 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Introduction of Medical Imaging Modalities
Jun 07, 2023
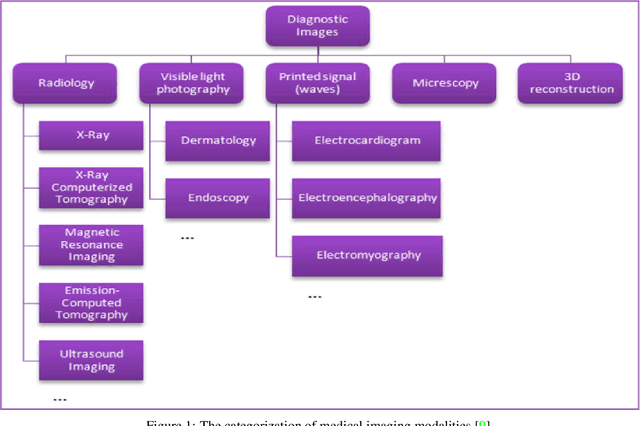
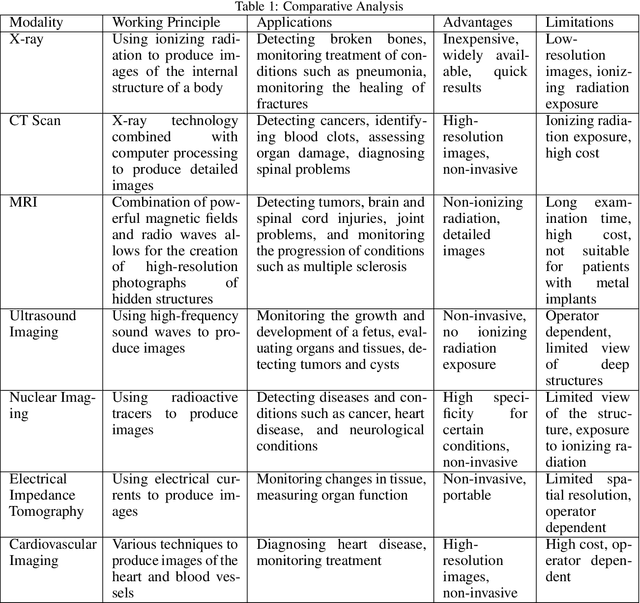
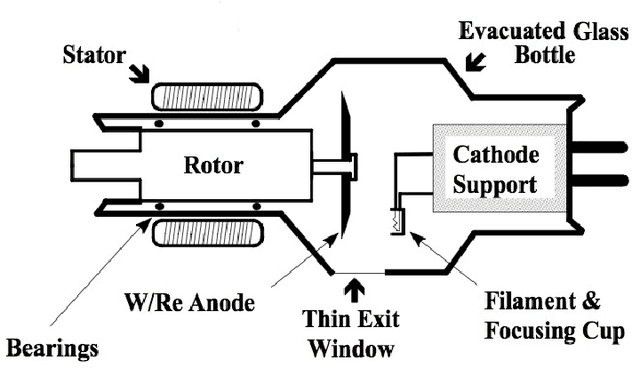
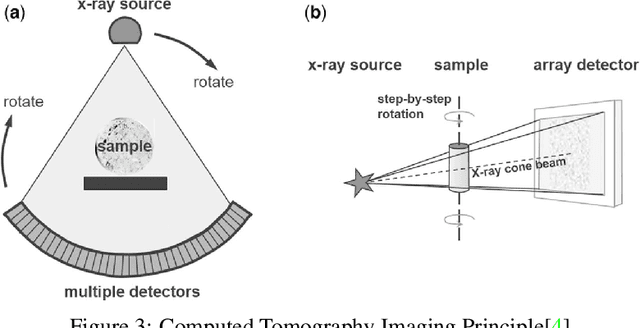
The diagnosis and treatment of various diseases had been expedited with the help of medical imaging. Different medical imaging modalities, including X-ray, Computed Tomography (CT), Magnetic Resonance Imaging (MRI), Nuclear Imaging, Ultrasound, Electrical Impedance Tomography (EIT), and Emerging Technologies for in vivo imaging modalities is presented in this chapter, in addition to these modalities, some advanced techniques such as contrast-enhanced MRI, MR approaches for osteoarthritis, Cardiovascular Imaging, and Medical Imaging data mining and search. Despite its important role and potential effectiveness as a diagnostic tool, reading and interpreting medical images by radiologists is often tedious and difficult due to the large heterogeneity of diseases and the limitation of image quality or resolution. Besides the introduction and discussion of the basic principles, typical clinical applications, advantages, and limitations of each modality used in current clinical practice, this chapter also highlights the importance of emerging technologies in medical imaging and the role of data mining and search aiming to support translational clinical research, improve patient care, and increase the efficiency of the healthcare system.
SimpleNet: A Simple Network for Image Anomaly Detection and Localization
Mar 28, 2023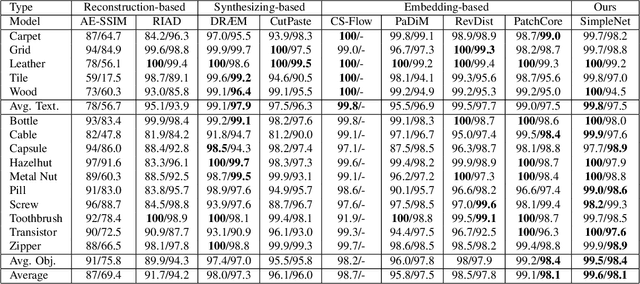
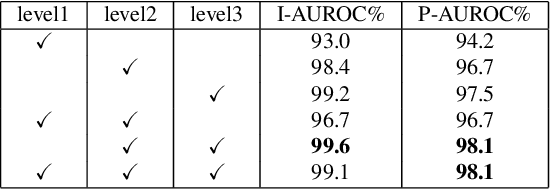
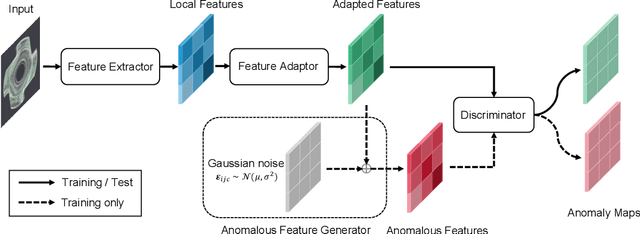

We propose a simple and application-friendly network (called SimpleNet) for detecting and localizing anomalies. SimpleNet consists of four components: (1) a pre-trained Feature Extractor that generates local features, (2) a shallow Feature Adapter that transfers local features towards target domain, (3) a simple Anomaly Feature Generator that counterfeits anomaly features by adding Gaussian noise to normal features, and (4) a binary Anomaly Discriminator that distinguishes anomaly features from normal features. During inference, the Anomaly Feature Generator would be discarded. Our approach is based on three intuitions. First, transforming pre-trained features to target-oriented features helps avoid domain bias. Second, generating synthetic anomalies in feature space is more effective, as defects may not have much commonality in the image space. Third, a simple discriminator is much efficient and practical. In spite of simplicity, SimpleNet outperforms previous methods quantitatively and qualitatively. On the MVTec AD benchmark, SimpleNet achieves an anomaly detection AUROC of 99.6%, reducing the error by 55.5% compared to the next best performing model. Furthermore, SimpleNet is faster than existing methods, with a high frame rate of 77 FPS on a 3080ti GPU. Additionally, SimpleNet demonstrates significant improvements in performance on the One-Class Novelty Detection task. Code: https://github.com/DonaldRR/SimpleNet.
Evaluating the Social Impact of Generative AI Systems in Systems and Society
Jun 12, 2023Generative AI systems across modalities, ranging from text, image, audio, and video, have broad social impacts, but there exists no official standard for means of evaluating those impacts and which impacts should be evaluated. We move toward a standard approach in evaluating a generative AI system for any modality, in two overarching categories: what is able to be evaluated in a base system that has no predetermined application and what is able to be evaluated in society. We describe specific social impact categories and how to approach and conduct evaluations in the base technical system, then in people and society. Our framework for a base system defines seven categories of social impact: bias, stereotypes, and representational harms; cultural values and sensitive content; disparate performance; privacy and data protection; financial costs; environmental costs; and data and content moderation labor costs. Suggested methods for evaluation apply to all modalities and analyses of the limitations of existing evaluations serve as a starting point for necessary investment in future evaluations. We offer five overarching categories for what is able to be evaluated in society, each with their own subcategories: trustworthiness and autonomy; inequality, marginalization, and violence; concentration of authority; labor and creativity; and ecosystem and environment. Each subcategory includes recommendations for mitigating harm. We are concurrently crafting an evaluation repository for the AI research community to contribute existing evaluations along the given categories. This version will be updated following a CRAFT session at ACM FAccT 2023.
Fast Diffusion Model
Jun 12, 2023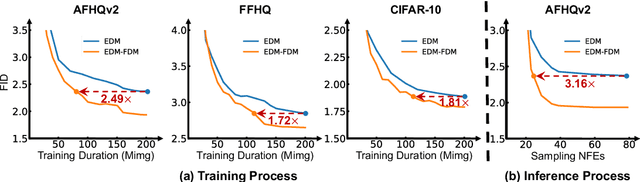

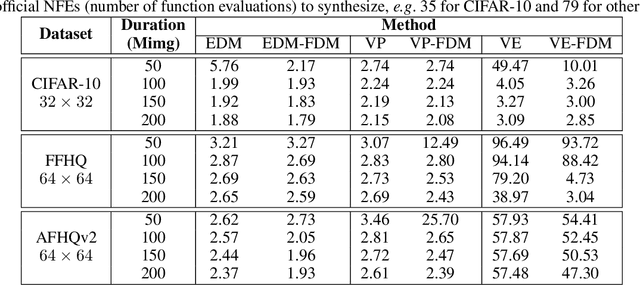

Despite their success in real data synthesis, diffusion models (DMs) often suffer from slow and costly training and sampling issues, limiting their broader applications. To mitigate this, we propose a Fast Diffusion Model (FDM) which improves the diffusion process of DMs from a stochastic optimization perspective to speed up both training and sampling. Specifically, we first find that the diffusion process of DMs accords with the stochastic optimization process of stochastic gradient descent (SGD) on a stochastic time-variant problem. Note that momentum SGD uses both the current gradient and an extra momentum, achieving more stable and faster convergence. We are inspired to introduce momentum into the diffusion process to accelerate both training and sampling. However, this comes with the challenge of deriving the noise perturbation kernel from the momentum-based diffusion process. To this end, we frame the momentum-based process as a Damped Oscillation system whose critically damped state -- the kernel solution -- avoids oscillation and thus has a faster convergence speed of the diffusion process. Empirical results show that our FDM can be applied to several popular DM frameworks, e.g. VP, VE, and EDM, and reduces their training cost by about 50% with comparable image synthesis performance on CIFAR-10, FFHQ, and AFHQv2 datasets. Moreover, FDM decreases their sampling steps by about $3\times$ to achieve similar performance under the same deterministic samplers. The code is available at https://github.com/sail-sg/FDM.
DocAligner: Annotating Real-world Photographic Document Images by Simply Taking Pictures
Jun 12, 2023
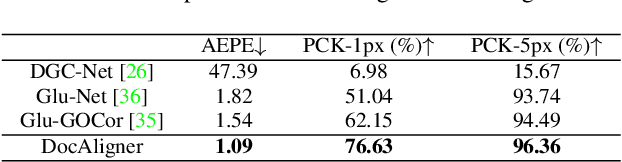
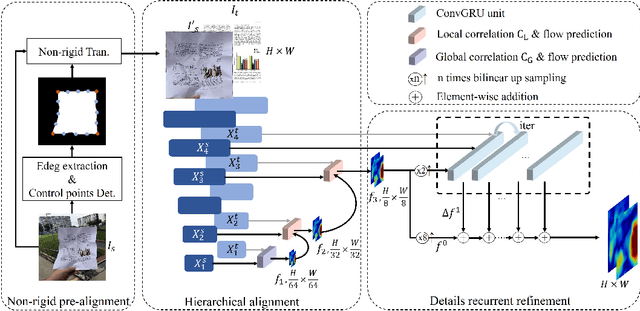
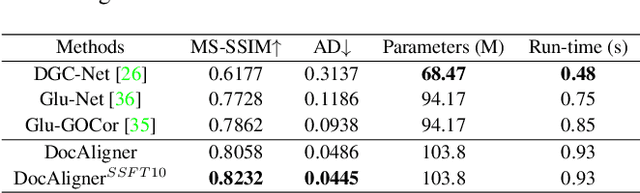
Recently, there has been a growing interest in research concerning document image analysis and recognition in photographic scenarios. However, the lack of labeled datasets for this emerging challenge poses a significant obstacle, as manual annotation can be time-consuming and impractical. To tackle this issue, we present DocAligner, a novel method that streamlines the manual annotation process to a simple step of taking pictures. DocAligner achieves this by establishing dense correspondence between photographic document images and their clean counterparts. It enables the automatic transfer of existing annotations in clean document images to photographic ones and helps to automatically acquire labels that are unavailable through manual labeling. Considering the distinctive characteristics of document images, DocAligner incorporates several innovative features. First, we propose a non-rigid pre-alignment technique based on the document's edges, which effectively eliminates interference caused by significant global shifts and repetitive patterns present in document images. Second, to handle large shifts and ensure high accuracy, we introduce a hierarchical aligning approach that combines global and local correlation layers. Furthermore, considering the importance of fine-grained elements in document images, we present a details recurrent refinement module to enhance the output in a high-resolution space. To train DocAligner, we construct a synthetic dataset and introduce a self-supervised learning approach to enhance its robustness for real-world data. Through extensive experiments, we demonstrate the effectiveness of DocAligner and the acquired dataset. Datasets and codes will be publicly available.
Efficient Backdoor Attacks for Deep Neural Networks in Real-world Scenarios
Jun 14, 2023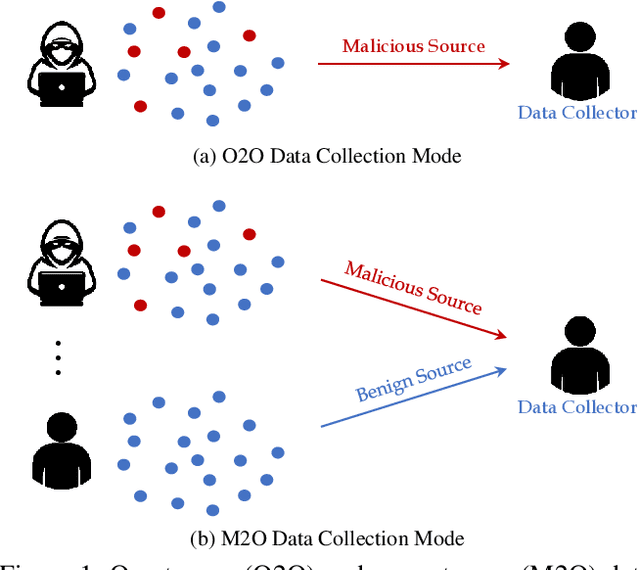
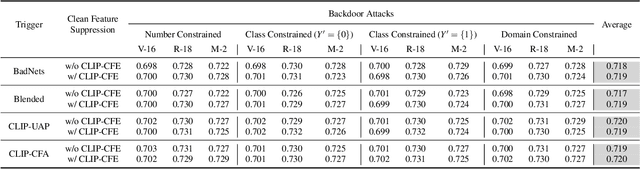

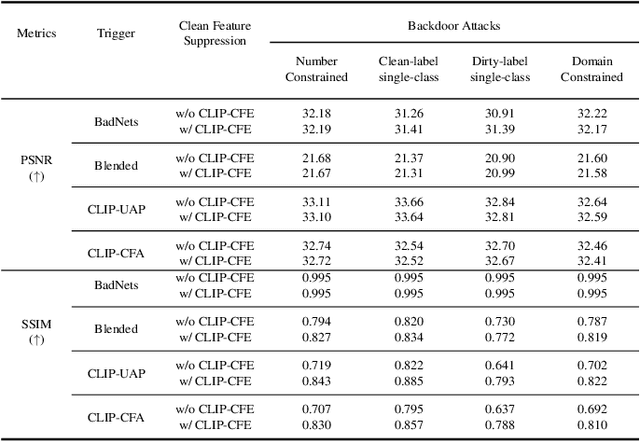
Recent deep neural networks (DNNs) have come to rely on vast amounts of training data, providing an opportunity for malicious attackers to exploit and contaminate the data to carry out backdoor attacks. These attacks significantly undermine the reliability of DNNs. However, existing backdoor attack methods make unrealistic assumptions, assuming that all training data comes from a single source and that attackers have full access to the training data. In this paper, we address this limitation by introducing a more realistic attack scenario where victims collect data from multiple sources, and attackers cannot access the complete training data. We refer to this scenario as data-constrained backdoor attacks. In such cases, previous attack methods suffer from severe efficiency degradation due to the entanglement between benign and poisoning features during the backdoor injection process. To tackle this problem, we propose a novel approach that leverages the pre-trained Contrastive Language-Image Pre-Training (CLIP) model. We introduce three CLIP-based technologies from two distinct streams: Clean Feature Suppression, which aims to suppress the influence of clean features to enhance the prominence of poisoning features, and Poisoning Feature Augmentation, which focuses on augmenting the presence and impact of poisoning features to effectively manipulate the model's behavior. To evaluate the effectiveness, harmlessness to benign accuracy, and stealthiness of our method, we conduct extensive experiments on 3 target models, 3 datasets, and over 15 different settings. The results demonstrate remarkable improvements, with some settings achieving over 100% improvement compared to existing attacks in data-constrained scenarios. Our research contributes to addressing the limitations of existing methods and provides a practical and effective solution for data-constrained backdoor attacks.
Rethinking Adversarial Training with A Simple Baseline
Jun 13, 2023
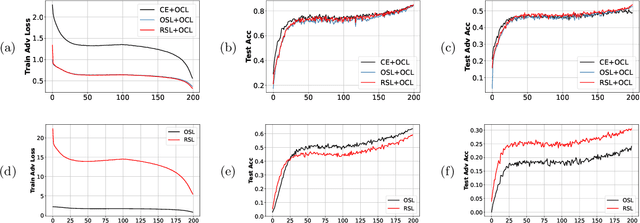
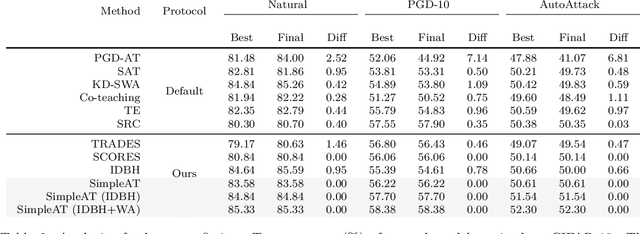
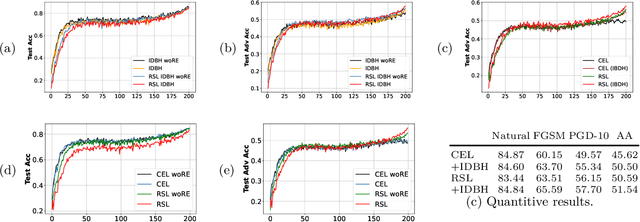
We report competitive results on RobustBench for CIFAR and SVHN using a simple yet effective baseline approach. Our approach involves a training protocol that integrates rescaled square loss, cyclic learning rates, and erasing-based data augmentation. The outcomes we have achieved are comparable to those of the model trained with state-of-the-art techniques, which is currently the predominant choice for adversarial training. Our baseline, referred to as SimpleAT, yields three novel empirical insights. (i) By switching to square loss, the accuracy is comparable to that obtained by using both de-facto training protocol plus data augmentation. (ii) One cyclic learning rate is a good scheduler, which can effectively reduce the risk of robust overfitting. (iii) Employing rescaled square loss during model training can yield a favorable balance between adversarial and natural accuracy. In general, our experimental results show that SimpleAT effectively mitigates robust overfitting and consistently achieves the best performance at the end of training. For example, on CIFAR-10 with ResNet-18, SimpleAT achieves approximately 52% adversarial accuracy against the current strong AutoAttack. Furthermore, SimpleAT exhibits robust performance on various image corruptions, including those commonly found in CIFAR-10-C dataset. Finally, we assess the effectiveness of these insights through two techniques: bias-variance analysis and logit penalty methods. Our findings demonstrate that all of these simple techniques are capable of reducing the variance of model predictions, which is regarded as the primary contributor to robust overfitting. In addition, our analysis also uncovers connections with various advanced state-of-the-art methods.
AVIS: Autonomous Visual Information Seeking with Large Language Models
Jun 13, 2023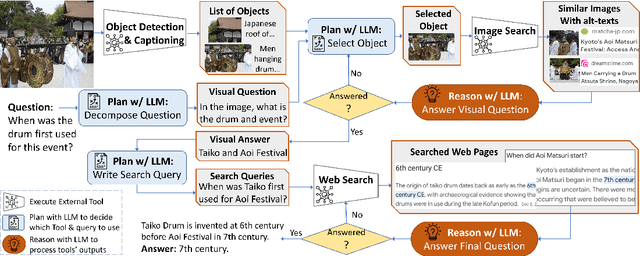
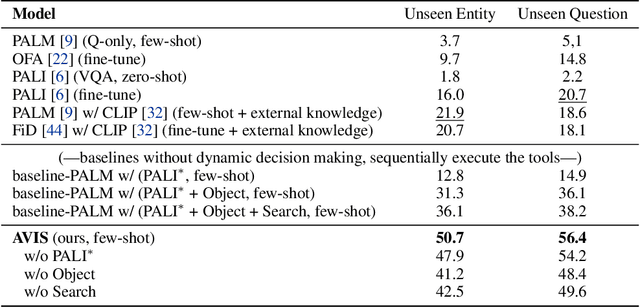
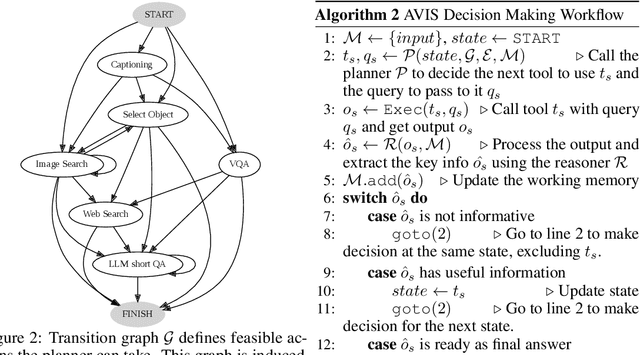

In this paper, we propose an autonomous information seeking visual question answering framework, AVIS. Our method leverages a Large Language Model (LLM) to dynamically strategize the utilization of external tools and to investigate their outputs, thereby acquiring the indispensable knowledge needed to provide answers to the posed questions. Responding to visual questions that necessitate external knowledge, such as "What event is commemorated by the building depicted in this image?", is a complex task. This task presents a combinatorial search space that demands a sequence of actions, including invoking APIs, analyzing their responses, and making informed decisions. We conduct a user study to collect a variety of instances of human decision-making when faced with this task. This data is then used to design a system comprised of three components: an LLM-powered planner that dynamically determines which tool to use next, an LLM-powered reasoner that analyzes and extracts key information from the tool outputs, and a working memory component that retains the acquired information throughout the process. The collected user behavior serves as a guide for our system in two key ways. First, we create a transition graph by analyzing the sequence of decisions made by users. This graph delineates distinct states and confines the set of actions available at each state. Second, we use examples of user decision-making to provide our LLM-powered planner and reasoner with relevant contextual instances, enhancing their capacity to make informed decisions. We show that AVIS achieves state-of-the-art results on knowledge-intensive visual question answering benchmarks such as Infoseek and OK-VQA.
Deep learning radiomics for assessment of gastroesophageal varices in people with compensated advanced chronic liver disease
Jun 13, 2023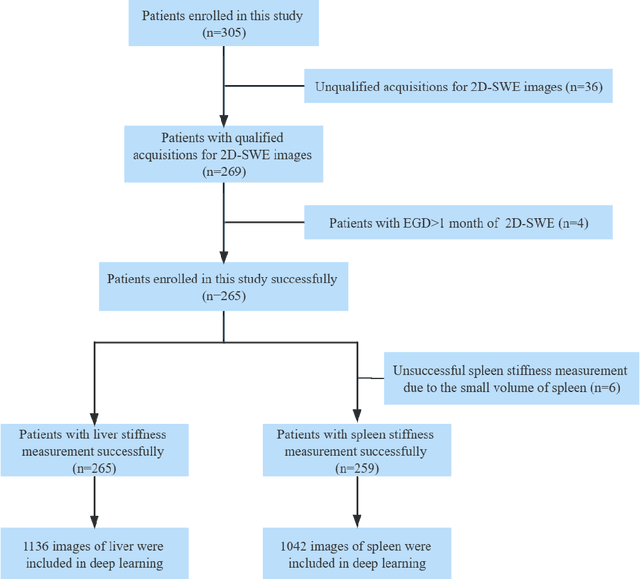
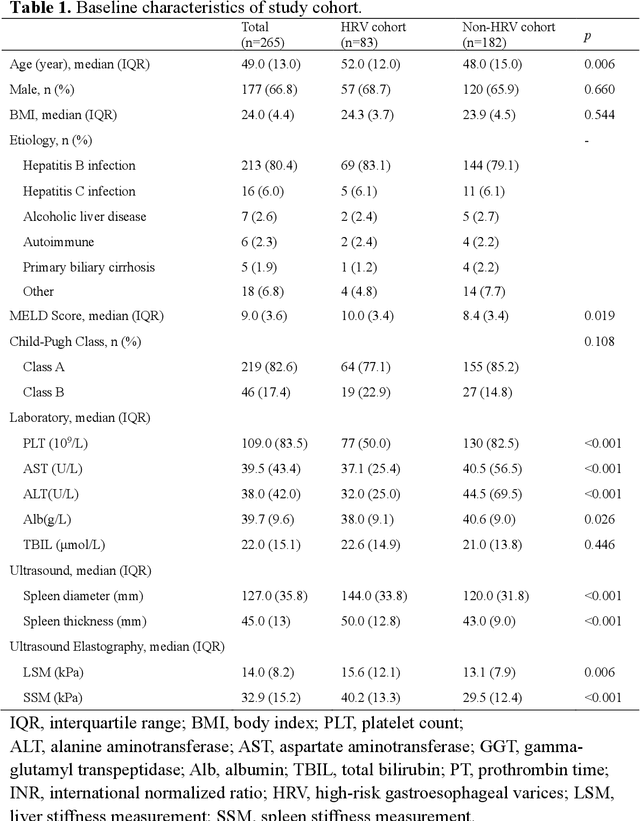
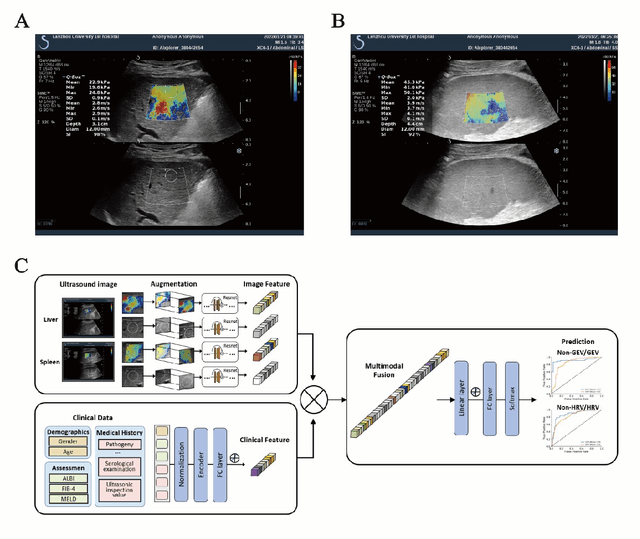
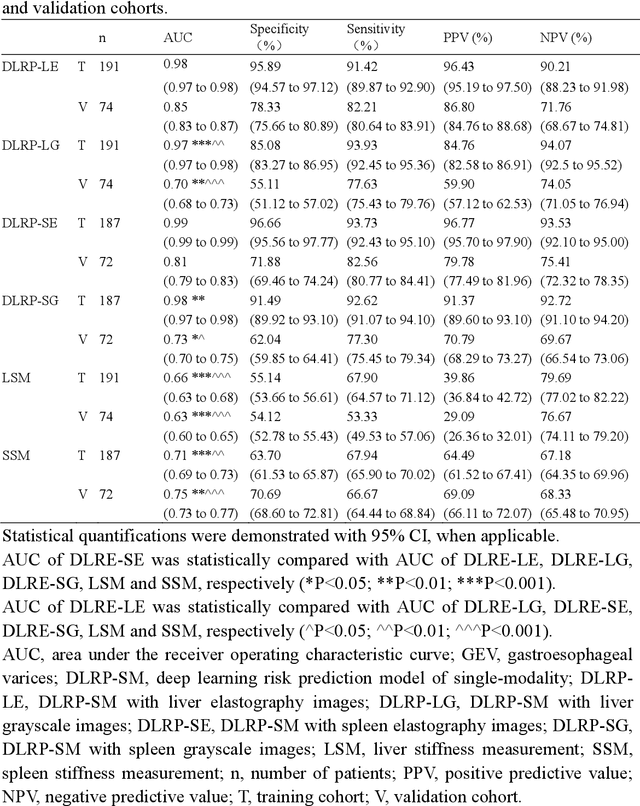
Objective: Bleeding from gastroesophageal varices (GEV) is a medical emergency associated with high mortality. We aim to construct an artificial intelligence-based model of two-dimensional shear wave elastography (2D-SWE) of the liver and spleen to precisely assess the risk of GEV and high-risk gastroesophageal varices (HRV). Design: A prospective multicenter study was conducted in patients with compensated advanced chronic liver disease. 305 patients were enrolled from 12 hospitals, and finally 265 patients were included, with 1136 liver stiffness measurement (LSM) images and 1042 spleen stiffness measurement (SSM) images generated by 2D-SWE. We leveraged deep learning methods to uncover associations between image features and patient risk, and thus conducted models to predict GEV and HRV. Results: A multi-modality Deep Learning Risk Prediction model (DLRP) was constructed to assess GEV and HRV, based on LSM and SSM images, and clinical information. Validation analysis revealed that the AUCs of DLRP were 0.91 for GEV (95% CI 0.90 to 0.93, p < 0.05) and 0.88 for HRV (95% CI 0.86 to 0.89, p < 0.01), which were significantly and robustly better than canonical risk indicators, including the value of LSM and SSM. Moreover, DLPR was better than the model using individual parameters, including LSM and SSM images. In HRV prediction, the 2D-SWE images of SSM outperform LSM (p < 0.01). Conclusion: DLRP shows excellent performance in predicting GEV and HRV over canonical risk indicators LSM and SSM. Additionally, the 2D-SWE images of SSM provided more information for better accuracy in predicting HRV than the LSM.
Automatic and Accurate Classification of Hotel Bathrooms from Images with Deep Learning
Jun 13, 2023
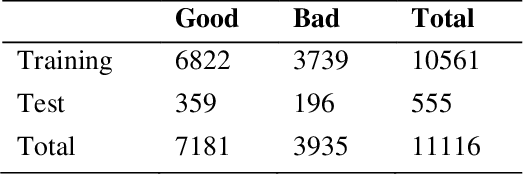
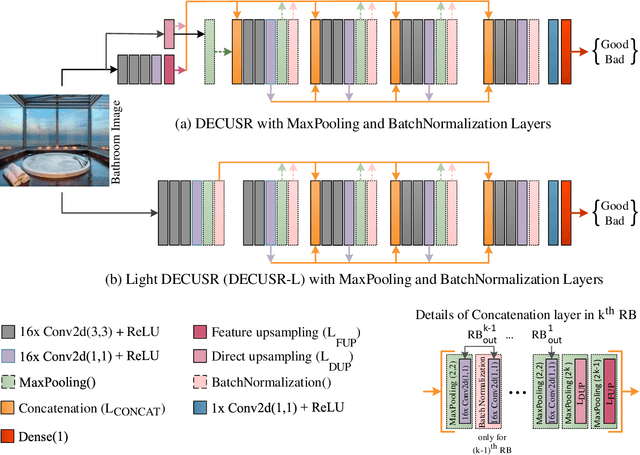
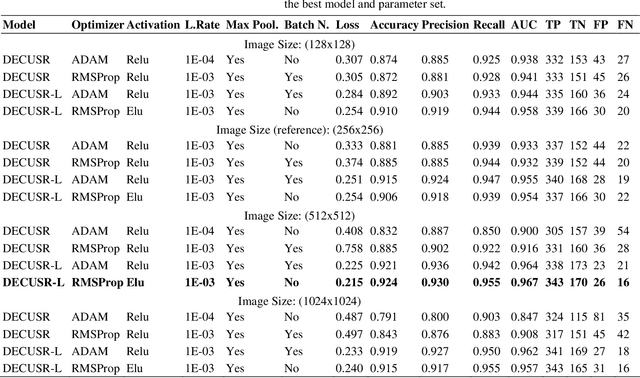
Hotel bathrooms are one of the most important places in terms of customer satisfaction, and where the most complaints are reported. To share their experiences, guests rate hotels, comment, and share images of their positive or negative ratings. An important part of the room images shared by guests is related to bathrooms. Guests tend to prove their satisfaction or dissatisfaction with the bathrooms with images in their comments. These Positive or negative comments and visuals potentially affect the prospective guests. In this study, two different versions of a deep learning algorithm were designed to classify hotel bathrooms as satisfactory (good) or unsatisfactory (bad, when any defects such as dirtiness, deficiencies, malfunctions were present) by analyzing images. The best-performer between the two models was determined as a result of a series of extensive experimental studies. The models were trained for each of 144 combinations of 5 hyper-parameter sets with a data set containing more than 11 thousand bathroom images, specially created for this study. The "HotelBath" data set was shared also with the community with this study. Four different image sizes were taken into consideration: 128, 256, 512 and 1024 pixels in both directions. The classification performances of the models were measured with several metrics. Both algorithms showed very attractive performances even with many combinations of hyper-parameters. They can classify bathroom images with very high accuracy. Suh that the top algorithm achieved an accuracy of 92.4% and an AUC (area under the curve) score of 0.967. In addition, other metrics also proved the success...