 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDepR: Depth Guided Single-view Scene Reconstruction with Instance-level Diffusion
Jul 30, 2025We propose DepR, a depth-guided single-view scene reconstruction framework that integrates instance-level diffusion within a compositional paradigm. Instead of reconstructing the entire scene holistically, DepR generates individual objects and subsequently composes them into a coherent 3D layout. Unlike previous methods that use depth solely for object layout estimation during inference and therefore fail to fully exploit its rich geometric information, DepR leverages depth throughout both training and inference. Specifically, we introduce depth-guided conditioning to effectively encode shape priors into diffusion models. During inference, depth further guides DDIM sampling and layout optimization, enhancing alignment between the reconstruction and the input image. Despite being trained on limited synthetic data, DepR achieves state-of-the-art performance and demonstrates strong generalization in single-view scene reconstruction, as shown through evaluations on both synthetic and real-world datasets.
ClutterDexGrasp: A Sim-to-Real System for General Dexterous Grasping in Cluttered Scenes
Jun 17, 2025
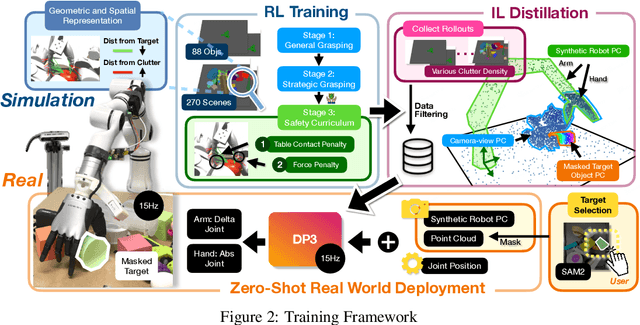


Dexterous grasping in cluttered scenes presents significant challenges due to diverse object geometries, occlusions, and potential collisions. Existing methods primarily focus on single-object grasping or grasp-pose prediction without interaction, which are insufficient for complex, cluttered scenes. Recent vision-language-action models offer a potential solution but require extensive real-world demonstrations, making them costly and difficult to scale. To address these limitations, we revisit the sim-to-real transfer pipeline and develop key techniques that enable zero-shot deployment in reality while maintaining robust generalization. We propose ClutterDexGrasp, a two-stage teacher-student framework for closed-loop target-oriented dexterous grasping in cluttered scenes. The framework features a teacher policy trained in simulation using clutter density curriculum learning, incorporating both a novel geometry and spatially-embedded scene representation and a comprehensive safety curriculum, enabling general, dynamic, and safe grasping behaviors. Through imitation learning, we distill the teacher's knowledge into a student 3D diffusion policy (DP3) that operates on partial point cloud observations. To the best of our knowledge, this represents the first zero-shot sim-to-real closed-loop system for target-oriented dexterous grasping in cluttered scenes, demonstrating robust performance across diverse objects and layouts. More details and videos are available at https://clutterdexgrasp.github.io/.
Adaptive Visuo-Tactile Fusion with Predictive Force Attention for Dexterous Manipulation
May 20, 2025Effectively utilizing multi-sensory data is important for robots to generalize across diverse tasks. However, the heterogeneous nature of these modalities makes fusion challenging. Existing methods propose strategies to obtain comprehensively fused features but often ignore the fact that each modality requires different levels of attention at different manipulation stages. To address this, we propose a force-guided attention fusion module that adaptively adjusts the weights of visual and tactile features without human labeling. We also introduce a self-supervised future force prediction auxiliary task to reinforce the tactile modality, improve data imbalance, and encourage proper adjustment. Our method achieves an average success rate of 93% across three fine-grained, contactrich tasks in real-world experiments. Further analysis shows that our policy appropriately adjusts attention to each modality at different manipulation stages. The videos can be viewed at https://adaptac-dex.github.io/.
X-Dancer: Expressive Music to Human Dance Video Generation
Feb 24, 2025We present X-Dancer, a novel zero-shot music-driven image animation pipeline that creates diverse and long-range lifelike human dance videos from a single static image. As its core, we introduce a unified transformer-diffusion framework, featuring an autoregressive transformer model that synthesize extended and music-synchronized token sequences for 2D body, head and hands poses, which then guide a diffusion model to produce coherent and realistic dance video frames. Unlike traditional methods that primarily generate human motion in 3D, X-Dancer addresses data limitations and enhances scalability by modeling a wide spectrum of 2D dance motions, capturing their nuanced alignment with musical beats through readily available monocular videos. To achieve this, we first build a spatially compositional token representation from 2D human pose labels associated with keypoint confidences, encoding both large articulated body movements (e.g., upper and lower body) and fine-grained motions (e.g., head and hands). We then design a music-to-motion transformer model that autoregressively generates music-aligned dance pose token sequences, incorporating global attention to both musical style and prior motion context. Finally we leverage a diffusion backbone to animate the reference image with these synthesized pose tokens through AdaIN, forming a fully differentiable end-to-end framework. Experimental results demonstrate that X-Dancer is able to produce both diverse and characterized dance videos, substantially outperforming state-of-the-art methods in term of diversity, expressiveness and realism. Code and model will be available for research purposes.
X-Dyna: Expressive Dynamic Human Image Animation
Jan 20, 2025We introduce X-Dyna, a novel zero-shot, diffusion-based pipeline for animating a single human image using facial expressions and body movements derived from a driving video, that generates realistic, context-aware dynamics for both the subject and the surrounding environment. Building on prior approaches centered on human pose control, X-Dyna addresses key shortcomings causing the loss of dynamic details, enhancing the lifelike qualities of human video animations. At the core of our approach is the Dynamics-Adapter, a lightweight module that effectively integrates reference appearance context into the spatial attentions of the diffusion backbone while preserving the capacity of motion modules in synthesizing fluid and intricate dynamic details. Beyond body pose control, we connect a local control module with our model to capture identity-disentangled facial expressions, facilitating accurate expression transfer for enhanced realism in animated scenes. Together, these components form a unified framework capable of learning physical human motion and natural scene dynamics from a diverse blend of human and scene videos. Comprehensive qualitative and quantitative evaluations demonstrate that X-Dyna outperforms state-of-the-art methods, creating highly lifelike and expressive animations. The code is available at https://github.com/bytedance/X-Dyna.
ProVision: Programmatically Scaling Vision-centric Instruction Data for Multimodal Language Models
Dec 09, 2024



With the rise of multimodal applications, instruction data has become critical for training multimodal language models capable of understanding complex image-based queries. Existing practices rely on powerful but costly large language models (LLMs) or multimodal language models (MLMs) to produce instruction data. These are often prone to hallucinations, licensing issues and the generation process is often hard to scale and interpret. In this work, we present a programmatic approach that employs scene graphs as symbolic representations of images and human-written programs to systematically synthesize vision-centric instruction data. Our approach ensures the interpretability and controllability of the data generation process and scales efficiently while maintaining factual accuracy. By implementing a suite of 24 single-image, 14 multi-image instruction generators, and a scene graph generation pipeline, we build a scalable, cost-effective system: ProVision which produces diverse question-answer pairs concerning objects, attributes, relations, depth, etc., for any given image. Applied to Visual Genome and DataComp datasets, we generate over 10 million instruction data points, ProVision-10M, and leverage them in both pretraining and instruction tuning stages of MLMs. When adopted in the instruction tuning stage, our single-image instruction data yields up to a 7% improvement on the 2D split and 8% on the 3D split of CVBench, along with a 3% increase in performance on QBench2, RealWorldQA, and MMMU. Our multi-image instruction data leads to an 8% improvement on Mantis-Eval. Incorporation of our data in both pre-training and fine-tuning stages of xGen-MM-4B leads to an averaged improvement of 1.6% across 11 benchmarks.
CPRM: A LLM-based Continual Pre-training Framework for Relevance Modeling in Commercial Search
Dec 03, 2024



Relevance modeling between queries and items stands as a pivotal component in commercial search engines, directly affecting the user experience. Given the remarkable achievements of large language models (LLMs) in various natural language processing (NLP) tasks, LLM-based relevance modeling is gradually being adopted within industrial search systems. Nevertheless, foundational LLMs lack domain-specific knowledge and do not fully exploit the potential of in-context learning. Furthermore, structured item text remains underutilized, and there is a shortage in the supply of corresponding queries and background knowledge. We thereby propose CPRM (Continual Pre-training for Relevance Modeling), a framework designed for the continual pre-training of LLMs to address these issues. Our CPRM framework includes three modules: 1) employing both queries and multi-field item to jointly pre-train for enhancing domain knowledge, 2) applying in-context pre-training, a novel approach where LLMs are pre-trained on a sequence of related queries or items, and 3) conducting reading comprehension on items to produce associated domain knowledge and background information (e.g., generating summaries and corresponding queries) to further strengthen LLMs. Results on offline experiments and online A/B testing demonstrate that our model achieves convincing performance compared to strong baselines.
xLAM: A Family of Large Action Models to Empower AI Agent Systems
Sep 05, 2024



Autonomous agents powered by large language models (LLMs) have attracted significant research interest. However, the open-source community faces many challenges in developing specialized models for agent tasks, driven by the scarcity of high-quality agent datasets and the absence of standard protocols in this area. We introduce and publicly release xLAM, a series of large action models designed for AI agent tasks. The xLAM series includes five models with both dense and mixture-of-expert architectures, ranging from 1B to 8x22B parameters, trained using a scalable, flexible pipeline that unifies, augments, and synthesizes diverse datasets to enhance AI agents' generalizability and performance across varied environments. Our experimental results demonstrate that xLAM consistently delivers exceptional performance across multiple agent ability benchmarks, notably securing the 1st position on the Berkeley Function-Calling Leaderboard, outperforming GPT-4, Claude-3, and many other models in terms of tool use. By releasing the xLAM series, we aim to advance the performance of open-source LLMs for autonomous AI agents, potentially accelerating progress and democratizing access to high-performance models for agent tasks. Models are available at https://huggingface.co/collections/Salesforce/xlam-models-65f00e2a0a63bbcd1c2dade4
xGen-VideoSyn-1: High-fidelity Text-to-Video Synthesis with Compressed Representations
Aug 22, 2024



We present xGen-VideoSyn-1, a text-to-video (T2V) generation model capable of producing realistic scenes from textual descriptions. Building on recent advancements, such as OpenAI's Sora, we explore the latent diffusion model (LDM) architecture and introduce a video variational autoencoder (VidVAE). VidVAE compresses video data both spatially and temporally, significantly reducing the length of visual tokens and the computational demands associated with generating long-sequence videos. To further address the computational costs, we propose a divide-and-merge strategy that maintains temporal consistency across video segments. Our Diffusion Transformer (DiT) model incorporates spatial and temporal self-attention layers, enabling robust generalization across different timeframes and aspect ratios. We have devised a data processing pipeline from the very beginning and collected over 13M high-quality video-text pairs. The pipeline includes multiple steps such as clipping, text detection, motion estimation, aesthetics scoring, and dense captioning based on our in-house video-LLM model. Training the VidVAE and DiT models required approximately 40 and 642 H100 days, respectively. Our model supports over 14-second 720p video generation in an end-to-end way and demonstrates competitive performance against state-of-the-art T2V models.
Towards Boosting LLMs-driven Relevance Modeling with Progressive Retrieved Behavior-augmented Prompting
Aug 18, 2024



Relevance modeling is a critical component for enhancing user experience in search engines, with the primary objective of identifying items that align with users' queries. Traditional models only rely on the semantic congruence between queries and items to ascertain relevance. However, this approach represents merely one aspect of the relevance judgement, and is insufficient in isolation. Even powerful Large Language Models (LLMs) still cannot accurately judge the relevance of a query and an item from a semantic perspective. To augment LLMs-driven relevance modeling, this study proposes leveraging user interactions recorded in search logs to yield insights into users' implicit search intentions. The challenge lies in the effective prompting of LLMs to capture dynamic search intentions, which poses several obstacles in real-world relevance scenarios, i.e., the absence of domain-specific knowledge, the inadequacy of an isolated prompt, and the prohibitive costs associated with deploying LLMs. In response, we propose ProRBP, a novel Progressive Retrieved Behavior-augmented Prompting framework for integrating search scenario-oriented knowledge with LLMs effectively. Specifically, we perform the user-driven behavior neighbors retrieval from the daily search logs to obtain domain-specific knowledge in time, retrieving candidates that users consider to meet their expectations. Then, we guide LLMs for relevance modeling by employing advanced prompting techniques that progressively improve the outputs of the LLMs, followed by a progressive aggregation with comprehensive consideration of diverse aspects. For online serving, we have developed an industrial application framework tailored for the deployment of LLMs in relevance modeling. Experiments on real-world industry data and online A/B testing demonstrate our proposal achieves promising performance.