 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkillVetBench: LLM-as-Judge for Multi-Dimensional Security Risk Evaluation in Open-Source LLM Agent Skills
Jun 14, 2026Open-source LLM agent ecosystems are growing rapidly, yet the security of community-contributed skills - modular tool definitions that extend agent capabilities - remains largely unvetted. The gap we fill: existing scanners operate at the code layer and are structurally blind to instruction-layer and multi-agent risk - natural-language directives that hijack an agent, exfiltrate data through encoded side channels, or chain harm across pipelines - so what is needed is a semantic, multi-dimensional vetting system rather than another signature matcher. We present SKILLVETBENCH, a live public leaderboard on Hugging Face that uses an LLM-as-Judge to vet agent skills. What is new: SARS (Skill Agentic Risk Score), a five-dimensional agentic-risk metric with a principled weighted formula for instruction-following systems. What is integrated: full CVSS v4.0 vector decomposition and a ClawHub dual-view that places our LLM-generated review beside the official marketplace verdict. What is demonstrated: drawing on our companion benchmark paper [ 1], the LLM-as-Judge stage achieves zero false negatives across 78 confirmed-malicious skills and zero false positives across 22 benign controls, while the best static baseline (SKILLSIEVE) still misses 15%; for instruction-layer categories such as Prompt Injection and Memory Poisoning, conventional tools miss between 89% and 100% of threats (e.g., CODEBERT detects none of nine memory-poisoning skills). Detection rates vary from 35% to 95% across four LLM evaluators, motivating ensemble scoring in production deployments.
Benchmarking Security Risk Detection and Verification in Open Agentic Skill Ecosystems
May 30, 2026Open agent platforms allow community contributors to publish reusable skills that agents can invoke at runtime. This extensibility also creates a supply-chain risk: malicious contributors can hide harmful behavior inside skills that appear benign under superficial inspection. However, existing defenses are hard to evaluate because there is no benchmark that measures both malicious-skill detection and runtime verification. We present SkillVetBench, a two-stage security vetting benchmark for open agentic skill ecosystems. The first stage performs semantic vetting over each skill's natural-language specification to detect hidden malicious intent. The second stage executes flagged skills in an instrumented sandbox to observe runtime behavior and collect auditable evidence. We build a benchmark from confirmed malicious skills in the live OpenClaw ecosystem, including samples from the recent ClawHavoc supplychain campaign. Unlike static-only methods, SkillVetBench verifies detected threats with execution traces. Our experiments show that: (1) semantic-only and signature-based baselines are insufficient, missing up to 89\% of malicious skills whose threats arise from natural-language instructions, multicomponent logic, or cross-component interactions; (2) runtime attacks are concentrated in a small set of high-permission primitives, especially exec, write\_file, install\_skill, and spawn; and (3) SkillVetBench provides case studies in which sandbox execution directly supports malicious verdicts with concrete runtime evidence.
The Art of the Jailbreak: Formulating Jailbreak Attacks for LLM Security Beyond Binary Scoring
May 09, 2026Jailbreak attacks -- adversarial prompts that bypass LLM alignment through purely linguistic manipulation -- pose a growing operational security threat, yet the field lacks large-scale, reproducible infrastructure for generating, categorizing, and evaluating them systematically. This paper addresses that gap with three contributions. (1) Large-scale compositional jailbreak dataset. We construct 114,000 adversarial prompts by applying 912 composing strategies to 125 harmful seed prompts from JailBreakV-28K. Every prompt is assigned to one of 14 cybersecurity attack categories (e.g., malware, phishing, privilege escalation) via a six-model majority-vote pipeline, and each strategy is ranked by effectiveness per category, enabling principled strategy selection grounded in concrete adversarial objectives. (2) Automated jailbreak generation. We instruction-fine-tune category-aware LLMs on Moderate and Optimal subsets, producing models that synthesize fluent jailbreak prompts from a harmful seed at inference time -- no templates, no gradient search. Our generators achieve perplexity 24-39 versus 40-140 for AutoDAN and AmpleGCG, with safety-filter evasion rates of 0.29-0.51 Mal (LlamaPromptGuard-2-86M), enabling controllable, scalable red-teaming under realistic adversarial conditions. (3) OPTIMUS: a training-free jailbreak evaluator. OPTIMUS is a continuous metric J(S,H) that jointly captures semantic similarity between the harmful seed and the jailbreak (S) and harmfulness probability (H) via calibrated penalty functions. Unlike binary attack success rate (ASR), OPTIMUS requires no task-specific training, generalizes across evolving strategies, and exposes a stealth-optimal regime (S*=0.57, H*=0.43) that ASR misses. Experiments across 114,000 prompts confirm that OPTIMUS separates Weak, Moderate, and Optimal jailbreaks with category-level evidence binary evaluation cannot supply.
Semantic Intent Fragmentation: A Single-Shot Compositional Attack on Multi-Agent AI Pipelines
Apr 08, 2026We introduce Semantic Intent Fragmentation (SIF), an attack class against LLM orchestration systems where a single, legitimately phrased request causes an orchestrator to decompose a task into subtasks that are individually benign but jointly violate security policy. Current safety mechanisms operate at the subtask level, so each step clears existing classifiers -- the violation only emerges at the composed plan. SIF exploits OWASP LLM06:2025 through four mechanisms: bulk scope escalation, silent data exfiltration, embedded trigger deployment, and quasi-identifier aggregation, requiring no injected content, no system modification, and no attacker interaction after the initial request. We construct a three-stage red-teaming pipeline grounded in OWASP, MITRE ATLAS, and NIST frameworks to generate realistic enterprise scenarios. Across 14 scenarios spanning financial reporting, information security, and HR analytics, a GPT-20B orchestrator produces policy-violating plans in 71% of cases (10/14) while every subtask appears benign. Three independent signals validate this: deterministic taint analysis, chain-of-thought evaluation, and a cross-model compliance judge with 0% false positives. Stronger orchestrators increase SIF success rates. Plan-level information-flow tracking combined with compliance evaluation detects all attacks before execution, showing the compositional safety gap is closable.
Agent-Fence: Mapping Security Vulnerabilities Across Deep Research Agents
Feb 07, 2026Large language models are increasingly deployed as *deep agents* that plan, maintain persistent state, and invoke external tools, shifting safety failures from unsafe text to unsafe *trajectories*. We introduce **AgentFence**, an architecture-centric security evaluation that defines 14 trust-boundary attack classes spanning planning, memory, retrieval, tool use, and delegation, and detects failures via *trace-auditable conversation breaks* (unauthorized or unsafe tool use, wrong-principal actions, state/objective integrity violations, and attack-linked deviations). Holding the base model fixed, we evaluate eight agent archetypes under persistent multi-turn interaction and observe substantial architectural variation in mean security break rate (MSBR), ranging from $0.29 \pm 0.04$ (LangGraph) to $0.51 \pm 0.07$ (AutoGPT). The highest-risk classes are operational: Denial-of-Wallet ($0.62 \pm 0.08$), Authorization Confusion ($0.54 \pm 0.10$), Retrieval Poisoning ($0.47 \pm 0.09$), and Planning Manipulation ($0.44 \pm 0.11$), while prompt-centric classes remain below $0.20$ under standard settings. Breaks are dominated by boundary violations (SIV 31%, WPA 27%, UTI+UTA 24%, ATD 18%), and authorization confusion correlates with objective and tool hijacking ($ρ\approx 0.63$ and $ρ\approx 0.58$). AgentFence reframes agent security around what matters operationally: whether an agent stays within its goal and authority envelope over time.
Optimus-Q: Utilizing Federated Learning in Adaptive Robots for Intelligent Nuclear Power Plant Operations through Quantum Cryptography
Nov 19, 2025The integration of advanced robotics in nuclear power plants (NPPs) presents a transformative opportunity to enhance safety, efficiency, and environmental monitoring in high-stakes environments. Our paper introduces the Optimus-Q robot, a sophisticated system designed to autonomously monitor air quality and detect contamination while leveraging adaptive learning techniques and secure quantum communication. Equipped with advanced infrared sensors, the Optimus-Q robot continuously streams real-time environmental data to predict hazardous gas emissions, including carbon dioxide (CO$_2$), carbon monoxide (CO), and methane (CH$_4$). Utilizing a federated learning approach, the robot collaborates with other systems across various NPPs to improve its predictive capabilities without compromising data privacy. Additionally, the implementation of Quantum Key Distribution (QKD) ensures secure data transmission, safeguarding sensitive operational information. Our methodology combines systematic navigation patterns with machine learning algorithms to facilitate efficient coverage of designated areas, thereby optimizing contamination monitoring processes. Through simulations and real-world experiments, we demonstrate the effectiveness of the Optimus-Q robot in enhancing operational safety and responsiveness in nuclear facilities. This research underscores the potential of integrating robotics, machine learning, and quantum technologies to revolutionize monitoring systems in hazardous environments.
LLM-Guided Dynamic-UMAP for Personalized Federated Graph Learning
Nov 12, 2025

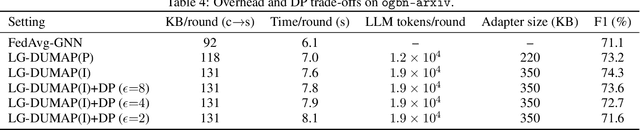
We propose a method that uses large language models to assist graph machine learning under personalization and privacy constraints. The approach combines data augmentation for sparse graphs, prompt and instruction tuning to adapt foundation models to graph tasks, and in-context learning to supply few-shot graph reasoning signals. These signals parameterize a Dynamic UMAP manifold of client-specific graph embeddings inside a Bayesian variational objective for personalized federated learning. The method supports node classification and link prediction in low-resource settings and aligns language model latent representations with graph structure via a cross-modal regularizer. We outline a convergence argument for the variational aggregation procedure, describe a differential privacy threat model based on a moments accountant, and present applications to knowledge graph completion, recommendation-style link prediction, and citation and product graphs. We also discuss evaluation considerations for benchmarking LLM-assisted graph machine learning.
Exploring Adversarial Watermarking in Transformer-Based Models: Transferability and Robustness Against Defense Mechanism for Medical Images
Jun 05, 2025Deep learning models have shown remarkable success in dermatological image analysis, offering potential for automated skin disease diagnosis. Previously, convolutional neural network(CNN) based architectures have achieved immense popularity and success in computer vision (CV) based task like skin image recognition, generation and video analysis. But with the emergence of transformer based models, CV tasks are now are nowadays carrying out using these models. Vision Transformers (ViTs) is such a transformer-based models that have shown success in computer vision. It uses self-attention mechanisms to achieve state-of-the-art performance across various tasks. However, their reliance on global attention mechanisms makes them susceptible to adversarial perturbations. This paper aims to investigate the susceptibility of ViTs for medical images to adversarial watermarking-a method that adds so-called imperceptible perturbations in order to fool models. By generating adversarial watermarks through Projected Gradient Descent (PGD), we examine the transferability of such attacks to CNNs and analyze the performance defense mechanism -- adversarial training. Results indicate that while performance is not compromised for clean images, ViTs certainly become much more vulnerable to adversarial attacks: an accuracy drop of as low as 27.6%. Nevertheless, adversarial training raises it up to 90.0%.
LAMDA: A Longitudinal Android Malware Benchmark for Concept Drift Analysis
May 24, 2025Machine learning (ML)-based malware detection systems often fail to account for the dynamic nature of real-world training and test data distributions. In practice, these distributions evolve due to frequent changes in the Android ecosystem, adversarial development of new malware families, and the continuous emergence of both benign and malicious applications. Prior studies have shown that such concept drift -- distributional shifts in benign and malicious samples, leads to significant degradation in detection performance over time. Despite the practical importance of this issue, existing datasets are often outdated and limited in temporal scope, diversity of malware families, and sample scale, making them insufficient for the systematic evaluation of concept drift in malware detection. To address this gap, we present LAMDA, the largest and most temporally diverse Android malware benchmark to date, designed specifically for concept drift analysis. LAMDA spans 12 years (2013-2025, excluding 2015), includes over 1 million samples (approximately 37% labeled as malware), and covers 1,380 malware families and 150,000 singleton samples, reflecting the natural distribution and evolution of real-world Android applications. We empirically demonstrate LAMDA's utility by quantifying the performance degradation of standard ML models over time and analyzing feature stability across years. As the most comprehensive Android malware dataset to date, LAMDA enables in-depth research into temporal drift, generalization, explainability, and evolving detection challenges. The dataset and code are available at: https://iqsec-lab.github.io/LAMDA/.
SocFedGPT: Federated GPT-based Adaptive Content Filtering System Leveraging User Interactions in Social Networks
Aug 07, 2024Our study presents a multifaceted approach to enhancing user interaction and content relevance in social media platforms through a federated learning framework. We introduce personalized GPT and Context-based Social Media LLM models, utilizing federated learning for privacy and security. Four client entities receive a base GPT-2 model and locally collected social media data, with federated aggregation ensuring up-to-date model maintenance. Subsequent modules focus on categorizing user posts, computing user persona scores, and identifying relevant posts from friends' lists. A quantifying social engagement approach, coupled with matrix factorization techniques, facilitates personalized content suggestions in real-time. An adaptive feedback loop and readability score algorithm also enhance the quality and relevance of content presented to users. Our system offers a comprehensive solution to content filtering and recommendation, fostering a tailored and engaging social media experience while safeguarding user privacy.