 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrequency-Aware Flow Matching for Continuous and Consistent Robotic Action Generation
Jun 18, 2026Flow matching has emerged as a standard paradigm for robotic manipulation owing to its strong expressive power for modelling complex, multimodal action distributions, alongside similar approaches like diffusion policy. However, existing methods rely on discretized action chunks, making them brittle to demonstrations collected at heterogeneous control frequencies and prone to temporally inconsistent actions that degrade control stability. In this paper, we propose Frequency-Aware Flow Matching (FAFM), which outputs continuous, temporally consistent actions. To handle heterogeneous frequency input, we transform discrete action sequences into the frequency domain with the discrete cosine transform (DCT), perform flow matching over the resulting coefficients, and reconstruct continuous actions via cosine basis expansion. To generate temporally consistent actions, we regularize the first-order temporal derivative to promote smooth actions. This corresponds to a Sobolev-type constraint that suppresses high-frequency errors and discourages abrupt action changes. Our FAFM is simple, introduces no additional network parameters and applies to standalone flow-matching policies and vision-language action models. Across synthetic toy benchmark, obstacle avoidance, LapGym, and LIBERO, FAFM improves success rates, multimodal expressivity, motion smoothness, convergence speed, robustness to mechanical bias and mixed-frequency input. These gains are consistent when deployed on a real-world Franka robot. Code available at https://anonymous.4open.science/r/FAFM.
System Design for Maintaining Internal State Consistency in Long-Horizon Robotic Tabletop Games
Mar 26, 2026Long-horizon tabletop games pose a distinct systems challenge for robotics: small perceptual or execution errors can invalidate accumulated task state, propagate across decision-making modules, and ultimately derail interaction. This paper studies how to maintain internal state consistency in turn-based, multi-human robotic tabletop games through deliberate system design rather than isolated component improvement. Using Mahjong as a representative long-horizon setting, we present an integrated architecture that explicitly maintains perceptual, execution, and interaction state, partitions high-level semantic reasoning from time-critical perception and control, and incorporates verified action primitives with tactile-triggered recovery to prevent premature state corruption. We further introduce interaction-level monitoring mechanisms to detect turn violations and hidden-information breaches that threaten execution assumptions. Beyond demonstrating complete-game operation, we provide an empirical characterization of failure modes, recovery effectiveness, cross-module error propagation, and hardware-algorithm trade-offs observed during deployment. Our results show that explicit partitioning, monitored state transitions, and recovery mechanisms are critical for sustaining executable consistency over extended play, whereas monolithic or unverified pipelines lead to measurable degradation in end-to-end reliability. The proposed system serves as an empirical platform for studying system-level design principles in long-horizon, turn-based interaction.
CABTO: Context-Aware Behavior Tree Grounding for Robot Manipulation
Mar 17, 2026Behavior Trees (BTs) offer a powerful paradigm for designing modular and reactive robot controllers. BT planning, an emerging field, provides theoretical guarantees for the automated generation of reliable BTs. However, BT planning typically assumes that a well-designed BT system is already grounded -- comprising high-level action models and low-level control policies -- which often requires extensive expert knowledge and manual effort. In this paper, we formalize the BT Grounding problem: the automated construction of a complete and consistent BT system. We analyze its complexity and introduce CABTO (Context-Aware Behavior Tree grOunding), the first framework to efficiently solve this challenge. CABTO leverages pre-trained Large Models (LMs) to heuristically search the space of action models and control policies, guided by contextual feedback from BT planners and environmental observations. Experiments spanning seven task sets across three distinct robotic manipulation scenarios demonstrate CABTO's effectiveness and efficiency in generating complete and consistent behavior tree systems.
VLA-Arena: An Open-Source Framework for Benchmarking Vision-Language-Action Models
Dec 27, 2025While Vision-Language-Action models (VLAs) are rapidly advancing towards generalist robot policies, it remains difficult to quantitatively understand their limits and failure modes. To address this, we introduce a comprehensive benchmark called VLA-Arena. We propose a novel structured task design framework to quantify difficulty across three orthogonal axes: (1) Task Structure, (2) Language Command, and (3) Visual Observation. This allows us to systematically design tasks with fine-grained difficulty levels, enabling a precise measurement of model capability frontiers. For Task Structure, VLA-Arena's 170 tasks are grouped into four dimensions: Safety, Distractor, Extrapolation, and Long Horizon. Each task is designed with three difficulty levels (L0-L2), with fine-tuning performed exclusively on L0 to assess general capability. Orthogonal to this, language (W0-W4) and visual (V0-V4) perturbations can be applied to any task to enable a decoupled analysis of robustness. Our extensive evaluation of state-of-the-art VLAs reveals several critical limitations, including a strong tendency toward memorization over generalization, asymmetric robustness, a lack of consideration for safety constraints, and an inability to compose learned skills for long-horizon tasks. To foster research addressing these challenges and ensure reproducibility, we provide the complete VLA-Arena framework, including an end-to-end toolchain from task definition to automated evaluation and the VLA-Arena-S/M/L datasets for fine-tuning. Our benchmark, data, models, and leaderboard are available at https://vla-arena.github.io.
HERMES: Human-to-Robot Embodied Learning from Multi-Source Motion Data for Mobile Dexterous Manipulation
Aug 28, 2025Leveraging human motion data to impart robots with versatile manipulation skills has emerged as a promising paradigm in robotic manipulation. Nevertheless, translating multi-source human hand motions into feasible robot behaviors remains challenging, particularly for robots equipped with multi-fingered dexterous hands characterized by complex, high-dimensional action spaces. Moreover, existing approaches often struggle to produce policies capable of adapting to diverse environmental conditions. In this paper, we introduce HERMES, a human-to-robot learning framework for mobile bimanual dexterous manipulation. First, HERMES formulates a unified reinforcement learning approach capable of seamlessly transforming heterogeneous human hand motions from multiple sources into physically plausible robotic behaviors. Subsequently, to mitigate the sim2real gap, we devise an end-to-end, depth image-based sim2real transfer method for improved generalization to real-world scenarios. Furthermore, to enable autonomous operation in varied and unstructured environments, we augment the navigation foundation model with a closed-loop Perspective-n-Point (PnP) localization mechanism, ensuring precise alignment of visual goals and effectively bridging autonomous navigation and dexterous manipulation. Extensive experimental results demonstrate that HERMES consistently exhibits generalizable behaviors across diverse, in-the-wild scenarios, successfully performing numerous complex mobile bimanual dexterous manipulation tasks. Project Page:https://gemcollector.github.io/HERMES/.
A Survey on Vision-Language-Action Models: An Action Tokenization Perspective
Jul 02, 2025The remarkable advancements of vision and language foundation models in multimodal understanding, reasoning, and generation has sparked growing efforts to extend such intelligence to the physical world, fueling the flourishing of vision-language-action (VLA) models. Despite seemingly diverse approaches, we observe that current VLA models can be unified under a single framework: vision and language inputs are processed by a series of VLA modules, producing a chain of \textit{action tokens} that progressively encode more grounded and actionable information, ultimately generating executable actions. We further determine that the primary design choice distinguishing VLA models lies in how action tokens are formulated, which can be categorized into language description, code, affordance, trajectory, goal state, latent representation, raw action, and reasoning. However, there remains a lack of comprehensive understanding regarding action tokens, significantly impeding effective VLA development and obscuring future directions. Therefore, this survey aims to categorize and interpret existing VLA research through the lens of action tokenization, distill the strengths and limitations of each token type, and identify areas for improvement. Through this systematic review and analysis, we offer a synthesized outlook on the broader evolution of VLA models, highlight underexplored yet promising directions, and contribute guidance for future research, hoping to bring the field closer to general-purpose intelligence.
ClutterDexGrasp: A Sim-to-Real System for General Dexterous Grasping in Cluttered Scenes
Jun 17, 2025
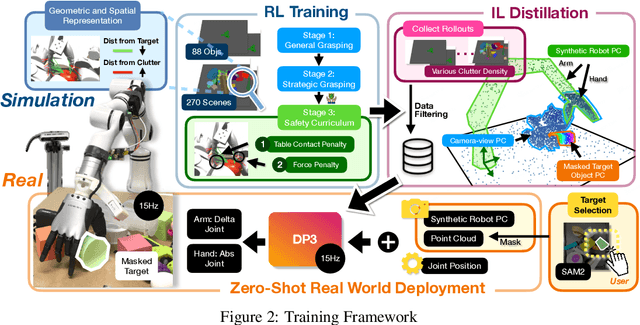


Dexterous grasping in cluttered scenes presents significant challenges due to diverse object geometries, occlusions, and potential collisions. Existing methods primarily focus on single-object grasping or grasp-pose prediction without interaction, which are insufficient for complex, cluttered scenes. Recent vision-language-action models offer a potential solution but require extensive real-world demonstrations, making them costly and difficult to scale. To address these limitations, we revisit the sim-to-real transfer pipeline and develop key techniques that enable zero-shot deployment in reality while maintaining robust generalization. We propose ClutterDexGrasp, a two-stage teacher-student framework for closed-loop target-oriented dexterous grasping in cluttered scenes. The framework features a teacher policy trained in simulation using clutter density curriculum learning, incorporating both a novel geometry and spatially-embedded scene representation and a comprehensive safety curriculum, enabling general, dynamic, and safe grasping behaviors. Through imitation learning, we distill the teacher's knowledge into a student 3D diffusion policy (DP3) that operates on partial point cloud observations. To the best of our knowledge, this represents the first zero-shot sim-to-real closed-loop system for target-oriented dexterous grasping in cluttered scenes, demonstrating robust performance across diverse objects and layouts. More details and videos are available at https://clutterdexgrasp.github.io/.
ReverB-SNN: Reversing Bit of the Weight and Activation for Spiking Neural Networks
Jun 09, 2025The Spiking Neural Network (SNN), a biologically inspired neural network infrastructure, has garnered significant attention recently. SNNs utilize binary spike activations for efficient information transmission, replacing multiplications with additions, thereby enhancing energy efficiency. However, binary spike activation maps often fail to capture sufficient data information, resulting in reduced accuracy. To address this challenge, we advocate reversing the bit of the weight and activation for SNNs, called \textbf{ReverB-SNN}, inspired by recent findings that highlight greater accuracy degradation from quantizing activations compared to weights. Specifically, our method employs real-valued spike activations alongside binary weights in SNNs. This preserves the event-driven and multiplication-free advantages of standard SNNs while enhancing the information capacity of activations. Additionally, we introduce a trainable factor within binary weights to adaptively learn suitable weight amplitudes during training, thereby increasing network capacity. To maintain efficiency akin to vanilla \textbf{ReverB-SNN}, our trainable binary weight SNNs are converted back to standard form using a re-parameterization technique during inference. Extensive experiments across various network architectures and datasets, both static and dynamic, demonstrate that our approach consistently outperforms state-of-the-art methods.
From Strangers to Assistants: Fast Desire Alignment for Embodied Agent-User Adaptation
May 28, 2025While embodied agents have made significant progress in performing complex physical tasks, real-world applications demand more than pure task execution. The agents must collaborate with unfamiliar agents and human users, whose goals are often vague and implicit. In such settings, interpreting ambiguous instructions and uncovering underlying desires is essential for effective assistance. Therefore, fast and accurate desire alignment becomes a critical capability for embodied agents. In this work, we first develop a home assistance simulation environment HA-Desire that integrates an LLM-driven human user agent exhibiting realistic value-driven goal selection and communication. The ego agent must interact with this proxy user to infer and adapt to the user's latent desires. To achieve this, we present a novel framework FAMER for fast desire alignment, which introduces a desire-based mental reasoning mechanism to identify user intent and filter desire-irrelevant actions. We further design a reflection-based communication module that reduces redundant inquiries, and incorporate goal-relevant information extraction with memory persistence to improve information reuse and reduce unnecessary exploration. Extensive experiments demonstrate that our framework significantly enhances both task execution and communication efficiency, enabling embodied agents to quickly adapt to user-specific desires in complex embodied environments.
Dexterous Non-Prehensile Manipulation for Ungraspable Object via Extrinsic Dexterity
Mar 29, 2025



Objects with large base areas become ungraspable when they exceed the end-effector's maximum aperture. Existing approaches address this limitation through extrinsic dexterity, which exploits environmental features for non-prehensile manipulation. While grippers have shown some success in this domain, dexterous hands offer superior flexibility and manipulation capabilities that enable richer environmental interactions, though they present greater control challenges. Here we present ExDex, a dexterous arm-hand system that leverages reinforcement learning to enable non-prehensile manipulation for grasping ungraspable objects. Our system learns two strategic manipulation sequences: relocating objects from table centers to edges for direct grasping, or to walls where extrinsic dexterity enables grasping through environmental interaction. We validate our approach through extensive experiments with dozens of diverse household objects, demonstrating both superior performance and generalization capabilities with novel objects. Furthermore, we successfully transfer the learned policies from simulation to a real-world robot system without additional training, further demonstrating its applicability in real-world scenarios. Project website: https://tangty11.github.io/ExDex/.