 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCARMIL: Context-Aware Regularization on Multiple Instance Learning models for Whole Slide Images
Aug 01, 2024



Multiple Instance Learning (MIL) models have proven effective for cancer prognosis from Whole Slide Images. However, the original MIL formulation incorrectly assumes the patches of the same image to be independent, leading to a loss of spatial context as information flows through the network. Incorporating contextual knowledge into predictions is particularly important given the inclination for cancerous cells to form clusters and the presence of spatial indicators for tumors. State-of-the-art methods often use attention mechanisms eventually combined with graphs to capture spatial knowledge. In this paper, we take a novel and transversal approach, addressing this issue through the lens of regularization. We propose Context-Aware Regularization for Multiple Instance Learning (CARMIL), a versatile regularization scheme designed to seamlessly integrate spatial knowledge into any MIL model. Additionally, we present a new and generic metric to quantify the Context-Awareness of any MIL model when applied to Whole Slide Images, resolving a previously unexplored gap in the field. The efficacy of our framework is evaluated for two survival analysis tasks on glioblastoma (TCGA GBM) and colon cancer data (TCGA COAD).
Trustworthy Deep Learning for Medical Image Segmentation
May 27, 2023Despite the recent success of deep learning methods at achieving new state-of-the-art accuracy for medical image segmentation, some major limitations are still restricting their deployment into clinics. One major limitation of deep learning-based segmentation methods is their lack of robustness to variability in the image acquisition protocol and in the imaged anatomy that were not represented or were underrepresented in the training dataset. This suggests adding new manually segmented images to the training dataset to better cover the image variability. However, in most cases, the manual segmentation of medical images requires highly skilled raters and is time-consuming, making this solution prohibitively expensive. Even when manually segmented images from different sources are available, they are rarely annotated for exactly the same regions of interest. This poses an additional challenge for current state-of-the-art deep learning segmentation methods that rely on supervised learning and therefore require all the regions of interest to be segmented for all the images to be used for training. This thesis introduces new mathematical and optimization methods to mitigate those limitations.
Biomedical image analysis competitions: The state of current participation practice
Dec 16, 2022The number of international benchmarking competitions is steadily increasing in various fields of machine learning (ML) research and practice. So far, however, little is known about the common practice as well as bottlenecks faced by the community in tackling the research questions posed. To shed light on the status quo of algorithm development in the specific field of biomedical imaging analysis, we designed an international survey that was issued to all participants of challenges conducted in conjunction with the IEEE ISBI 2021 and MICCAI 2021 conferences (80 competitions in total). The survey covered participants' expertise and working environments, their chosen strategies, as well as algorithm characteristics. A median of 72% challenge participants took part in the survey. According to our results, knowledge exchange was the primary incentive (70%) for participation, while the reception of prize money played only a minor role (16%). While a median of 80 working hours was spent on method development, a large portion of participants stated that they did not have enough time for method development (32%). 25% perceived the infrastructure to be a bottleneck. Overall, 94% of all solutions were deep learning-based. Of these, 84% were based on standard architectures. 43% of the respondents reported that the data samples (e.g., images) were too large to be processed at once. This was most commonly addressed by patch-based training (69%), downsampling (37%), and solving 3D analysis tasks as a series of 2D tasks. K-fold cross-validation on the training set was performed by only 37% of the participants and only 50% of the participants performed ensembling based on multiple identical models (61%) or heterogeneous models (39%). 48% of the respondents applied postprocessing steps.
Deep Quality Estimation: Creating Surrogate Models for Human Quality Ratings
May 17, 2022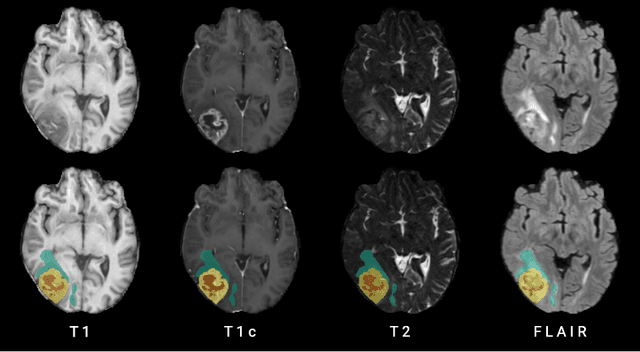
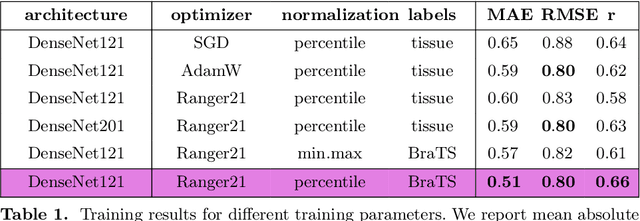
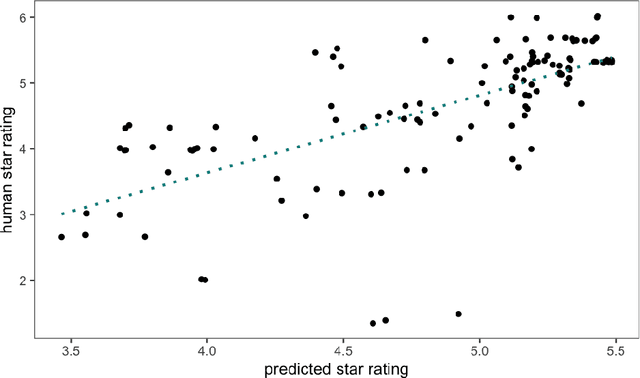
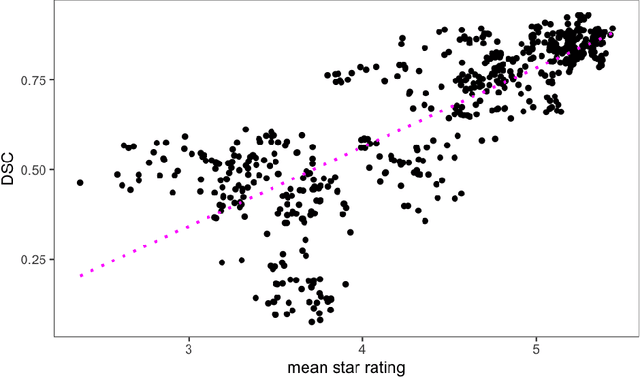
Human ratings are abstract representations of segmentation quality. To approximate human quality ratings on scarce expert data, we train surrogate quality estimation models. We evaluate on a complex multi-class segmentation problem, specifically glioma segmentation following the BraTS annotation protocol. The training data features quality ratings from 15 expert neuroradiologists on a scale ranging from 1 to 6 stars for various computer-generated and manual 3D annotations. Even though the networks operate on 2D images and with scarce training data, we can approximate segmentation quality within a margin of error comparable to human intra-rater reliability. Segmentation quality prediction has broad applications. While an understanding of segmentation quality is imperative for successful clinical translation of automatic segmentation quality algorithms, it can play an essential role in training new segmentation models. Due to the split-second inference times, it can be directly applied within a loss function or as a fully-automatic dataset curation mechanism in a federated learning setting.
blob loss: instance imbalance aware loss functions for semantic segmentation
May 17, 2022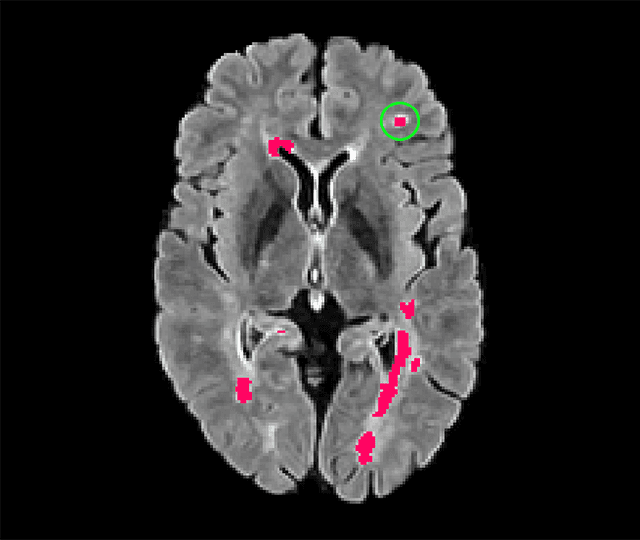
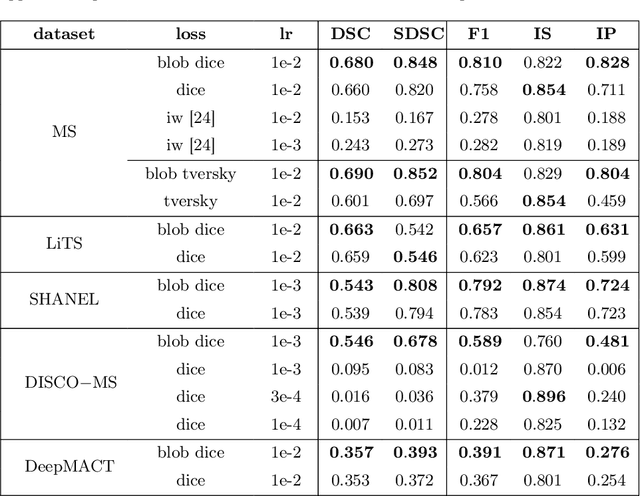

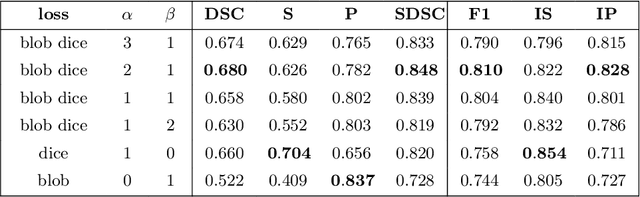
Deep convolutional neural networks have proven to be remarkably effective in semantic segmentation tasks. Most popular loss functions were introduced targeting improved volumetric scores, such as the Sorensen Dice coefficient. By design, DSC can tackle class imbalance; however, it does not recognize instance imbalance within a class. As a result, a large foreground instance can dominate minor instances and still produce a satisfactory Sorensen Dice coefficient. Nevertheless, missing out on instances will lead to poor detection performance. This represents a critical issue in applications such as disease progression monitoring. For example, it is imperative to locate and surveil small-scale lesions in the follow-up of multiple sclerosis patients. We propose a novel family of loss functions, nicknamed blob loss, primarily aimed at maximizing instance-level detection metrics, such as F1 score and sensitivity. Blob loss is designed for semantic segmentation problems in which the instances are the connected components within a class. We extensively evaluate a DSC-based blob loss in five complex 3D semantic segmentation tasks featuring pronounced instance heterogeneity in terms of texture and morphology. Compared to soft Dice loss, we achieve 5 percent improvement for MS lesions, 3 percent improvement for liver tumor, and an average 2 percent improvement for Microscopy segmentation tasks considering F1 score.
Fetal Brain Tissue Annotation and Segmentation Challenge Results
Apr 20, 2022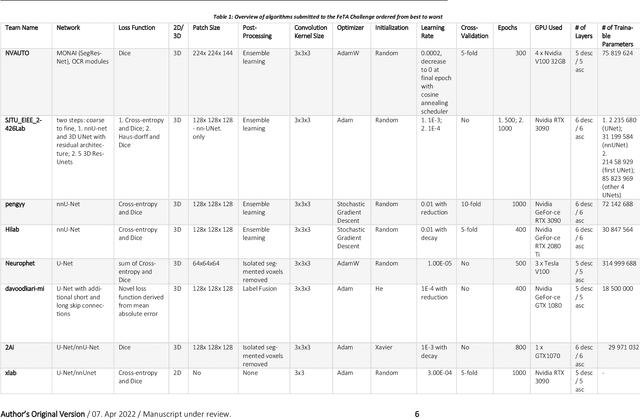
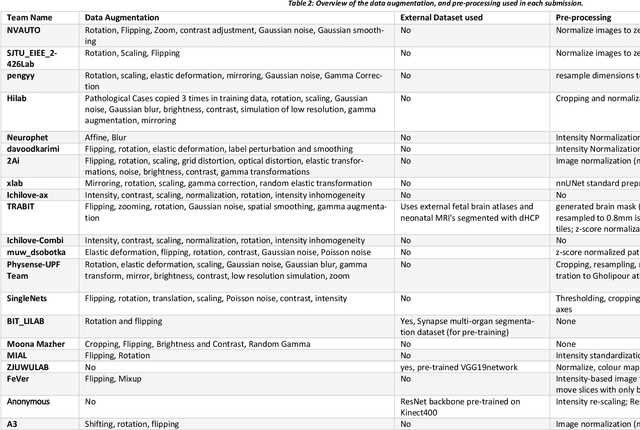
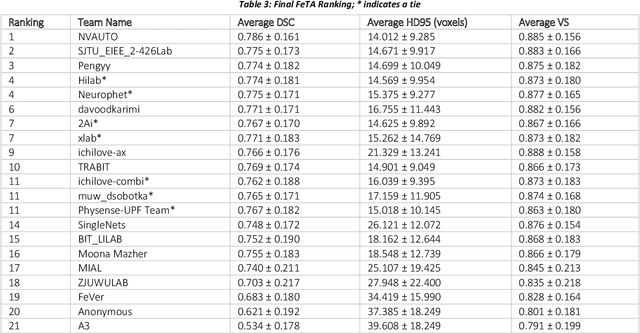
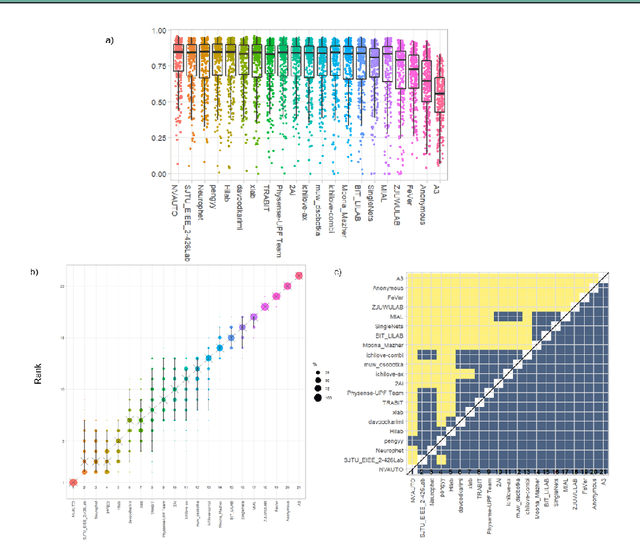
In-utero fetal MRI is emerging as an important tool in the diagnosis and analysis of the developing human brain. Automatic segmentation of the developing fetal brain is a vital step in the quantitative analysis of prenatal neurodevelopment both in the research and clinical context. However, manual segmentation of cerebral structures is time-consuming and prone to error and inter-observer variability. Therefore, we organized the Fetal Tissue Annotation (FeTA) Challenge in 2021 in order to encourage the development of automatic segmentation algorithms on an international level. The challenge utilized FeTA Dataset, an open dataset of fetal brain MRI reconstructions segmented into seven different tissues (external cerebrospinal fluid, grey matter, white matter, ventricles, cerebellum, brainstem, deep grey matter). 20 international teams participated in this challenge, submitting a total of 21 algorithms for evaluation. In this paper, we provide a detailed analysis of the results from both a technical and clinical perspective. All participants relied on deep learning methods, mainly U-Nets, with some variability present in the network architecture, optimization, and image pre- and post-processing. The majority of teams used existing medical imaging deep learning frameworks. The main differences between the submissions were the fine tuning done during training, and the specific pre- and post-processing steps performed. The challenge results showed that almost all submissions performed similarly. Four of the top five teams used ensemble learning methods. However, one team's algorithm performed significantly superior to the other submissions, and consisted of an asymmetrical U-Net network architecture. This paper provides a first of its kind benchmark for future automatic multi-tissue segmentation algorithms for the developing human brain in utero.
A Dempster-Shafer approach to trustworthy AI with application to fetal brain MRI segmentation
Apr 05, 2022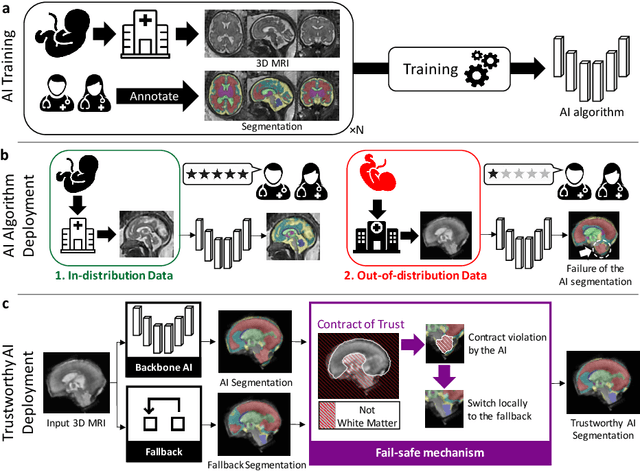
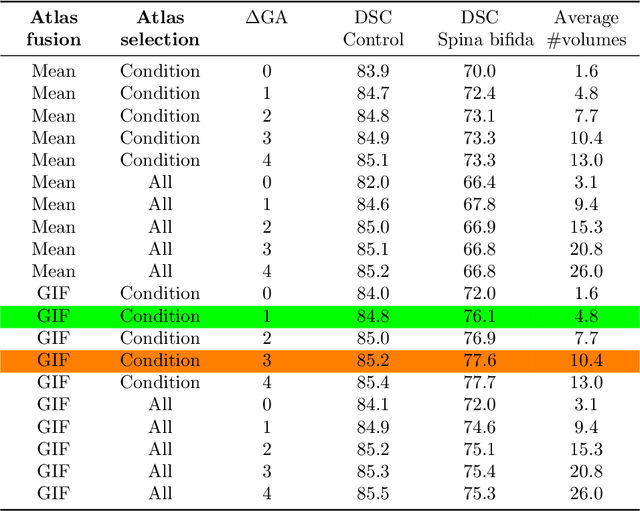
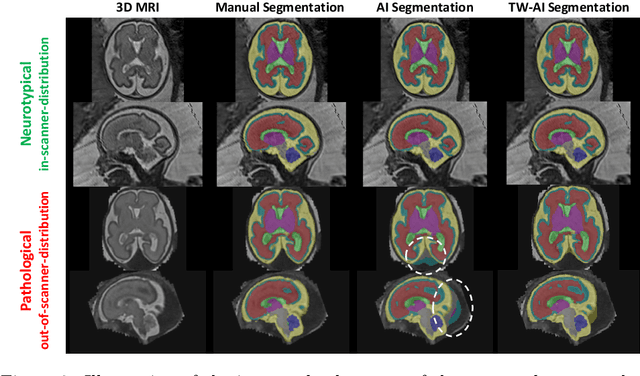
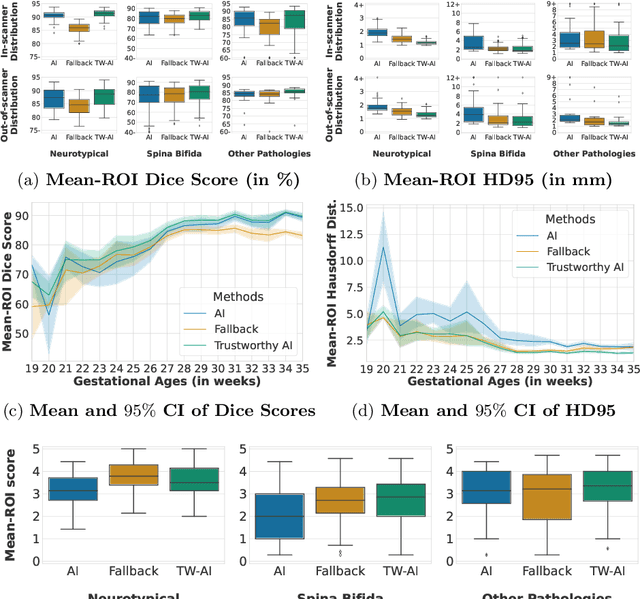
Deep learning models for medical image segmentation can fail unexpectedly and spectacularly for pathological cases and for images acquired at different centers than those used for training, with labeling errors that violate expert knowledge about the anatomy and the intensity distribution of the regions to be segmented. Such errors undermine the trustworthiness of deep learning models developed for medical image segmentation. Mechanisms with a fallback method for detecting and correcting such failures are essential for safely translating this technology into clinics and are likely to be a requirement of future regulations on artificial intelligence (AI). Here, we propose a principled trustworthy AI theoretical framework and a practical system that can augment any backbone AI system using a fallback method and a fail-safe mechanism based on Dempster-Shafer theory. Our approach relies on an actionable definition of trustworthy AI. Our method automatically discards the voxel-level labeling predicted by the backbone AI that are likely to violate expert knowledge and relies on a fallback atlas-based segmentation method for those voxels. We demonstrate the effectiveness of the proposed trustworthy AI approach on the largest reported annotated dataset of fetal T2w MRI consisting of 540 manually annotated fetal brain 3D MRIs with neurotypical or abnormal brain development and acquired from 13 sources of data across 6 countries. We show that our trustworthy AI method improves the robustness of a state-of-the-art backbone AI for fetal brain MRI segmentation on MRIs acquired across various centers and for fetuses with various brain abnormalities.
ECONet: Efficient Convolutional Online Likelihood Network for Scribble-based Interactive Segmentation
Feb 08, 2022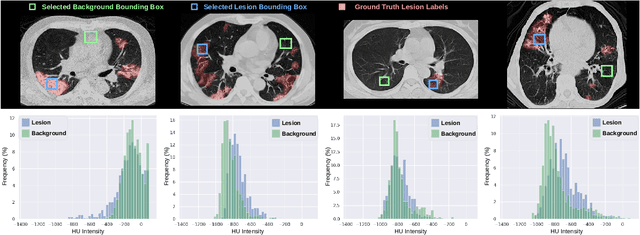

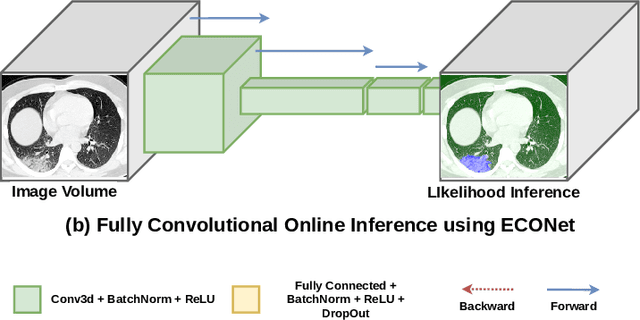
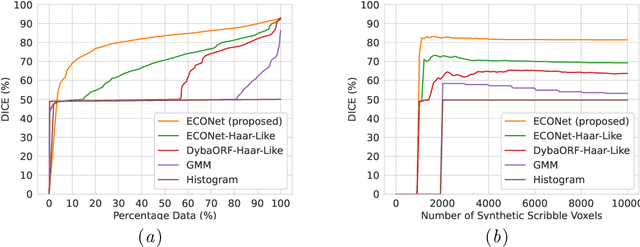
Automatic segmentation of lung lesions associated with COVID-19 in CT images requires large amount of annotated volumes. Annotations mandate expert knowledge and are time-intensive to obtain through fully manual segmentation methods. Additionally, lung lesions have large inter-patient variations, with some pathologies having similar visual appearance as healthy lung tissues. This poses a challenge when applying existing semi-automatic interactive segmentation techniques for data labelling. To address these challenges, we propose an efficient convolutional neural networks (CNNs) that can be learned online while the annotator provides scribble-based interaction. To accelerate learning from only the samples labelled through user-interactions, a patch-based approach is used for training the network. Moreover, we use weighted cross-entropy loss to address the class imbalance that may result from user-interactions. During online inference, the learned network is applied to the whole input volume using a fully convolutional approach. We compare our proposed method with state-of-the-art using synthetic scribbles and show that it outperforms existing methods on the task of annotating lung lesions associated with COVID-19, achieving 16% higher Dice score while reducing execution time by 3$\times$ and requiring 9000 lesser scribbles-based labelled voxels. Due to the online learning aspect, our approach adapts quickly to user input, resulting in high quality segmentation labels. Source code for ECONet is available at: https://github.com/masadcv/ECONet-MONAILabel
Generalized Wasserstein Dice Loss, Test-time Augmentation, and Transformers for the BraTS 2021 challenge
Dec 24, 2021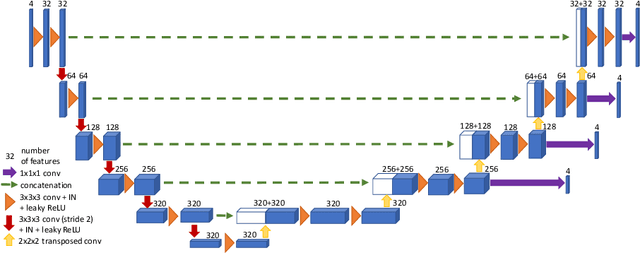
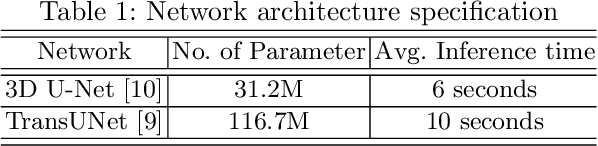
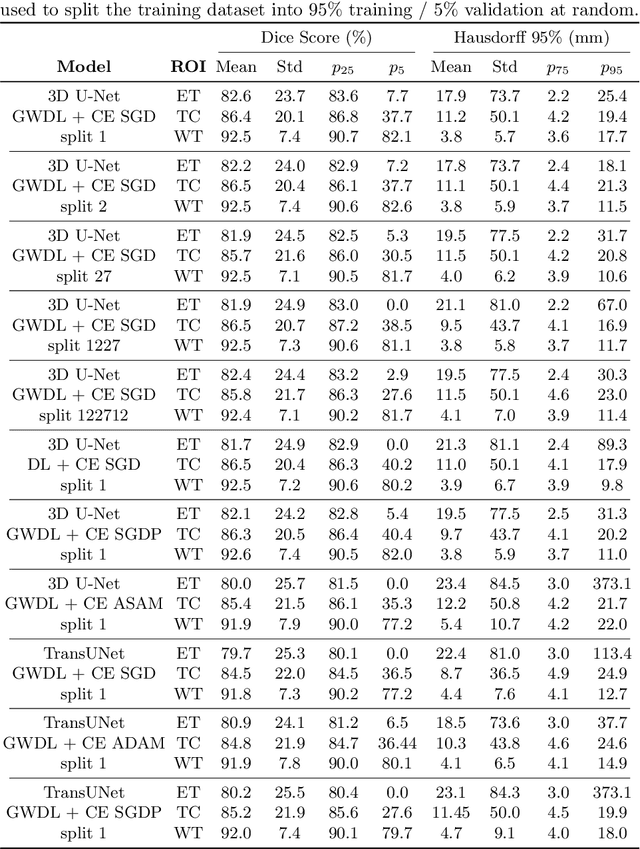
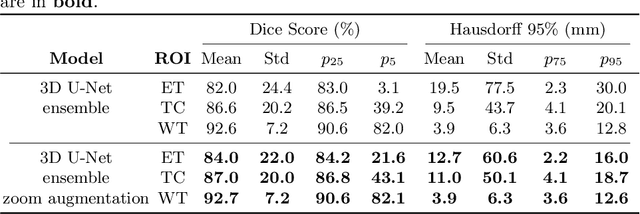
Brain tumor segmentation from multiple Magnetic Resonance Imaging (MRI) modalities is a challenging task in medical image computation. The main challenges lie in the generalizability to a variety of scanners and imaging protocols. In this paper, we explore strategies to increase model robustness without increasing inference time. Towards this aim, we explore finding a robust ensemble from models trained using different losses, optimizers, and train-validation data split. Importantly, we explore the inclusion of a transformer in the bottleneck of the U-Net architecture. While we find transformer in the bottleneck performs slightly worse than the baseline U-Net in average, the generalized Wasserstein Dice loss consistently produces superior results. Further, we adopt an efficient test time augmentation strategy for faster and robust inference. Our final ensemble of seven 3D U-Nets with test-time augmentation produces an average dice score of 89.4% and an average Hausdorff 95% distance of 10.0 mm when evaluated on the BraTS 2021 testing dataset. Our code and trained models are publicly available at https://github.com/LucasFidon/TRABIT_BraTS2021.
Partial supervision for the FeTA challenge 2021
Nov 03, 2021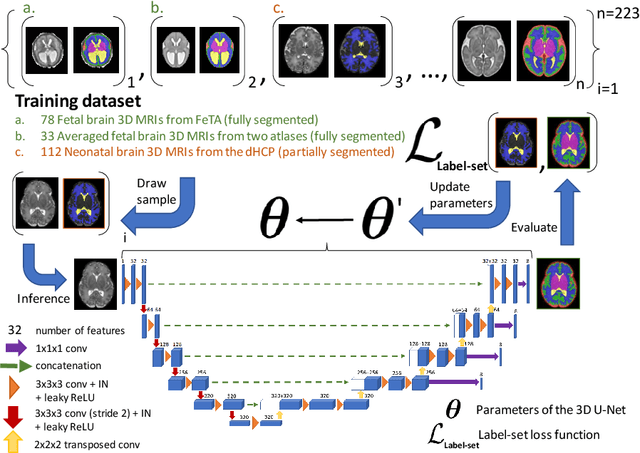
This paper describes our method for our participation in the FeTA challenge2021 (team name: TRABIT). The performance of convolutional neural networks for medical image segmentation is thought to correlate positively with the number of training data. The FeTA challenge does not restrict participants to using only the provided training data but also allows for using other publicly available sources. Yet, open access fetal brain data remains limited. An advantageous strategy could thus be to expand the training data to cover broader perinatal brain imaging sources. Perinatal brain MRIs, other than the FeTA challenge data, that are currently publicly available, span normal and pathological fetal atlases as well as neonatal scans. However, perinatal brain MRIs segmented in different datasets typically come with different annotation protocols. This makes it challenging to combine those datasets to train a deep neural network. We recently proposed a family of loss functions, the label-set loss functions, for partially supervised learning. Label-set loss functions allow to train deep neural networks with partially segmented images, i.e. segmentations in which some classes may be grouped into super-classes. We propose to use label-set loss functions to improve the segmentation performance of a state-of-the-art deep learning pipeline for multi-class fetal brain segmentation by merging several publicly available datasets. To promote generalisability, our approach does not introduce any additional hyper-parameters tuning.