 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHEART-Bench: Do LLM Agents Exhibit Human-like Psychology?
May 28, 2026While LLM agents have demonstrated remarkable task-oriented abilities such as planning, reasoning, and action, few works have treated them as complete human personalities where emotional dimensions hold equal importance. In this paper, we introduce a novel benchmark to systematically assess whether LLM agents can simulate coherent, human-like psychology. Specifically, our benchmark constructs 11 diverse human characters grounded in orthogonal Big Five personality traits, with each profile deeply integrated with 1,000 structured autobiographical-style episodic memories distributed across theory-grounded developmental life stages. To rigorously evaluate the psychological manifestations of LLMs, we designed a curated suite of 64 decision-making scenarios, guided by the DIAMONDS taxonomy, a psychological framework that characterizes situations along eight dimensions: Duty, Intellect, Adversity, Mating, pOsitivity, Negativity, Deception, and Sociality. By subjecting agents to varying scenarios, the benchmark evaluates whether they can consolidate their innate personality traits and autobiographical memories to make behavioral decisions that are consistent with their specific psychological profiles. After systematic human validation and filtering, we obtained a benchmark consisting of 673 multiple-choice questions (MCQs). We believe this benchmark provides a principled and scalable testbed for studying human-like emotions, personality consistency, and value-consistent behavioural decision-making in LLM-based agents.
CodeOCR: On the Effectiveness of Vision Language Models in Code Understanding
Feb 02, 2026Large Language Models (LLMs) have achieved remarkable success in source code understanding, yet as software systems grow in scale, computational efficiency has become a critical bottleneck. Currently, these models rely on a text-based paradigm that treats source code as a linear sequence of tokens, which leads to a linear increase in context length and associated computational costs. The rapid advancement of Multimodal LLMs (MLLMs) introduces an opportunity to optimize efficiency by representing source code as rendered images. Unlike text, which is difficult to compress without losing semantic meaning, the image modality is inherently suitable for compression. By adjusting resolution, images can be scaled to a fraction of their original token cost while remaining recognizable to vision-capable models. To explore the feasibility of this approach, we conduct the first systematic study on the effectiveness of MLLMs for code understanding. Our experiments reveal that: (1) MLLMs can effectively understand code with substantial token reduction, achieving up to 8x compression; (2) MLLMs can effectively leverage visual cues such as syntax highlighting, improving code completion performance under 4x compression; and (3) Code-understanding tasks like clone detection exhibit exceptional resilience to visual compression, with some compression ratios even slightly outperforming raw text inputs. Our findings highlight both the potential and current limitations of MLLMs in code understanding, which points out a shift toward image-modality code representation as a pathway to more efficient inference.
Empathy-R1: A Chain-of-Empathy and Reinforcement Learning Framework for Long-Form Mental Health Support
Sep 18, 2025Empathy is critical for effective mental health support, especially when addressing Long Counseling Texts (LCTs). However, existing Large Language Models (LLMs) often generate replies that are semantically fluent but lack the structured reasoning necessary for genuine psychological support, particularly in a Chinese context. To bridge this gap, we introduce Empathy-R1, a novel framework that integrates a Chain-of-Empathy (CoE) reasoning process with Reinforcement Learning (RL) to enhance response quality for LCTs. Inspired by cognitive-behavioral therapy, our CoE paradigm guides the model to sequentially reason about a help-seeker's emotions, causes, and intentions, making its thinking process both transparent and interpretable. Our framework is empowered by a new large-scale Chinese dataset, Empathy-QA, and a two-stage training process. First, Supervised Fine-Tuning instills the CoE's reasoning structure. Subsequently, RL, guided by a dedicated reward model, refines the therapeutic relevance and contextual appropriateness of the final responses. Experiments show that Empathy-R1 achieves strong performance on key automatic metrics. More importantly, human evaluations confirm its superiority, showing a clear preference over strong baselines and achieving a Win@1 rate of 44.30% on our new benchmark. By enabling interpretable and contextually nuanced responses, Empathy-R1 represents a significant advancement in developing responsible and genuinely beneficial AI for mental health support.
CADDreamer: CAD object Generation from Single-view Images
Feb 28, 2025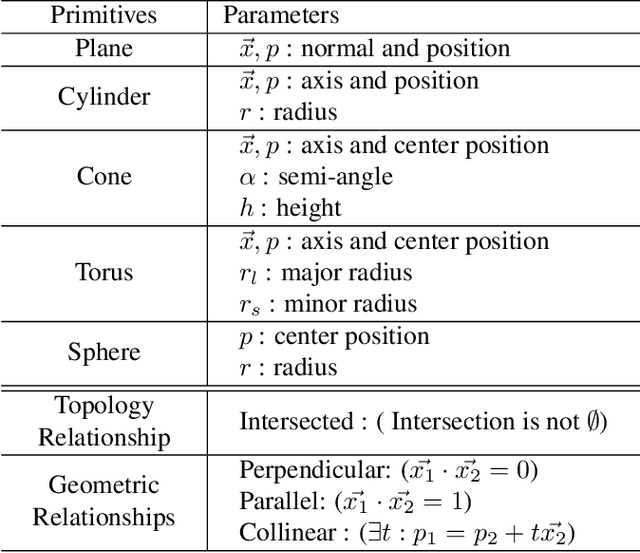
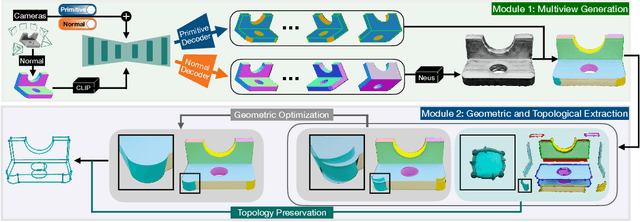

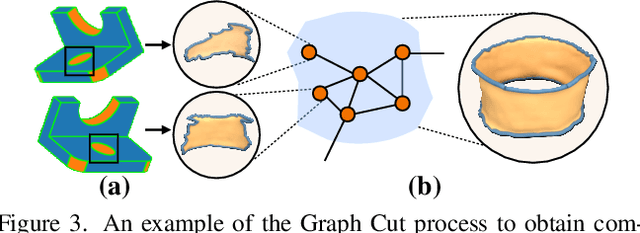
Diffusion-based 3D generation has made remarkable progress in recent years. However, existing 3D generative models often produce overly dense and unstructured meshes, which stand in stark contrast to the compact, structured, and sharply-edged Computer-Aided Design (CAD) models crafted by human designers. To address this gap, we introduce CADDreamer, a novel approach for generating boundary representations (B-rep) of CAD objects from a single image. CADDreamer employs a primitive-aware multi-view diffusion model that captures both local geometric details and high-level structural semantics during the generation process. By encoding primitive semantics into the color domain, the method leverages the strong priors of pre-trained diffusion models to align with well-defined primitives. This enables the inference of multi-view normal maps and semantic maps from a single image, facilitating the reconstruction of a mesh with primitive labels. Furthermore, we introduce geometric optimization techniques and topology-preserving extraction methods to mitigate noise and distortion in the generated primitives. These enhancements result in a complete and seamless B-rep of the CAD model. Experimental results demonstrate that our method effectively recovers high-quality CAD objects from single-view images. Compared to existing 3D generation techniques, the B-rep models produced by CADDreamer are compact in representation, clear in structure, sharp in edges, and watertight in topology.
X-Dancer: Expressive Music to Human Dance Video Generation
Feb 24, 2025We present X-Dancer, a novel zero-shot music-driven image animation pipeline that creates diverse and long-range lifelike human dance videos from a single static image. As its core, we introduce a unified transformer-diffusion framework, featuring an autoregressive transformer model that synthesize extended and music-synchronized token sequences for 2D body, head and hands poses, which then guide a diffusion model to produce coherent and realistic dance video frames. Unlike traditional methods that primarily generate human motion in 3D, X-Dancer addresses data limitations and enhances scalability by modeling a wide spectrum of 2D dance motions, capturing their nuanced alignment with musical beats through readily available monocular videos. To achieve this, we first build a spatially compositional token representation from 2D human pose labels associated with keypoint confidences, encoding both large articulated body movements (e.g., upper and lower body) and fine-grained motions (e.g., head and hands). We then design a music-to-motion transformer model that autoregressively generates music-aligned dance pose token sequences, incorporating global attention to both musical style and prior motion context. Finally we leverage a diffusion backbone to animate the reference image with these synthesized pose tokens through AdaIN, forming a fully differentiable end-to-end framework. Experimental results demonstrate that X-Dancer is able to produce both diverse and characterized dance videos, substantially outperforming state-of-the-art methods in term of diversity, expressiveness and realism. Code and model will be available for research purposes.
WonderHuman: Hallucinating Unseen Parts in Dynamic 3D Human Reconstruction
Feb 03, 2025In this paper, we present WonderHuman to reconstruct dynamic human avatars from a monocular video for high-fidelity novel view synthesis. Previous dynamic human avatar reconstruction methods typically require the input video to have full coverage of the observed human body. However, in daily practice, one typically has access to limited viewpoints, such as monocular front-view videos, making it a cumbersome task for previous methods to reconstruct the unseen parts of the human avatar. To tackle the issue, we present WonderHuman, which leverages 2D generative diffusion model priors to achieve high-quality, photorealistic reconstructions of dynamic human avatars from monocular videos, including accurate rendering of unseen body parts. Our approach introduces a Dual-Space Optimization technique, applying Score Distillation Sampling (SDS) in both canonical and observation spaces to ensure visual consistency and enhance realism in dynamic human reconstruction. Additionally, we present a View Selection strategy and Pose Feature Injection to enforce the consistency between SDS predictions and observed data, ensuring pose-dependent effects and higher fidelity in the reconstructed avatar. In the experiments, our method achieves SOTA performance in producing photorealistic renderings from the given monocular video, particularly for those challenging unseen parts. The project page and source code can be found at https://wyiguanw.github.io/WonderHuman/.
X-Dyna: Expressive Dynamic Human Image Animation
Jan 20, 2025We introduce X-Dyna, a novel zero-shot, diffusion-based pipeline for animating a single human image using facial expressions and body movements derived from a driving video, that generates realistic, context-aware dynamics for both the subject and the surrounding environment. Building on prior approaches centered on human pose control, X-Dyna addresses key shortcomings causing the loss of dynamic details, enhancing the lifelike qualities of human video animations. At the core of our approach is the Dynamics-Adapter, a lightweight module that effectively integrates reference appearance context into the spatial attentions of the diffusion backbone while preserving the capacity of motion modules in synthesizing fluid and intricate dynamic details. Beyond body pose control, we connect a local control module with our model to capture identity-disentangled facial expressions, facilitating accurate expression transfer for enhanced realism in animated scenes. Together, these components form a unified framework capable of learning physical human motion and natural scene dynamics from a diverse blend of human and scene videos. Comprehensive qualitative and quantitative evaluations demonstrate that X-Dyna outperforms state-of-the-art methods, creating highly lifelike and expressive animations. The code is available at https://github.com/bytedance/X-Dyna.
Joint Co-Speech Gesture and Expressive Talking Face Generation using Diffusion with Adapters
Dec 18, 2024



Recent advances in co-speech gesture and talking head generation have been impressive, yet most methods focus on only one of the two tasks. Those that attempt to generate both often rely on separate models or network modules, increasing training complexity and ignoring the inherent relationship between face and body movements. To address the challenges, in this paper, we propose a novel model architecture that jointly generates face and body motions within a single network. This approach leverages shared weights between modalities, facilitated by adapters that enable adaptation to a common latent space. Our experiments demonstrate that the proposed framework not only maintains state-of-the-art co-speech gesture and talking head generation performance but also significantly reduces the number of parameters required.
DiffTED: One-shot Audio-driven TED Talk Video Generation with Diffusion-based Co-speech Gestures
Sep 11, 2024



Audio-driven talking video generation has advanced significantly, but existing methods often depend on video-to-video translation techniques and traditional generative networks like GANs and they typically generate taking heads and co-speech gestures separately, leading to less coherent outputs. Furthermore, the gestures produced by these methods often appear overly smooth or subdued, lacking in diversity, and many gesture-centric approaches do not integrate talking head generation. To address these limitations, we introduce DiffTED, a new approach for one-shot audio-driven TED-style talking video generation from a single image. Specifically, we leverage a diffusion model to generate sequences of keypoints for a Thin-Plate Spline motion model, precisely controlling the avatar's animation while ensuring temporally coherent and diverse gestures. This innovative approach utilizes classifier-free guidance, empowering the gestures to flow naturally with the audio input without relying on pre-trained classifiers. Experiments demonstrate that DiffTED generates temporally coherent talking videos with diverse co-speech gestures.
Urban Waterlogging Detection: A Challenging Benchmark and Large-Small Model Co-Adapter
Jul 11, 2024



Urban waterlogging poses a major risk to public safety and infrastructure. Conventional methods using water-level sensors need high-maintenance to hardly achieve full coverage. Recent advances employ surveillance camera imagery and deep learning for detection, yet these struggle amidst scarce data and adverse environmental conditions. In this paper, we establish a challenging Urban Waterlogging Benchmark (UW-Bench) under diverse adverse conditions to advance real-world applications. We propose a Large-Small Model co-adapter paradigm (LSM-adapter), which harnesses the substantial generic segmentation potential of large model and the specific task-directed guidance of small model. Specifically, a Triple-S Prompt Adapter module alongside a Dynamic Prompt Combiner are proposed to generate then merge multiple prompts for mask decoder adaptation. Meanwhile, a Histogram Equalization Adap-ter module is designed to infuse the image specific information for image encoder adaptation. Results and analysis show the challenge and superiority of our developed benchmark and algorithm. Project page: \url{https://github.com/zhang-chenxu/LSM-Adapter}