 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAny-ttach: Quick End-effector Swapping Enables Manipulation Dexterity with Simplicity
May 28, 2026Robotic manipulation dexterity is often pursued by building increasingly complex high-DoF multifingered hands. While many robotic hands are designed to replicate human morphology, the functional role of human hands suggests a different perspective: much of their complexity may exist to enable tool use and tool making. This observation motivates Any-ttach, a tool-centric manipulation framework that treats quick end-effector swapping as a mechanism for dexterity with simplicity. Any-ttach combines a low-cost automatic swapping mechanism for an open-close robot interface, a handheld device for collecting human demonstrations, and a task planning framework that composes learned, parameterized, and planned tool-use skills. The system supports diverse tools and end-effector modules, including daily tools, articulated tools such as scissors, Fin Ray fingers, and a low-cost anthropomorphic hand, through the same shared interface. Our experiments show that Any-ttach improves tool-swapping reliability, increases demonstration efficiency, reduces tool-pose variability, and supports diverse tool-use skills. In two long-horizon tasks, making a sandwich and preparing a cucumber, Any-ttach executes six tool-use subskills through end-effector switching and execution monitoring. These results suggest that robots can expand manipulation capability not only through more complex end-effectors, but also through rapidly exchangeable tools and end-effector modules. More details and videos are available at https://any-ttach.github.io/.
CEER: Compliant End-Effector and Root Control as a Unified Interface for Hierarchical Humanoid Loco-Manipulation
May 19, 2026Humanoid robots have achieved impressive locomotion performance, yet contact-rich and long-horizon manipulation remains a major bottleneck. Manipulation is inherently contact-rich and demands compliant whole-body control for stable interaction, while its diversity and long-horizon nature favor modular, planner-compatible interfaces over joint-space tracking. We propose CEER, a compliant end-effector-root (EE-root) control abstraction for modular humanoid loco-manipulation within a hierarchical planning framework. CEER enables compliance-aware whole-body control in an interpretable task space defined by root motion commands and end-effector pose targets, and supports plug-and-play integration with heterogeneous high-level planners. A teacher-student framework is adopted to distill a general motion-tracking controller into a low-level policy that consumes only EE-root commands. We further construct a hierarchical system that integrates heterogeneous planners and task modules through the EE-root interface, enabling diverse manipulation tasks without retraining the underlying whole-body policy. Experiments in simulation and on hardware demonstrate 3.3 cm end-effector tracking accuracy with substantially reduced jerk compared to baselines, stable contact-rich manipulation under teleoperation, and up to 70% success in simulated single-object loco-manipulation tasks within a room-scale environment. These results indicate that compliant EE-root control provides a practical abstraction for humanoid loco-manipulation, enabling modular and scalable integration of diverse skills.
HiPolicy: Hierarchical Multi-Frequency Action Chunking for Policy Learning
Apr 07, 2026Robotic imitation learning faces a fundamental trade-off between modeling long-horizon dependencies and enabling fine-grained closed-loop control. Existing fixed-frequency action chunking approaches struggle to achieve both. Building on this insight, we propose HiPolicy, a hierarchical multi-frequency action chunking framework that jointly predicts action sequences at different frequencies to capture both coarse high-level plans and precise reactive motions. We extract and fuse hierarchical features from history observations aligned to each frequency for multi-frequency chunk generation, and introduce an entropy-guided execution mechanism that adaptively balances long-horizon planning with fine-grained control based on action uncertainty. Experiments on diverse simulated benchmarks and real-world manipulation tasks show that HiPolicy can be seamlessly integrated into existing 2D and 3D generative policies, delivering consistent improvements in performance while significantly enhancing execution efficiency.
TwinAligner: Visual-Dynamic Alignment Empowers Physics-aware Real2Sim2Real for Robotic Manipulation
Dec 22, 2025The robotics field is evolving towards data-driven, end-to-end learning, inspired by multimodal large models. However, reliance on expensive real-world data limits progress. Simulators offer cost-effective alternatives, but the gap between simulation and reality challenges effective policy transfer. This paper introduces TwinAligner, a novel Real2Sim2Real system that addresses both visual and dynamic gaps. The visual alignment module achieves pixel-level alignment through SDF reconstruction and editable 3DGS rendering, while the dynamic alignment module ensures dynamic consistency by identifying rigid physics from robot-object interaction. TwinAligner improves robot learning by providing scalable data collection and establishing a trustworthy iterative cycle, accelerating algorithm development. Quantitative evaluations highlight TwinAligner's strong capabilities in visual and dynamic real-to-sim alignment. This system enables policies trained in simulation to achieve strong zero-shot generalization to the real world. The high consistency between real-world and simulated policy performance underscores TwinAligner's potential to advance scalable robot learning. Code and data will be released on https://twin-aligner.github.io
OPENTOUCH: Bringing Full-Hand Touch to Real-World Interaction
Dec 18, 2025The human hand is our primary interface to the physical world, yet egocentric perception rarely knows when, where, or how forcefully it makes contact. Robust wearable tactile sensors are scarce, and no existing in-the-wild datasets align first-person video with full-hand touch. To bridge the gap between visual perception and physical interaction, we present OpenTouch, the first in-the-wild egocentric full-hand tactile dataset, containing 5.1 hours of synchronized video-touch-pose data and 2,900 curated clips with detailed text annotations. Using OpenTouch, we introduce retrieval and classification benchmarks that probe how touch grounds perception and action. We show that tactile signals provide a compact yet powerful cue for grasp understanding, strengthen cross-modal alignment, and can be reliably retrieved from in-the-wild video queries. By releasing this annotated vision-touch-pose dataset and benchmark, we aim to advance multimodal egocentric perception, embodied learning, and contact-rich robotic manipulation.
ClutterDexGrasp: A Sim-to-Real System for General Dexterous Grasping in Cluttered Scenes
Jun 17, 2025
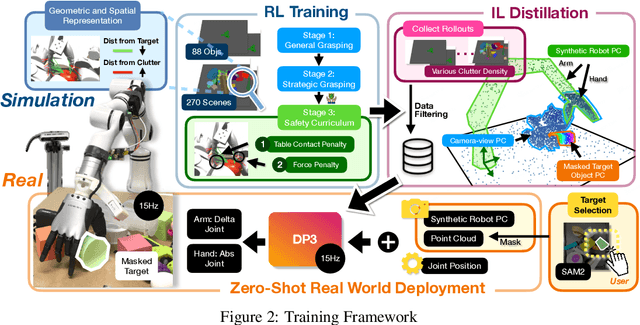


Dexterous grasping in cluttered scenes presents significant challenges due to diverse object geometries, occlusions, and potential collisions. Existing methods primarily focus on single-object grasping or grasp-pose prediction without interaction, which are insufficient for complex, cluttered scenes. Recent vision-language-action models offer a potential solution but require extensive real-world demonstrations, making them costly and difficult to scale. To address these limitations, we revisit the sim-to-real transfer pipeline and develop key techniques that enable zero-shot deployment in reality while maintaining robust generalization. We propose ClutterDexGrasp, a two-stage teacher-student framework for closed-loop target-oriented dexterous grasping in cluttered scenes. The framework features a teacher policy trained in simulation using clutter density curriculum learning, incorporating both a novel geometry and spatially-embedded scene representation and a comprehensive safety curriculum, enabling general, dynamic, and safe grasping behaviors. Through imitation learning, we distill the teacher's knowledge into a student 3D diffusion policy (DP3) that operates on partial point cloud observations. To the best of our knowledge, this represents the first zero-shot sim-to-real closed-loop system for target-oriented dexterous grasping in cluttered scenes, demonstrating robust performance across diverse objects and layouts. More details and videos are available at https://clutterdexgrasp.github.io/.
Adaptive Visuo-Tactile Fusion with Predictive Force Attention for Dexterous Manipulation
May 20, 2025Effectively utilizing multi-sensory data is important for robots to generalize across diverse tasks. However, the heterogeneous nature of these modalities makes fusion challenging. Existing methods propose strategies to obtain comprehensively fused features but often ignore the fact that each modality requires different levels of attention at different manipulation stages. To address this, we propose a force-guided attention fusion module that adaptively adjusts the weights of visual and tactile features without human labeling. We also introduce a self-supervised future force prediction auxiliary task to reinforce the tactile modality, improve data imbalance, and encourage proper adjustment. Our method achieves an average success rate of 93% across three fine-grained, contactrich tasks in real-world experiments. Further analysis shows that our policy appropriately adjusts attention to each modality at different manipulation stages. The videos can be viewed at https://adaptac-dex.github.io/.
Canonical Representation and Force-Based Pretraining of 3D Tactile for Dexterous Visuo-Tactile Policy Learning
Sep 26, 2024



Tactile sensing plays a vital role in enabling robots to perform fine-grained, contact-rich tasks. However, the high dimensionality of tactile data, due to the large coverage on dexterous hands, poses significant challenges for effective tactile feature learning, especially for 3D tactile data, as there are no large standardized datasets and no strong pretrained backbones. To address these challenges, we propose a novel canonical representation that reduces the difficulty of 3D tactile feature learning and further introduces a force-based self-supervised pretraining task to capture both local and net force features, which are crucial for dexterous manipulation. Our method achieves an average success rate of 78% across four fine-grained, contact-rich dexterous manipulation tasks in real-world experiments, demonstrating effectiveness and robustness compared to other methods. Further analysis shows that our method fully utilizes both spatial and force information from 3D tactile data to accomplish the tasks. The videos can be viewed at https://3dtacdex.github.io.
HGIC: A Hand Gesture Based Interactive Control System for Efficient and Scalable Multi-UAV Operations
Mar 08, 2024As technological advancements continue to expand the capabilities of multi unmanned-aerial-vehicle systems (mUAV), human operators face challenges in scalability and efficiency due to the complex cognitive load and operations associated with motion adjustments and team coordination. Such cognitive demands limit the feasible size of mUAV teams and necessitate extensive operator training, impeding broader adoption. This paper developed a Hand Gesture Based Interactive Control (HGIC), a novel interface system that utilize computer vision techniques to intuitively translate hand gestures into modular commands for robot teaming. Through learning control models, these commands enable efficient and scalable mUAV motion control and adjustments. HGIC eliminates the need for specialized hardware and offers two key benefits: 1) Minimal training requirements through natural gestures; and 2) Enhanced scalability and efficiency via adaptable commands. By reducing the cognitive burden on operators, HGIC opens the door for more effective large-scale mUAV applications in complex, dynamic, and uncertain scenarios. HGIC will be open-sourced after the paper being published online for the research community, aiming to drive forward innovations in human-mUAV interactions.