 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePano3D: Unified 3D Reconstruction and Panoptic Segmentation
Jun 12, 2026Recent advances in 3D feedforward reconstruction neural networks have achieved remarkable success in dense reconstruction from images without any camera parameters. Yet, equipping these models with robust semantic understanding remains an open problem. Here we introduce an approach that performs 3D reconstruction and 3D panoptic segmentation in a unified framework. We build on existing 3D reconstruction models and augment them with a set-based mask decoder. The approach is jointly trained with a geometric and semantic loss, which are shown to be mutually beneficial. More precisely, the features are initialized from the geometric information and then finetuned to capture jointly geometry and semantics. We demonstrate the generality of our approach by successfully applying our framework both to online and all-to-all attention reconstruction backbones. Our method achieves state-of-the-art performance in 3D panoptic segmentation across ScanNet, ScanNet200, and ScanNet++ datasets. Ablation studies show that such joint training of a unified model equips 3D feedforward reconstruction neural networks with panoptic segmentation and yields mutually beneficial improvements.
PointACT: Vision-Language-Action Models with Multi-Scale Point-Action Interaction
May 20, 2026Vision-Language-Action (VLA) models have shown strong potential for general-purpose robotic manipulation by leveraging large pretrained vision-language backbones. However, most existing VLAs rely primarily on 2D visual representations, which limit their ability to reason about fine-grained geometry and spatial grounding - capabilities that are essential for precise and robust manipulation in 3D environments. In this paper, we propose PointACT, a dual-system 3D-aware VLA policy that integrates hierarchical 3D point cloud representations directly into the action decoding process. PointACT employs a multi-scale point-action interaction mechanism with efficient bottleneck window self-attention, enabling evolving action tokens to densely attend to both local geometric detail and global scene structure. We evaluate PointACT on the LIBERO and RLBench benchmarks and systematically compare it against monolithic and dual-system VLA baselines, including variants augmented with point cloud inputs. PointACT achieves consistent improvements across both benchmarks, increasing success rates by 10% on the challenging RLBench-10Tasks suite over state-of-the-art pretrained VLAs, with even larger gains when the vision-language backbone is frozen and the action expert is trained from scratch. Extensive ablation studies demonstrate that tightly coupling hierarchical 3D geometry with pretrained 2D semantic representations is critical for robust and spatially grounded robot control. Our results also highlight the promise of pretrained 3D representations for 3D-aware VLA policies.
BrickNet: Graph-Backed Generative Brick Assembly
Apr 24, 2026We train a language model to generate LEGO-brick build sequences. While prior work has been restricted to discrete, voxel-like towers, we consider a much broader set of pieces, encompassing thousands of part types with diverse connection semantics. To enable this, we first collect a large-scale dataset of over 100,000 human-designed LDraw brick objects and scenes. The complexity of our setting makes it challenging to autoregressively assemble structures that satisfy physical constraints. When predicting block pose directly, build sequences quickly become invalid after a small number of steps. Although pieces are placed in 3D space, it is the spatial relationships of the parts which define the whole. With this in mind, we design a graph-based program representation that parametrizes structure through connectivity, improving the physical grounding of generated sequences. To enable future applications, we make our dataset and models available for research purposes. https://kulits.github.io/BrickNet
HO-Flow: Generalizable Hand-Object Interaction Generation with Latent Flow Matching
Apr 12, 2026Generating realistic 3D hand-object interactions (HOI) is a fundamental challenge in computer vision and robotics, requiring both temporal coherence and high-fidelity physical plausibility. Existing methods remain limited in their ability to learn expressive motion representations for generation and perform temporal reasoning. In this paper, we present HO-Flow, a framework for synthesizing realistic hand-object motion sequences from texts and canoncial 3D objects. HO-Flow first employs an interaction-aware variational autoencoder to encode sequences of hand and object motions into a unified latent manifold by incorporating hand and object kinematics, enabling the representation to capture rich interaction dynamics. It then leverages a masked flow matching model that combines auto-regressive temporal reasoning with continuous latent generation, improving temporal coherence. To further enhance generalization, HO-Flow predicts object motions relative to the initial frame, enabling effective pre-training on large-scale synthetic data. Experiments on the GRAB, OakInk, and DexYCB benchmarks demonstrate that HO-Flow achieves state-of-the-art performance in both physical plausibility and motion diversity for interaction motion synthesis.
CURVE: A Benchmark for Cultural and Multilingual Long Video Reasoning
Jan 15, 2026Recent advancements in video models have shown tremendous progress, particularly in long video understanding. However, current benchmarks predominantly feature western-centric data and English as the dominant language, introducing significant biases in evaluation. To address this, we introduce CURVE (Cultural Understanding and Reasoning in Video Evaluation), a challenging benchmark for multicultural and multilingual video reasoning. CURVE comprises high-quality, entirely human-generated annotations from diverse, region-specific cultural videos across 18 global locales. Unlike prior work that relies on automatic translations, CURVE provides complex questions, answers, and multi-step reasoning steps, all crafted in native languages. Making progress on CURVE requires a deeply situated understanding of visual cultural context. Furthermore, we leverage CURVE's reasoning traces to construct evidence-based graphs and propose a novel iterative strategy using these graphs to identify fine-grained errors in reasoning. Our evaluations reveal that SoTA Video-LLMs struggle significantly, performing substantially below human-level accuracy, with errors primarily stemming from the visual perception of cultural elements. CURVE will be publicly available under https://github.com/google-deepmind/neptune?tab=readme-ov-file\#minerva-cultural
MetricNet: Recovering Metric Scale in Generative Navigation Policies
Sep 17, 2025Generative navigation policies have made rapid progress in improving end-to-end learned navigation. Despite their promising results, this paradigm has two structural problems. First, the sampled trajectories exist in an abstract, unscaled space without metric grounding. Second, the control strategy discards the full path, instead moving directly towards a single waypoint. This leads to short-sighted and unsafe actions, moving the robot towards obstacles that a complete and correctly scaled path would circumvent. To address these issues, we propose MetricNet, an effective add-on for generative navigation that predicts the metric distance between waypoints, grounding policy outputs in real-world coordinates. We evaluate our method in simulation with a new benchmarking framework and show that executing MetricNet-scaled waypoints significantly improves both navigation and exploration performance. Beyond simulation, we further validate our approach in real-world experiments. Finally, we propose MetricNav, which integrates MetricNet into a navigation policy to guide the robot away from obstacles while still moving towards the goal.
CAViAR: Critic-Augmented Video Agentic Reasoning
Sep 09, 2025Video understanding has seen significant progress in recent years, with models' performance on perception from short clips continuing to rise. Yet, multiple recent benchmarks, such as LVBench, Neptune, and ActivityNet-RTL, show performance wanes for tasks requiring complex reasoning on videos as queries grow more complex and videos grow longer. In this work, we ask: can existing perception capabilities be leveraged to successfully perform more complex video reasoning? In particular, we develop a large language model agent given access to video modules as subagents or tools. Rather than following a fixed procedure to solve queries as in previous work such as Visual Programming, ViperGPT, and MoReVQA, the agent uses the results of each call to a module to determine subsequent steps. Inspired by work in the textual reasoning domain, we introduce a critic to distinguish between instances of successful and unsuccessful sequences from the agent. We show that the combination of our agent and critic achieve strong performance on the previously-mentioned datasets.
VoCap: Video Object Captioning and Segmentation from Any Prompt
Aug 29, 2025Understanding objects in videos in terms of fine-grained localization masks and detailed semantic properties is a fundamental task in video understanding. In this paper, we propose VoCap, a flexible video model that consumes a video and a prompt of various modalities (text, box or mask), and produces a spatio-temporal masklet with a corresponding object-centric caption. As such our model addresses simultaneously the tasks of promptable video object segmentation, referring expression segmentation, and object captioning. Since obtaining data for this task is tedious and expensive, we propose to annotate an existing large-scale segmentation dataset (SAV) with pseudo object captions. We do so by preprocessing videos with their ground-truth masks to highlight the object of interest and feed this to a large Vision Language Model (VLM). For an unbiased evaluation, we collect manual annotations on the validation set. We call the resulting dataset SAV-Caption. We train our VoCap model at scale on a SAV-Caption together with a mix of other image and video datasets. Our model yields state-of-the-art results on referring expression video object segmentation, is competitive on semi-supervised video object segmentation, and establishes a benchmark for video object captioning. Our dataset will be made available at https://github.com/google-deepmind/vocap.
Gondola: Grounded Vision Language Planning for Generalizable Robotic Manipulation
Jun 12, 2025



Robotic manipulation faces a significant challenge in generalizing across unseen objects, environments and tasks specified by diverse language instructions. To improve generalization capabilities, recent research has incorporated large language models (LLMs) for planning and action execution. While promising, these methods often fall short in generating grounded plans in visual environments. Although efforts have been made to perform visual instructional tuning on LLMs for robotic manipulation, existing methods are typically constrained by single-view image input and struggle with precise object grounding. In this work, we introduce Gondola, a novel grounded vision-language planning model based on LLMs for generalizable robotic manipulation. Gondola takes multi-view images and history plans to produce the next action plan with interleaved texts and segmentation masks of target objects and locations. To support the training of Gondola, we construct three types of datasets using the RLBench simulator, namely robot grounded planning, multi-view referring expression and pseudo long-horizon task datasets. Gondola outperforms the state-of-the-art LLM-based method across all four generalization levels of the GemBench dataset, including novel placements, rigid objects, articulated objects and long-horizon tasks.
ComposeAnything: Composite Object Priors for Text-to-Image Generation
May 30, 2025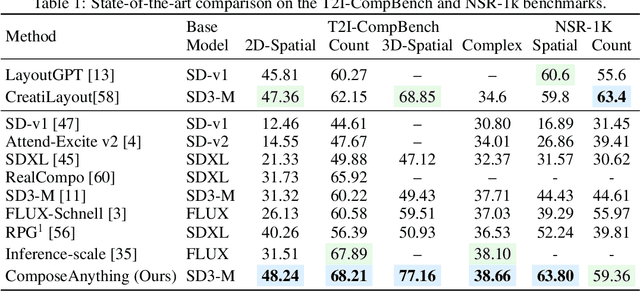
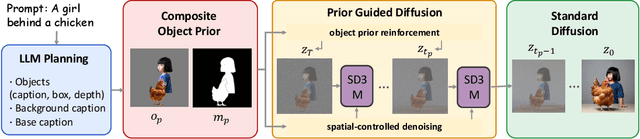
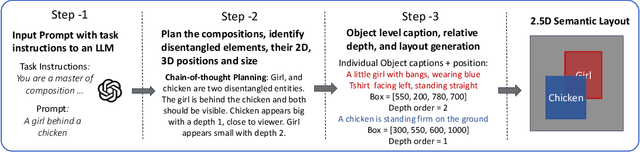
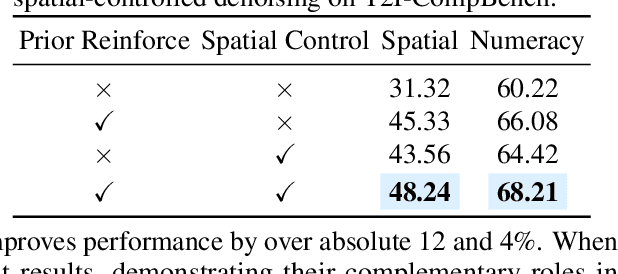
Generating images from text involving complex and novel object arrangements remains a significant challenge for current text-to-image (T2I) models. Although prior layout-based methods improve object arrangements using spatial constraints with 2D layouts, they often struggle to capture 3D positioning and sacrifice quality and coherence. In this work, we introduce ComposeAnything, a novel framework for improving compositional image generation without retraining existing T2I models. Our approach first leverages the chain-of-thought reasoning abilities of LLMs to produce 2.5D semantic layouts from text, consisting of 2D object bounding boxes enriched with depth information and detailed captions. Based on this layout, we generate a spatial and depth aware coarse composite of objects that captures the intended composition, serving as a strong and interpretable prior that replaces stochastic noise initialization in diffusion-based T2I models. This prior guides the denoising process through object prior reinforcement and spatial-controlled denoising, enabling seamless generation of compositional objects and coherent backgrounds, while allowing refinement of inaccurate priors. ComposeAnything outperforms state-of-the-art methods on the T2I-CompBench and NSR-1K benchmarks for prompts with 2D/3D spatial arrangements, high object counts, and surreal compositions. Human evaluations further demonstrate that our model generates high-quality images with compositions that faithfully reflect the text.