 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAVIS: Autonomous Visual Information Seeking with Large Language Models
Jun 13, 2023In this paper, we propose an autonomous information seeking visual question answering framework, AVIS. Our method leverages a Large Language Model (LLM) to dynamically strategize the utilization of external tools and to investigate their outputs, thereby acquiring the indispensable knowledge needed to provide answers to the posed questions. Responding to visual questions that necessitate external knowledge, such as "What event is commemorated by the building depicted in this image?", is a complex task. This task presents a combinatorial search space that demands a sequence of actions, including invoking APIs, analyzing their responses, and making informed decisions. We conduct a user study to collect a variety of instances of human decision-making when faced with this task. This data is then used to design a system comprised of three components: an LLM-powered planner that dynamically determines which tool to use next, an LLM-powered reasoner that analyzes and extracts key information from the tool outputs, and a working memory component that retains the acquired information throughout the process. The collected user behavior serves as a guide for our system in two key ways. First, we create a transition graph by analyzing the sequence of decisions made by users. This graph delineates distinct states and confines the set of actions available at each state. Second, we use examples of user decision-making to provide our LLM-powered planner and reasoner with relevant contextual instances, enhancing their capacity to make informed decisions. We show that AVIS achieves state-of-the-art results on knowledge-intensive visual question answering benchmarks such as Infoseek and OK-VQA.
DaTaSeg: Taming a Universal Multi-Dataset Multi-Task Segmentation Model
Jun 02, 2023



Observing the close relationship among panoptic, semantic and instance segmentation tasks, we propose to train a universal multi-dataset multi-task segmentation model: DaTaSeg.We use a shared representation (mask proposals with class predictions) for all tasks. To tackle task discrepancy, we adopt different merge operations and post-processing for different tasks. We also leverage weak-supervision, allowing our segmentation model to benefit from cheaper bounding box annotations. To share knowledge across datasets, we use text embeddings from the same semantic embedding space as classifiers and share all network parameters among datasets. We train DaTaSeg on ADE semantic, COCO panoptic, and Objects365 detection datasets. DaTaSeg improves performance on all datasets, especially small-scale datasets, achieving 54.0 mIoU on ADE semantic and 53.5 PQ on COCO panoptic. DaTaSeg also enables weakly-supervised knowledge transfer on ADE panoptic and Objects365 instance segmentation. Experiments show DaTaSeg scales with the number of training datasets and enables open-vocabulary segmentation through direct transfer. In addition, we annotate an Objects365 instance segmentation set of 1,000 images and will release it as a public benchmark.
Distribution Aware Metrics for Conditional Natural Language Generation
Sep 29, 2022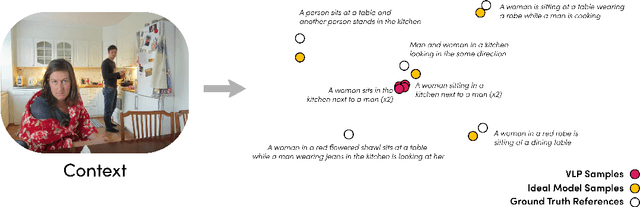
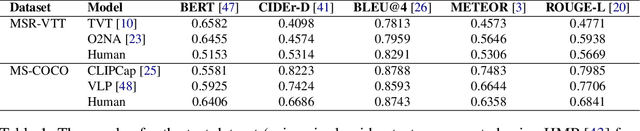

Traditional automated metrics for evaluating conditional natural language generation use pairwise comparisons between a single generated text and the best-matching gold-standard ground truth text. When multiple ground truths are available, scores are aggregated using an average or max operation across references. While this approach works well when diversity in the ground truth data (i.e. dispersion of the distribution of conditional texts) can be ascribed to noise, such as in automated speech recognition, it does not allow for robust evaluation in the case where diversity in the ground truths represents signal for the model. In this work we argue that existing metrics are not appropriate for domains such as visual description or summarization where ground truths are semantically diverse, and where the diversity in those captions captures useful additional information about the context. We propose a novel paradigm for multi-candidate evaluation of conditional language generation models, and a new family of metrics that compare the distributions of reference and model-generated caption sets using small sample sets of each. We demonstrate the utility of our approach with a case study in visual description: where we show that existing models optimize for single-description quality over diversity, and gain some insights into how sampling methods and temperature impact description quality and diversity.
An LSTM Approach to Temporal 3D Object Detection in LiDAR Point Clouds
Jul 24, 2020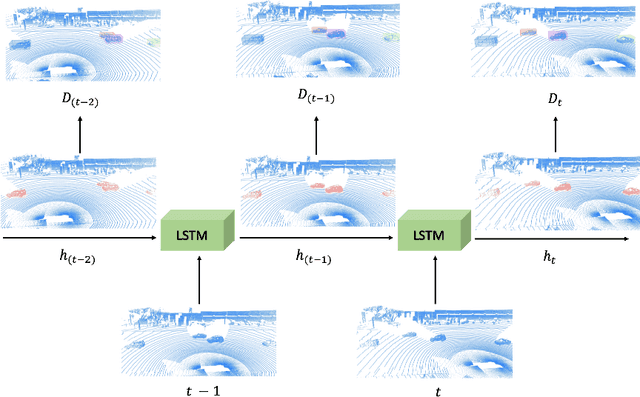
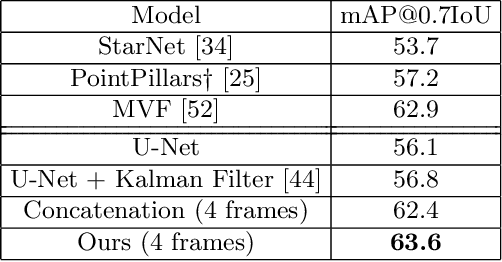
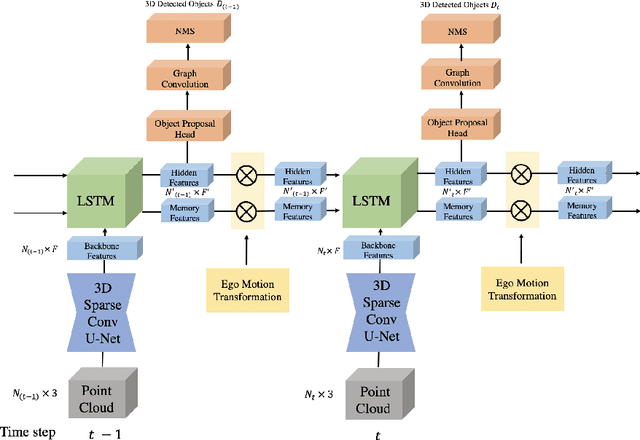
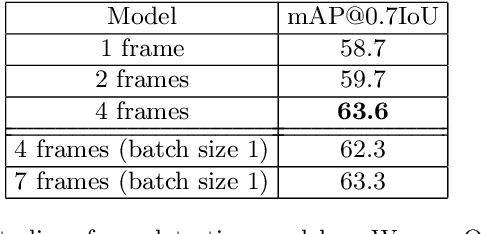
Detecting objects in 3D LiDAR data is a core technology for autonomous driving and other robotics applications. Although LiDAR data is acquired over time, most of the 3D object detection algorithms propose object bounding boxes independently for each frame and neglect the useful information available in the temporal domain. To address this problem, in this paper we propose a sparse LSTM-based multi-frame 3d object detection algorithm. We use a U-Net style 3D sparse convolution network to extract features for each frame's LiDAR point-cloud. These features are fed to the LSTM module together with the hidden and memory features from last frame to predict the 3d objects in the current frame as well as hidden and memory features that are passed to the next frame. Experiments on the Waymo Open Dataset show that our algorithm outperforms the traditional frame by frame approach by 7.5% mAP@0.7 and other multi-frame approaches by 1.2% while using less memory and computation per frame. To the best of our knowledge, this is the first work to use an LSTM for 3D object detection in sparse point clouds.