 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAViAR: Critic-Augmented Video Agentic Reasoning
Sep 09, 2025Video understanding has seen significant progress in recent years, with models' performance on perception from short clips continuing to rise. Yet, multiple recent benchmarks, such as LVBench, Neptune, and ActivityNet-RTL, show performance wanes for tasks requiring complex reasoning on videos as queries grow more complex and videos grow longer. In this work, we ask: can existing perception capabilities be leveraged to successfully perform more complex video reasoning? In particular, we develop a large language model agent given access to video modules as subagents or tools. Rather than following a fixed procedure to solve queries as in previous work such as Visual Programming, ViperGPT, and MoReVQA, the agent uses the results of each call to a module to determine subsequent steps. Inspired by work in the textual reasoning domain, we introduce a critic to distinguish between instances of successful and unsuccessful sequences from the agent. We show that the combination of our agent and critic achieve strong performance on the previously-mentioned datasets.
MINERVA: Evaluating Complex Video Reasoning
May 01, 2025Multimodal LLMs are turning their focus to video benchmarks, however most video benchmarks only provide outcome supervision, with no intermediate or interpretable reasoning steps. This makes it challenging to assess if models are truly able to combine perceptual and temporal information to reason about videos, or simply get the correct answer by chance or by exploiting linguistic biases. To remedy this, we provide a new video reasoning dataset called MINERVA for modern multimodal models. Each question in the dataset comes with 5 answer choices, as well as detailed, hand-crafted reasoning traces. Our dataset is multimodal, diverse in terms of video domain and length, and consists of complex multi-step questions. Extensive benchmarking shows that our dataset provides a challenge for frontier open-source and proprietary models. We perform fine-grained error analysis to identify common failure modes across various models, and create a taxonomy of reasoning errors. We use this to explore both human and LLM-as-a-judge methods for scoring video reasoning traces, and find that failure modes are primarily related to temporal localization, followed by visual perception errors, as opposed to logical or completeness errors. The dataset, along with questions, answer candidates and reasoning traces will be publicly available under https://github.com/google-deepmind/neptune?tab=readme-ov-file\#minerva.
Memory-Modular Classification: Learning to Generalize with Memory Replacement
Apr 08, 2025We propose a novel memory-modular learner for image classification that separates knowledge memorization from reasoning. Our model enables effective generalization to new classes by simply replacing the memory contents, without the need for model retraining. Unlike traditional models that encode both world knowledge and task-specific skills into their weights during training, our model stores knowledge in the external memory of web-crawled image and text data. At inference time, the model dynamically selects relevant content from the memory based on the input image, allowing it to adapt to arbitrary classes by simply replacing the memory contents. The key differentiator that our learner meta-learns to perform classification tasks with noisy web data from unseen classes, resulting in robust performance across various classification scenarios. Experimental results demonstrate the promising performance and versatility of our approach in handling diverse classification tasks, including zero-shot/few-shot classification of unseen classes, fine-grained classification, and class-incremental classification.
Web-Scale Visual Entity Recognition: An LLM-Driven Data Approach
Oct 31, 2024



Web-scale visual entity recognition, the task of associating images with their corresponding entities within vast knowledge bases like Wikipedia, presents significant challenges due to the lack of clean, large-scale training data. In this paper, we propose a novel methodology to curate such a dataset, leveraging a multimodal large language model (LLM) for label verification, metadata generation, and rationale explanation. Instead of relying on the multimodal LLM to directly annotate data, which we found to be suboptimal, we prompt it to reason about potential candidate entity labels by accessing additional contextually relevant information (such as Wikipedia), resulting in more accurate annotations. We further use the multimodal LLM to enrich the dataset by generating question-answer pairs and a grounded finegrained textual description (referred to as "rationale") that explains the connection between images and their assigned entities. Experiments demonstrate that models trained on this automatically curated data achieve state-of-the-art performance on web-scale visual entity recognition tasks (e.g. +6.9% improvement in OVEN entity task), underscoring the importance of high-quality training data in this domain.
AMES: Asymmetric and Memory-Efficient Similarity Estimation for Instance-level Retrieval
Aug 06, 2024This work investigates the problem of instance-level image retrieval re-ranking with the constraint of memory efficiency, ultimately aiming to limit memory usage to 1KB per image. Departing from the prevalent focus on performance enhancements, this work prioritizes the crucial trade-off between performance and memory requirements. The proposed model uses a transformer-based architecture designed to estimate image-to-image similarity by capturing interactions within and across images based on their local descriptors. A distinctive property of the model is the capability for asymmetric similarity estimation. Database images are represented with a smaller number of descriptors compared to query images, enabling performance improvements without increasing memory consumption. To ensure adaptability across different applications, a universal model is introduced that adjusts to a varying number of local descriptors during the testing phase. Results on standard benchmarks demonstrate the superiority of our approach over both hand-crafted and learned models. In particular, compared with current state-of-the-art methods that overlook their memory footprint, our approach not only attains superior performance but does so with a significantly reduced memory footprint. The code and pretrained models are publicly available at: https://github.com/pavelsuma/ames
A Generative Approach for Wikipedia-Scale Visual Entity Recognition
Mar 04, 2024In this paper, we address web-scale visual entity recognition, specifically the task of mapping a given query image to one of the 6 million existing entities in Wikipedia. One way of approaching a problem of such scale is using dual-encoder models (eg CLIP), where all the entity names and query images are embedded into a unified space, paving the way for an approximate k-NN search. Alternatively, it is also possible to re-purpose a captioning model to directly generate the entity names for a given image. In contrast, we introduce a novel Generative Entity Recognition (GER) framework, which given an input image learns to auto-regressively decode a semantic and discriminative ``code'' identifying the target entity. Our experiments demonstrate the efficacy of this GER paradigm, showcasing state-of-the-art performance on the challenging OVEN benchmark. GER surpasses strong captioning, dual-encoder, visual matching and hierarchical classification baselines, affirming its advantage in tackling the complexities of web-scale recognition.
SceneCraft: An LLM Agent for Synthesizing 3D Scene as Blender Code
Mar 02, 2024



This paper introduces SceneCraft, a Large Language Model (LLM) Agent converting text descriptions into Blender-executable Python scripts which render complex scenes with up to a hundred 3D assets. This process requires complex spatial planning and arrangement. We tackle these challenges through a combination of advanced abstraction, strategic planning, and library learning. SceneCraft first models a scene graph as a blueprint, detailing the spatial relationships among assets in the scene. SceneCraft then writes Python scripts based on this graph, translating relationships into numerical constraints for asset layout. Next, SceneCraft leverages the perceptual strengths of vision-language foundation models like GPT-V to analyze rendered images and iteratively refine the scene. On top of this process, SceneCraft features a library learning mechanism that compiles common script functions into a reusable library, facilitating continuous self-improvement without expensive LLM parameter tuning. Our evaluation demonstrates that SceneCraft surpasses existing LLM-based agents in rendering complex scenes, as shown by its adherence to constraints and favorable human assessments. We also showcase the broader application potential of SceneCraft by reconstructing detailed 3D scenes from the Sintel movie and guiding a video generative model with generated scenes as intermediary control signal.
AVIS: Autonomous Visual Information Seeking with Large Language Models
Jun 13, 2023In this paper, we propose an autonomous information seeking visual question answering framework, AVIS. Our method leverages a Large Language Model (LLM) to dynamically strategize the utilization of external tools and to investigate their outputs, thereby acquiring the indispensable knowledge needed to provide answers to the posed questions. Responding to visual questions that necessitate external knowledge, such as "What event is commemorated by the building depicted in this image?", is a complex task. This task presents a combinatorial search space that demands a sequence of actions, including invoking APIs, analyzing their responses, and making informed decisions. We conduct a user study to collect a variety of instances of human decision-making when faced with this task. This data is then used to design a system comprised of three components: an LLM-powered planner that dynamically determines which tool to use next, an LLM-powered reasoner that analyzes and extracts key information from the tool outputs, and a working memory component that retains the acquired information throughout the process. The collected user behavior serves as a guide for our system in two key ways. First, we create a transition graph by analyzing the sequence of decisions made by users. This graph delineates distinct states and confines the set of actions available at each state. Second, we use examples of user decision-making to provide our LLM-powered planner and reasoner with relevant contextual instances, enhancing their capacity to make informed decisions. We show that AVIS achieves state-of-the-art results on knowledge-intensive visual question answering benchmarks such as Infoseek and OK-VQA.
Retrieval-Enhanced Contrastive Vision-Text Models
Jun 12, 2023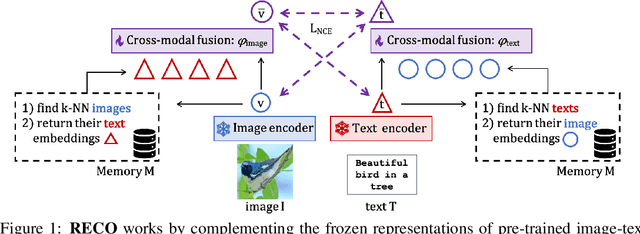
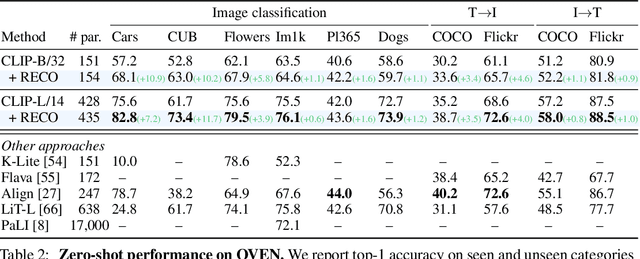
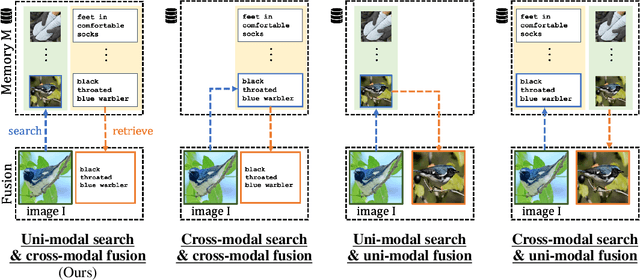
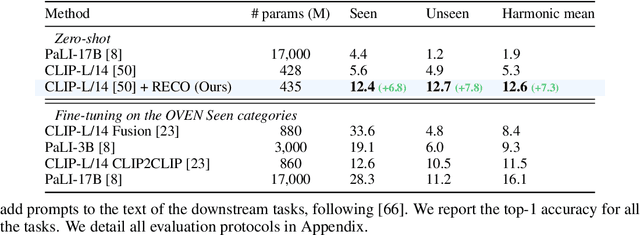
Contrastive image-text models such as CLIP form the building blocks of many state-of-the-art systems. While they excel at recognizing common generic concepts, they still struggle on fine-grained entities which are rare, or even absent from the pre-training dataset. Hence, a key ingredient to their success has been the use of large-scale curated pre-training data aiming at expanding the set of concepts that they can memorize during the pre-training stage. In this work, we explore an alternative to encoding fine-grained knowledge directly into the model's parameters: we instead train the model to retrieve this knowledge from an external memory. Specifically, we propose to equip existing vision-text models with the ability to refine their embedding with cross-modal retrieved information from a memory at inference time, which greatly improves their zero-shot predictions. Remarkably, we show that this can be done with a light-weight, single-layer, fusion transformer on top of a frozen CLIP. Our experiments validate that our retrieval-enhanced contrastive (RECO) training improves CLIP performance substantially on several challenging fine-grained tasks: for example +10.9 on Stanford Cars, +10.2 on CUB-2011 and +7.3 on the recent OVEN benchmark.
Improving Image Recognition by Retrieving from Web-Scale Image-Text Data
Apr 11, 2023Retrieval augmented models are becoming increasingly popular for computer vision tasks after their recent success in NLP problems. The goal is to enhance the recognition capabilities of the model by retrieving similar examples for the visual input from an external memory set. In this work, we introduce an attention-based memory module, which learns the importance of each retrieved example from the memory. Compared to existing approaches, our method removes the influence of the irrelevant retrieved examples, and retains those that are beneficial to the input query. We also thoroughly study various ways of constructing the memory dataset. Our experiments show the benefit of using a massive-scale memory dataset of 1B image-text pairs, and demonstrate the performance of different memory representations. We evaluate our method in three different classification tasks, namely long-tailed recognition, learning with noisy labels, and fine-grained classification, and show that it achieves state-of-the-art accuracies in ImageNet-LT, Places-LT and Webvision datasets.