 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBalancing Efficiency and Restoration: Lightweight Mamba-Based Model for CT Metal Artifact Reduction
Apr 08, 2026In computed tomography imaging, metal implants frequently generate severe artifacts that compromise image quality and hinder diagnostic accuracy. There are three main challenges in the existing methods: the deterioration of organ and tissue structures, dependence on sinogram data, and an imbalance between resource use and restoration efficiency. Addressing these issues, we introduce MARMamba, which effectively eliminates artifacts caused by metals of different sizes while maintaining the integrity of the original anatomical structures of the image. Furthermore, this model only focuses on CT images affected by metal artifacts, thus negating the requirement for additional input data. The model is a streamlined UNet architecture, which incorporates multi-scale Mamba (MS-Mamba) as its core module. Within MS-Mamba, a flip mamba block captures comprehensive contextual information by analyzing images from multiple orientations. Subsequently, the average maximum feed-forward network integrates critical features with average features to suppress the artifacts. This combination allows MARMamba to reduce artifacts efficiently. The experimental results demonstrate that our model excels in reducing metal artifacts, offering distinct advantages over other models. It also strikes an optimal balance between computational demands, memory usage, and the number of parameters, highlighting its practical utility in the real world. The code of the presented model is available at: https://github.com/RICKand-MORTY/MARMamba.
MTA-Agent: An Open Recipe for Multimodal Deep Search Agents
Apr 07, 2026Multimodal large language models (MLLMs) have demonstrated strong capabilities in visual understanding, yet they remain limited in complex, multi-step reasoning that requires deep searching and integrating visual evidence with external knowledge. In this work, we address this challenge by constructing high-quality, verified multi-hop vision-language training data for multimodal deep-search agents. We propose a Multi-hop Tool-Augmented Agent for Evidence-based QA Synthesis (MTA-Agent), which automatically selects tools and their parameters to retrieve and validate evidence from both visual and textual sources and generates structured multi-hop question-answer trajectories. Starting from diverse VQA seed datasets, our pipeline produces a large-scale training dataset, MTA-Vision-DeepSearch, containing 21K high-quality multi-hop examples. The data is filtered through a multi-stage verification process to ensure factual consistency and answer uniqueness. Using MTA-Vision-DeepSearch, a 32B open-source multimodal search agent achieves state-of-the-art performance, reaching an average of 54.63\% across six challenging benchmarks, outperforming GPT-5 (51.86\%), Gemini-2.5-Pro (50.98\%), and Gemini-3-Pro (54.46\%) under the same tool settings. We further show that training on our data improves both reasoning depth and tool-use behavior, increasing the average number of steps from 2.27 to 4.28, and leading to more systematic and persistent search strategies. Additionally, we demonstrate that training can be performed without real-time tool calls by replaying cached interactions, significantly reducing training cost. Importantly, we present MTA-Agent as a fully open recipe for multimodal deep search: we release the entire dataset, training trajectories, and implementation details to enable reproducibility and future research on open multimodal search agents.
How Far Are Vision-Language Models from Constructing the Real World? A Benchmark for Physical Generative Reasoning
Mar 25, 2026The physical world is not merely visual; it is governed by rigorous structural and procedural constraints. Yet, the evaluation of vision-language models (VLMs) remains heavily skewed toward perceptual realism, prioritizing the generation of visually plausible 3D layouts, shapes, and appearances. Current benchmarks rarely test whether models grasp the step-by-step processes and physical dependencies required to actually build these artifacts, a capability essential for automating design-to-construction pipelines. To address this, we introduce DreamHouse, a novel benchmark for physical generative reasoning: the capacity to synthesize artifacts that concurrently satisfy geometric, structural, constructability, and code-compliance constraints. We ground this benchmark in residential timber-frame construction, a domain with fully codified engineering standards and objectively verifiable correctness. We curate over 26,000 structures spanning 13 architectural styles, ach verified to construction-document standards (LOD 350) and develop a deterministic 10-test structural validation framework. Unlike static benchmarks that assess only final outputs, DreamHouse supports iterative agentic interaction. Models observe intermediate build states, generate construction actions, and receive structured environmental feedback, enabling a fine-grained evaluation of planning, structural reasoning, and self-correction. Extensive experiments with state-of-the-art VLMs reveal substantial capability gaps that are largely invisible on existing leaderboards. These findings establish physical validity as a critical evaluation axis orthogonal to visual realism, highlighting physical generative reasoning as a distinct and underdeveloped frontier in multimodal intelligence. Available at https://luluyuyuyang.github.io/dreamhouse
Enhancing Sa2VA for Referent Video Object Segmentation: 2nd Solution for 7th LSVOS RVOS Track
Sep 19, 2025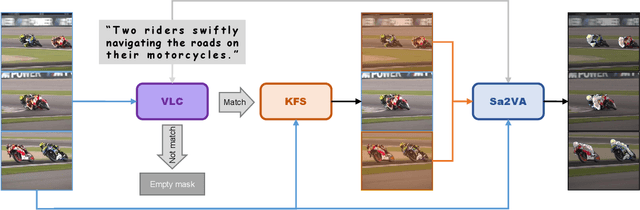



Referential Video Object Segmentation (RVOS) aims to segment all objects in a video that match a given natural language description, bridging the gap between vision and language understanding. Recent work, such as Sa2VA, combines Large Language Models (LLMs) with SAM~2, leveraging the strong video reasoning capability of LLMs to guide video segmentation. In this work, we present a training-free framework that substantially improves Sa2VA's performance on the RVOS task. Our method introduces two key components: (1) a Video-Language Checker that explicitly verifies whether the subject and action described in the query actually appear in the video, thereby reducing false positives; and (2) a Key-Frame Sampler that adaptively selects informative frames to better capture both early object appearances and long-range temporal context. Without any additional training, our approach achieves a J&F score of 64.14% on the MeViS test set, ranking 2nd place in the RVOS track of the 7th LSVOS Challenge at ICCV 2025.
Pseudo-Label Enhanced Cascaded Framework: 2nd Technical Report for LSVOS 2025 VOS Track
Sep 18, 2025



Complex Video Object Segmentation (VOS) presents significant challenges in accurately segmenting objects across frames, especially in the presence of small and similar targets, frequent occlusions, rapid motion, and complex interactions. In this report, we present our solution for the LSVOS 2025 VOS Track based on the SAM2 framework. We adopt a pseudo-labeling strategy during training: a trained SAM2 checkpoint is deployed within the SAM2Long framework to generate pseudo labels for the MOSE test set, which are then combined with existing data for further training. For inference, the SAM2Long framework is employed to obtain our primary segmentation results, while an open-source SeC model runs in parallel to produce complementary predictions. A cascaded decision mechanism dynamically integrates outputs from both models, exploiting the temporal stability of SAM2Long and the concept-level robustness of SeC. Benefiting from pseudo-label training and cascaded multi-model inference, our approach achieves a J\&F score of 0.8616 on the MOSE test set -- +1.4 points over our SAM2Long baseline -- securing the 2nd place in the LSVOS 2025 VOS Track, and demonstrating strong robustness and accuracy in long, complex video segmentation scenarios.
ProVision: Programmatically Scaling Vision-centric Instruction Data for Multimodal Language Models
Dec 09, 2024



With the rise of multimodal applications, instruction data has become critical for training multimodal language models capable of understanding complex image-based queries. Existing practices rely on powerful but costly large language models (LLMs) or multimodal language models (MLMs) to produce instruction data. These are often prone to hallucinations, licensing issues and the generation process is often hard to scale and interpret. In this work, we present a programmatic approach that employs scene graphs as symbolic representations of images and human-written programs to systematically synthesize vision-centric instruction data. Our approach ensures the interpretability and controllability of the data generation process and scales efficiently while maintaining factual accuracy. By implementing a suite of 24 single-image, 14 multi-image instruction generators, and a scene graph generation pipeline, we build a scalable, cost-effective system: ProVision which produces diverse question-answer pairs concerning objects, attributes, relations, depth, etc., for any given image. Applied to Visual Genome and DataComp datasets, we generate over 10 million instruction data points, ProVision-10M, and leverage them in both pretraining and instruction tuning stages of MLMs. When adopted in the instruction tuning stage, our single-image instruction data yields up to a 7% improvement on the 2D split and 8% on the 3D split of CVBench, along with a 3% increase in performance on QBench2, RealWorldQA, and MMMU. Our multi-image instruction data leads to an 8% improvement on Mantis-Eval. Incorporation of our data in both pre-training and fine-tuning stages of xGen-MM-4B leads to an averaged improvement of 1.6% across 11 benchmarks.
BLIP3-KALE: Knowledge Augmented Large-Scale Dense Captions
Nov 12, 2024



We introduce BLIP3-KALE, a dataset of 218 million image-text pairs that bridges the gap between descriptive synthetic captions and factual web-scale alt-text. KALE augments synthetic dense image captions with web-scale alt-text to generate factually grounded image captions. Our two-stage approach leverages large vision-language models and language models to create knowledge-augmented captions, which are then used to train a specialized VLM for scaling up the dataset. We train vision-language models on KALE and demonstrate improvements on vision-language tasks. Our experiments show the utility of KALE for training more capable and knowledgeable multimodal models. We release the KALE dataset at https://huggingface.co/datasets/Salesforce/blip3-kale
Trust but Verify: Programmatic VLM Evaluation in the Wild
Oct 17, 2024



Vision-Language Models (VLMs) often generate plausible but incorrect responses to visual queries. However, reliably quantifying the effect of such hallucinations in free-form responses to open-ended queries is challenging as it requires visually verifying each claim within the response. We propose Programmatic VLM Evaluation (PROVE), a new benchmarking paradigm for evaluating VLM responses to open-ended queries. To construct PROVE, we provide a large language model (LLM) with a high-fidelity scene-graph representation constructed from a hyper-detailed image caption, and prompt it to generate diverse question-answer (QA) pairs, as well as programs that can be executed over the scene graph object to verify each QA pair. We thus construct a benchmark of 10.5k challenging but visually grounded QA pairs. Next, to evaluate free-form model responses to queries in PROVE, we propose a programmatic evaluation strategy that measures both the helpfulness and truthfulness of a response within a unified scene graph-based framework. We benchmark the helpfulness-truthfulness trade-offs of a range of VLMs on PROVE, finding that very few are in-fact able to achieve a good balance between the two. Project page: \url{https://prove-explorer.netlify.app/}.
Edge-guided inverse design of digital metamaterials for ultra-high-capacity on-chip multi-dimensional interconnect
Oct 10, 2024



The escalating demands of compute-intensive applications, including artificial intelligence, urgently necessitate the adoption of sophisticated optical on-chip interconnect technologies to overcome critical bottlenecks in scaling future computing systems. This transition requires leveraging the inherent parallelism of wavelength and mode dimensions of light, complemented by high-order modulation formats, to significantly enhance data throughput. Here we experimentally demonstrate a novel synergy of these three dimensions, achieving multi-tens-of-terabits-per-second on-chip interconnects using ultra-broadband, multi-mode digital metamaterials. Employing a highly efficient edge-guided analog-and-digital optimization method, we inversely design foundry-compatible, robust, and multi-port digital metamaterials with an 8xhigher computational efficiency. Using a packaged five-mode multiplexing chip, we demonstrate a single-wavelength interconnect capacity of 1.62 Tbit s-1 and a record-setting multi-dimensional interconnect capacity of 38.2 Tbit s-1 across 5 modes and 88 wavelength channels. A theoretical analysis suggests that further system optimization can enable on-chip interconnects to reach sub-petabit-per-second data transmission rates. This study highlights the transformative potential of optical interconnect technologies to surmount the constraints of electronic links, thus setting the stage for next-generation datacenter and optical compute interconnects.
xGen-MM (BLIP-3): A Family of Open Large Multimodal Models
Aug 16, 2024



This report introduces xGen-MM (also known as BLIP-3), a framework for developing Large Multimodal Models (LMMs). The framework comprises meticulously curated datasets, a training recipe, model architectures, and a resulting suite of LMMs. xGen-MM, short for xGen-MultiModal, expands the Salesforce xGen initiative on foundation AI models. Our models undergo rigorous evaluation across a range of tasks, including both single and multi-image benchmarks. Our pre-trained base model exhibits strong in-context learning capabilities and the instruction-tuned model demonstrates competitive performance among open-source LMMs with similar model sizes. In addition, we introduce a safety-tuned model with DPO, aiming to mitigate harmful behaviors such as hallucinations and improve safety. We open-source our models, curated large-scale datasets, and our fine-tuning codebase to facilitate further advancements in LMM research. Associated resources will be available on our project page above.