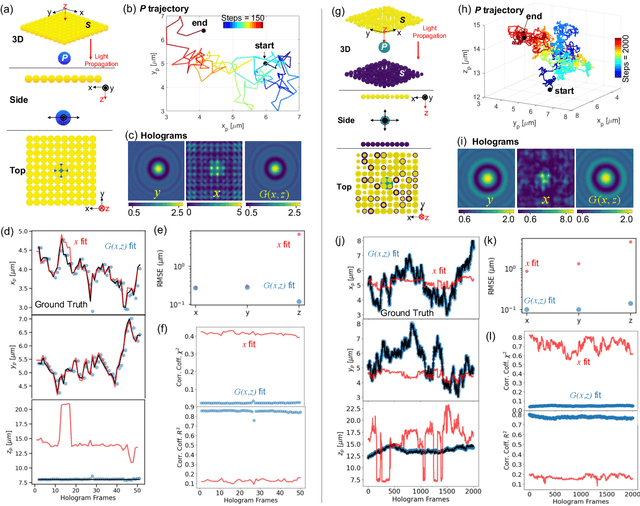
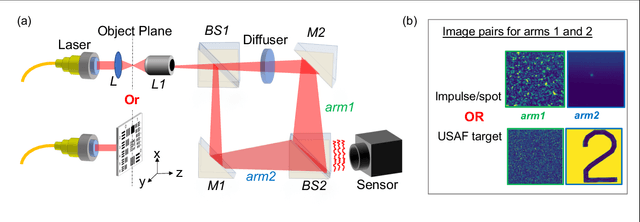
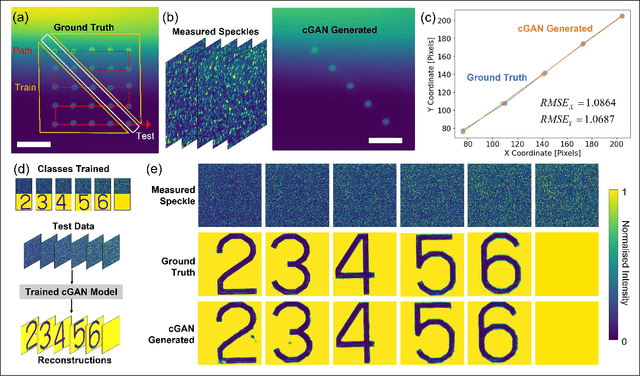
Imaging through scattering media is a challenging problem owing to speckle decorrelations from perturbations in the media itself. For in-line imaging modalities, which are appealing because they are compact, require no moving parts, and are robust, negating the effects of such scattering becomes particularly challenging. Here we explore the effect of stationary scattering media on light scattering in in-line geometries, including digital holographic microscopy. We consider various object-scatterer scenarios where the object is distorted or obscured by additional stationary scatterers, and use an advanced deep learning (DL) generative methodology, generative adversarial networks (GANs), to mitigate the effects of the additional scatterers. Using light scattering simulations and experiments on objects of interest with and without additional scatterers, we find that conditional GANs can be quickly trained with minuscule datasets and can also efficiently learn the one-to-one statistical mapping between the cross-domain input-output image pairs. Training such a network yields a standalone model, that can be used later to inverse or negate the effect of scattering, yielding clear object reconstructions for object retrieval and downstream processing. Moreover, it is well-known that the coherent point spread function (c-PSF) of a stationary scattering optical system is a speckle pattern which is spatially shift variant. We show that with rapid training using only 20 image pairs, it is possible to negate this undesired scattering to accurately localize diffraction-limited impulses with high spatial accuracy, therefore transforming the earlier shift variant system to a linear shift invariant (LSI) system.
Sensing accident-prone features in urban scenes for proactive driving and accident prevention
Feb 25, 2022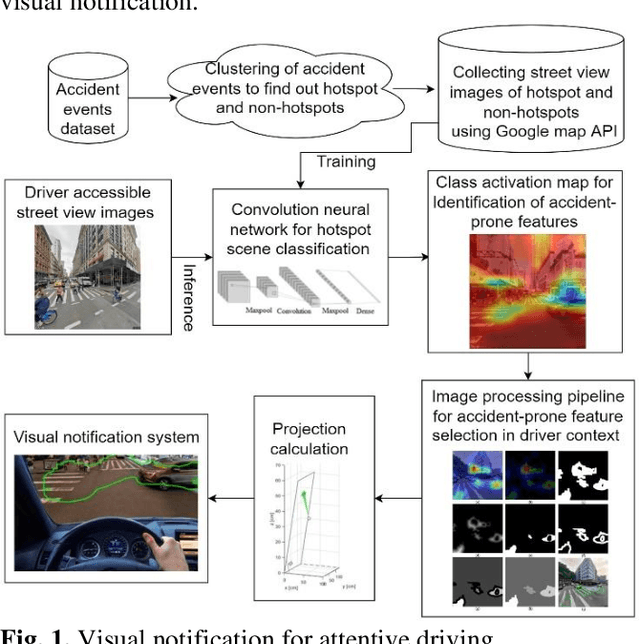
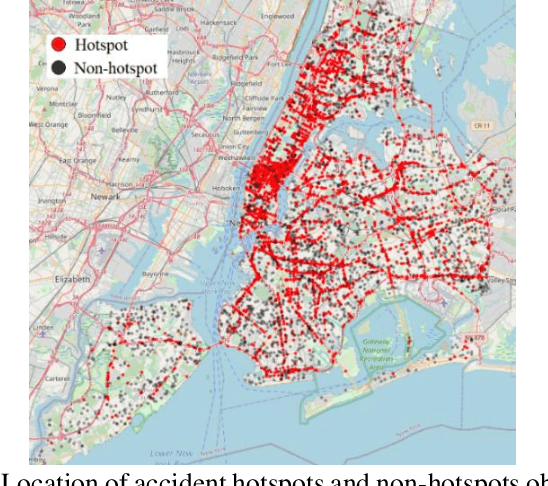
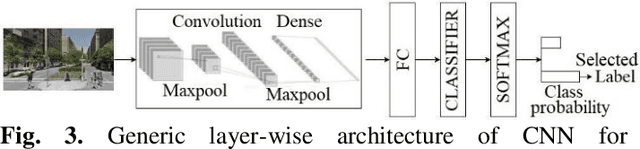

In urban cities, visual information along and on roadways is likely to distract drivers and leads to missing traffic signs and other accident-prone features. As a solution to avoid accidents due to missing these visual cues, this paper proposes a visual notification of accident-prone features to drivers, based on real-time images obtained via dashcam. For this purpose, Google Street View images around accident hotspots (areas of dense accident occurrence) identified by accident dataset are used to train a family of deep convolutional neural networks (CNNs). Trained CNNs are able to detect accident-prone features and classify a given urban scene into an accident hotspot and a non-hotspot (area of sparse accident occurrence). For given accident hotspot, the trained CNNs can classify it into an accident hotspot with the accuracy up to 90%. The capability of detecting accident-prone features by the family of CNNs is analyzed by a comparative study of four different class activation map (CAM) methods, which are used to inspect specific accident-prone features causing the decision of CNNs, and pixel-level object class classification. The outputs of CAM methods are processed by an image processing pipeline to extract only the accident-prone features that are explainable to drivers with the help of visual notification system. To prove the efficacy of accident-prone features, an ablation study is conducted. Ablation of accident-prone features taking 7.7%, on average, of total area in each image sample causes up to 13.7% more chance of given area to be classified as a non-hotspot.
Semantic Feature Extraction for Generalized Zero-shot Learning
Dec 29, 2021

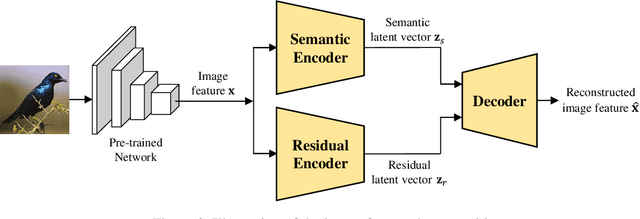
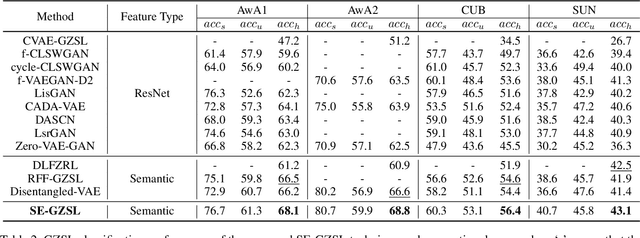
Generalized zero-shot learning (GZSL) is a technique to train a deep learning model to identify unseen classes using the attribute. In this paper, we put forth a new GZSL technique that improves the GZSL classification performance greatly. Key idea of the proposed approach, henceforth referred to as semantic feature extraction-based GZSL (SE-GZSL), is to use the semantic feature containing only attribute-related information in learning the relationship between the image and the attribute. In doing so, we can remove the interference, if any, caused by the attribute-irrelevant information contained in the image feature. To train a network extracting the semantic feature, we present two novel loss functions, 1) mutual information-based loss to capture all the attribute-related information in the image feature and 2) similarity-based loss to remove unwanted attribute-irrelevant information. From extensive experiments using various datasets, we show that the proposed SE-GZSL technique outperforms conventional GZSL approaches by a large margin.
TuiGAN: Learning Versatile Image-to-Image Translation with Two Unpaired Images
Apr 09, 2020

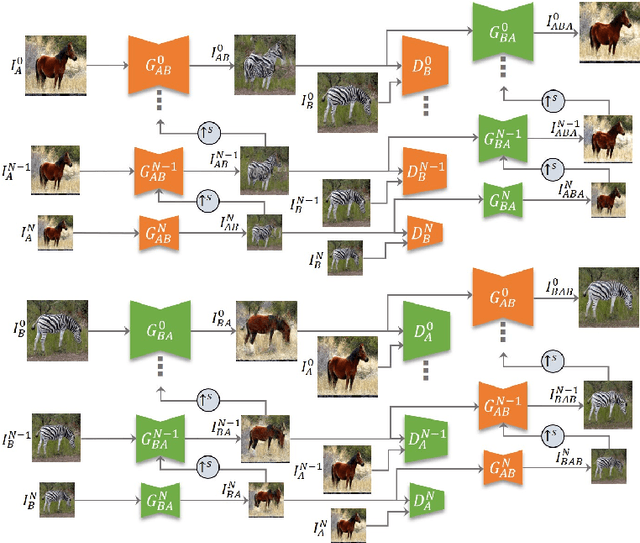
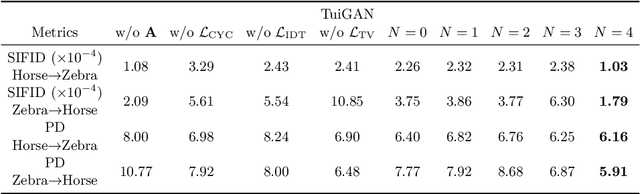
An unsupervised image-to-image translation (UI2I) task deals with learning a mapping between two domains without paired images. While existing UI2I methods usually require numerous unpaired images from different domains for training, there are many scenarios where training data is quite limited. In this paper, we argue that even if each domain contains a single image, UI2I can still be achieved. To this end, we propose TuiGAN, a generative model that is trained on only two unpaired images and amounts to one-shot unsupervised learning. With TuiGAN, an image is translated in a coarse-to-fine manner where the generated image is gradually refined from global structures to local details. We conduct extensive experiments to verify that our versatile method can outperform strong baselines on a wide variety of UI2I tasks. Moreover, TuiGAN is capable of achieving comparable performance with the state-of-the-art UI2I models trained with sufficient data.
MuSCLe: A Multi-Strategy Contrastive Learning Framework for Weakly Supervised Semantic Segmentation
Jan 18, 2022Weakly supervised semantic segmentation (WSSS) has gained significant popularity since it relies only on weak labels such as image level annotations rather than pixel level annotations required by supervised semantic segmentation (SSS) methods. Despite drastically reduced annotation costs, typical feature representations learned from WSSS are only representative of some salient parts of objects and less reliable compared to SSS due to the weak guidance during training. In this paper, we propose a novel Multi-Strategy Contrastive Learning (MuSCLe) framework to obtain enhanced feature representations and improve WSSS performance by exploiting similarity and dissimilarity of contrastive sample pairs at image, region, pixel and object boundary levels. Extensive experiments demonstrate the effectiveness of our method and show that MuSCLe outperforms the current state-of-the-art on the widely used PASCAL VOC 2012 dataset.
Real-time Hyperspectral Imaging in Hardware via Trained Metasurface Encoders
Apr 05, 2022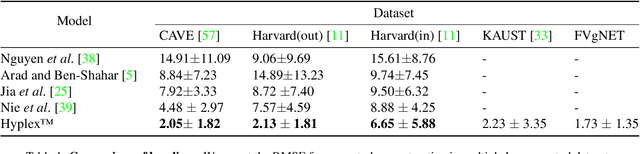

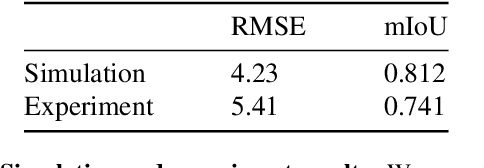
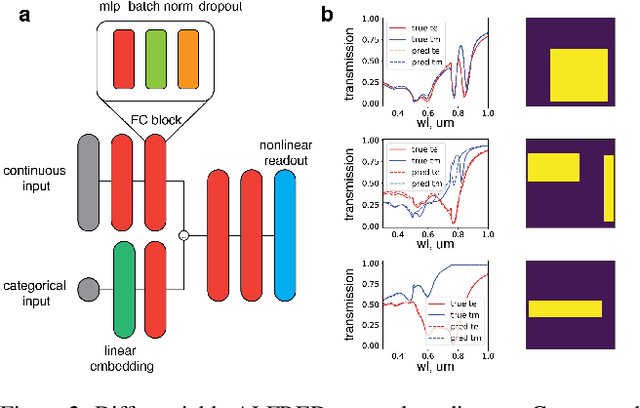
Hyperspectral imaging has attracted significant attention to identify spectral signatures for image classification and automated pattern recognition in computer vision. State-of-the-art implementations of snapshot hyperspectral imaging rely on bulky, non-integrated, and expensive optical elements, including lenses, spectrometers, and filters. These macroscopic components do not allow fast data processing for, e.g real-time and high-resolution videos. This work introduces Hyplex, a new integrated architecture addressing the limitations discussed above. Hyplex is a CMOS-compatible, fast hyperspectral camera that replaces bulk optics with nanoscale metasurfaces inversely designed through artificial intelligence. Hyplex does not require spectrometers but makes use of conventional monochrome cameras, opening up the possibility for real-time and high-resolution hyperspectral imaging at inexpensive costs. Hyplex exploits a model-driven optimization, which connects the physical metasurfaces layer with modern visual computing approaches based on end-to-end training. We design and implement a prototype version of Hyplex and compare its performance against the state-of-the-art for typical imaging tasks such as spectral reconstruction and semantic segmentation. In all benchmarks, Hyplex reports the smallest reconstruction error. We additionally present what is, to the best of our knowledge, the largest publicly available labeled hyperspectral dataset for semantic segmentation.
Deep Artifact-Free Residual Network for Single Image Super-Resolution
Sep 25, 2020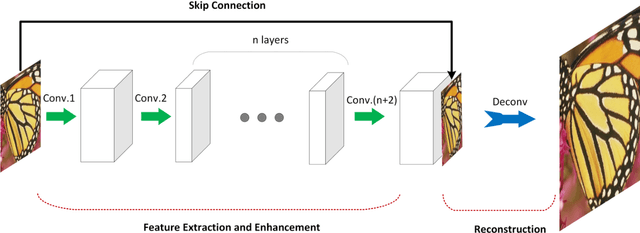
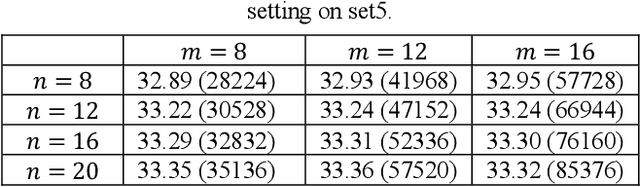
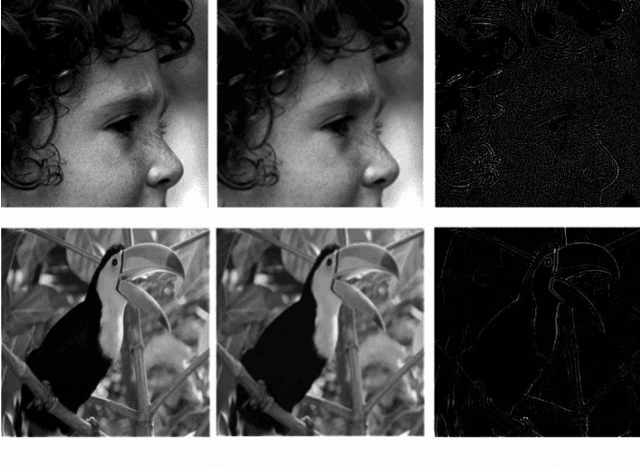
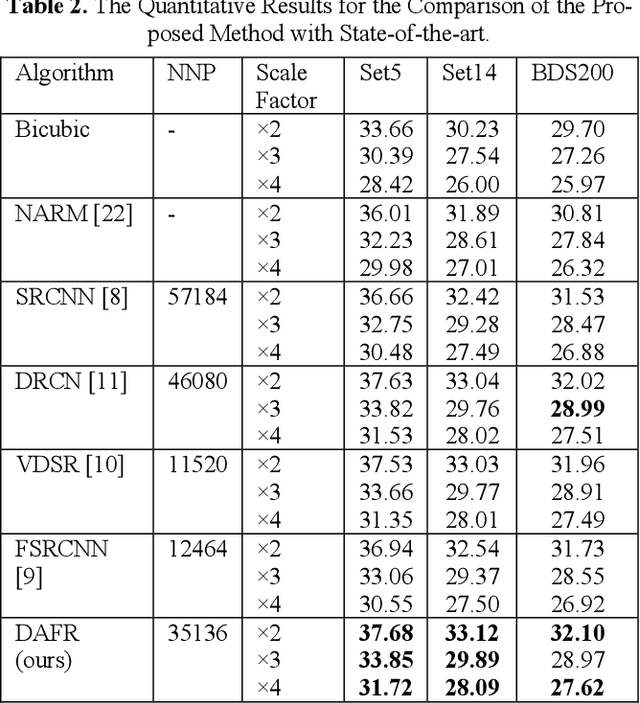
Recently, convolutional neural networks have shown promising performance for single-image super-resolution. In this paper, we propose Deep Artifact-Free Residual (DAFR) network which uses the merits of both residual learning and usage of ground-truth image as target. Our framework uses a deep model to extract the high-frequency information which is necessary for high-quality image reconstruction. We use a skip-connection to feed the low-resolution image to the network before the image reconstruction. In this way, we are able to use the ground-truth images as target and avoid misleading the network due to artifacts in difference image. In order to extract clean high-frequency information, we train the network in two steps. The first step is a traditional residual learning which uses the difference image as target. Then, the trained parameters of this step are transferred to the main training in the second step. Our experimental results show that the proposed method achieves better quantitative and qualitative image quality compared to the existing methods.
* 8 pages