 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwinAligner: Visual-Dynamic Alignment Empowers Physics-aware Real2Sim2Real for Robotic Manipulation
Dec 22, 2025The robotics field is evolving towards data-driven, end-to-end learning, inspired by multimodal large models. However, reliance on expensive real-world data limits progress. Simulators offer cost-effective alternatives, but the gap between simulation and reality challenges effective policy transfer. This paper introduces TwinAligner, a novel Real2Sim2Real system that addresses both visual and dynamic gaps. The visual alignment module achieves pixel-level alignment through SDF reconstruction and editable 3DGS rendering, while the dynamic alignment module ensures dynamic consistency by identifying rigid physics from robot-object interaction. TwinAligner improves robot learning by providing scalable data collection and establishing a trustworthy iterative cycle, accelerating algorithm development. Quantitative evaluations highlight TwinAligner's strong capabilities in visual and dynamic real-to-sim alignment. This system enables policies trained in simulation to achieve strong zero-shot generalization to the real world. The high consistency between real-world and simulated policy performance underscores TwinAligner's potential to advance scalable robot learning. Code and data will be released on https://twin-aligner.github.io
ClutterDexGrasp: A Sim-to-Real System for General Dexterous Grasping in Cluttered Scenes
Jun 17, 2025
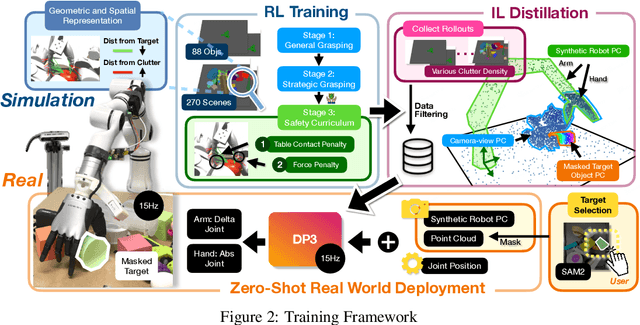


Dexterous grasping in cluttered scenes presents significant challenges due to diverse object geometries, occlusions, and potential collisions. Existing methods primarily focus on single-object grasping or grasp-pose prediction without interaction, which are insufficient for complex, cluttered scenes. Recent vision-language-action models offer a potential solution but require extensive real-world demonstrations, making them costly and difficult to scale. To address these limitations, we revisit the sim-to-real transfer pipeline and develop key techniques that enable zero-shot deployment in reality while maintaining robust generalization. We propose ClutterDexGrasp, a two-stage teacher-student framework for closed-loop target-oriented dexterous grasping in cluttered scenes. The framework features a teacher policy trained in simulation using clutter density curriculum learning, incorporating both a novel geometry and spatially-embedded scene representation and a comprehensive safety curriculum, enabling general, dynamic, and safe grasping behaviors. Through imitation learning, we distill the teacher's knowledge into a student 3D diffusion policy (DP3) that operates on partial point cloud observations. To the best of our knowledge, this represents the first zero-shot sim-to-real closed-loop system for target-oriented dexterous grasping in cluttered scenes, demonstrating robust performance across diverse objects and layouts. More details and videos are available at https://clutterdexgrasp.github.io/.
Variable-Friction In-Hand Manipulation for Arbitrary Objects via Diffusion-Based Imitation Learning
Mar 04, 2025



Dexterous in-hand manipulation (IHM) for arbitrary objects is challenging due to the rich and subtle contact process. Variable-friction manipulation is an alternative approach to dexterity, previously demonstrating robust and versatile 2D IHM capabilities with only two single-joint fingers. However, the hard-coded manipulation methods for variable friction hands are restricted to regular polygon objects and limited target poses, as well as requiring the policy to be tailored for each object. This paper proposes an end-to-end learning-based manipulation method to achieve arbitrary object manipulation for any target pose on real hardware, with minimal engineering efforts and data collection. The method features a diffusion policy-based imitation learning method with co-training from simulation and a small amount of real-world data. With the proposed framework, arbitrary objects including polygons and non-polygons can be precisely manipulated to reach arbitrary goal poses within 2 hours of training on an A100 GPU and only 1 hour of real-world data collection. The precision is higher than previous customized object-specific policies, achieving an average success rate of 71.3% with average pose error being 2.676 mm and 1.902 degrees.