 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSVG-T2I: Scaling Up Text-to-Image Latent Diffusion Model Without Variational Autoencoder
Dec 12, 2025Visual generation grounded in Visual Foundation Model (VFM) representations offers a highly promising unified pathway for integrating visual understanding, perception, and generation. Despite this potential, training large-scale text-to-image diffusion models entirely within the VFM representation space remains largely unexplored. To bridge this gap, we scale the SVG (Self-supervised representations for Visual Generation) framework, proposing SVG-T2I to support high-quality text-to-image synthesis directly in the VFM feature domain. By leveraging a standard text-to-image diffusion pipeline, SVG-T2I achieves competitive performance, reaching 0.75 on GenEval and 85.78 on DPG-Bench. This performance validates the intrinsic representational power of VFMs for generative tasks. We fully open-source the project, including the autoencoder and generation model, together with their training, inference, evaluation pipelines, and pre-trained weights, to facilitate further research in representation-driven visual generation.
MVU-Eval: Towards Multi-Video Understanding Evaluation for Multimodal LLMs
Nov 13, 2025



The advent of Multimodal Large Language Models (MLLMs) has expanded AI capabilities to visual modalities, yet existing evaluation benchmarks remain limited to single-video understanding, overlooking the critical need for multi-video understanding in real-world scenarios (e.g., sports analytics and autonomous driving). To address this significant gap, we introduce MVU-Eval, the first comprehensive benchmark for evaluating Multi-Video Understanding for MLLMs. Specifically, our MVU-Eval mainly assesses eight core competencies through 1,824 meticulously curated question-answer pairs spanning 4,959 videos from diverse domains, addressing both fundamental perception tasks and high-order reasoning tasks. These capabilities are rigorously aligned with real-world applications such as multi-sensor synthesis in autonomous systems and cross-angle sports analytics. Through extensive evaluation of state-of-the-art open-source and closed-source models, we reveal significant performance discrepancies and limitations in current MLLMs' ability to perform understanding across multiple videos. The benchmark will be made publicly available to foster future research.
Simulating the Visual World with Artificial Intelligence: A Roadmap
Nov 11, 2025The landscape of video generation is shifting, from a focus on generating visually appealing clips to building virtual environments that support interaction and maintain physical plausibility. These developments point toward the emergence of video foundation models that function not only as visual generators but also as implicit world models, models that simulate the physical dynamics, agent-environment interactions, and task planning that govern real or imagined worlds. This survey provides a systematic overview of this evolution, conceptualizing modern video foundation models as the combination of two core components: an implicit world model and a video renderer. The world model encodes structured knowledge about the world, including physical laws, interaction dynamics, and agent behavior. It serves as a latent simulation engine that enables coherent visual reasoning, long-term temporal consistency, and goal-driven planning. The video renderer transforms this latent simulation into realistic visual observations, effectively producing videos as a "window" into the simulated world. We trace the progression of video generation through four generations, in which the core capabilities advance step by step, ultimately culminating in a world model, built upon a video generation model, that embodies intrinsic physical plausibility, real-time multimodal interaction, and planning capabilities spanning multiple spatiotemporal scales. For each generation, we define its core characteristics, highlight representative works, and examine their application domains such as robotics, autonomous driving, and interactive gaming. Finally, we discuss open challenges and design principles for next-generation world models, including the role of agent intelligence in shaping and evaluating these systems. An up-to-date list of related works is maintained at this link.
RelightMaster: Precise Video Relighting with Multi-plane Light Images
Nov 09, 2025Recent advances in diffusion models enable high-quality video generation and editing, but precise relighting with consistent video contents, which is critical for shaping scene atmosphere and viewer attention, remains unexplored. Mainstream text-to-video (T2V) models lack fine-grained lighting control due to text's inherent limitation in describing lighting details and insufficient pre-training on lighting-related prompts. Additionally, constructing high-quality relighting training data is challenging, as real-world controllable lighting data is scarce. To address these issues, we propose RelightMaster, a novel framework for accurate and controllable video relighting. First, we build RelightVideo, the first dataset with identical dynamic content under varying precise lighting conditions based on the Unreal Engine. Then, we introduce Multi-plane Light Image (MPLI), a novel visual prompt inspired by Multi-Plane Image (MPI). MPLI models lighting via K depth-aligned planes, representing 3D light source positions, intensities, and colors while supporting multi-source scenarios and generalizing to unseen light setups. Third, we design a Light Image Adapter that seamlessly injects MPLI into pre-trained Video Diffusion Transformers (DiT): it compresses MPLI via a pre-trained Video VAE and injects latent light features into DiT blocks, leveraging the base model's generative prior without catastrophic forgetting. Experiments show that RelightMaster generates physically plausible lighting and shadows and preserves original scene content. Demos are available at https://wkbian.github.io/Projects/RelightMaster/.
OmniX: From Unified Panoramic Generation and Perception to Graphics-Ready 3D Scenes
Oct 30, 2025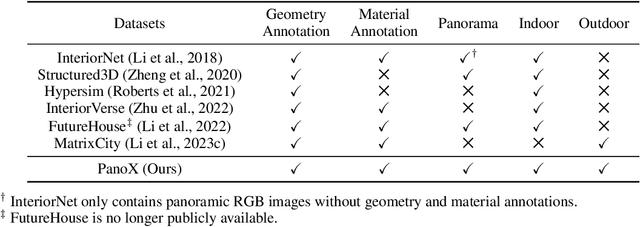

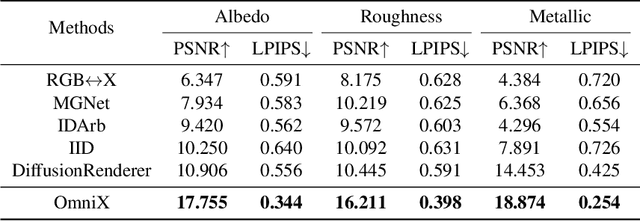
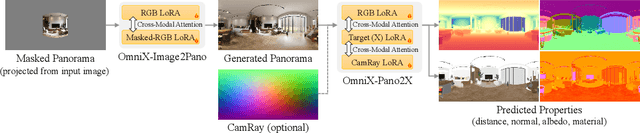
There are two prevalent ways to constructing 3D scenes: procedural generation and 2D lifting. Among them, panorama-based 2D lifting has emerged as a promising technique, leveraging powerful 2D generative priors to produce immersive, realistic, and diverse 3D environments. In this work, we advance this technique to generate graphics-ready 3D scenes suitable for physically based rendering (PBR), relighting, and simulation. Our key insight is to repurpose 2D generative models for panoramic perception of geometry, textures, and PBR materials. Unlike existing 2D lifting approaches that emphasize appearance generation and ignore the perception of intrinsic properties, we present OmniX, a versatile and unified framework. Based on a lightweight and efficient cross-modal adapter structure, OmniX reuses 2D generative priors for a broad range of panoramic vision tasks, including panoramic perception, generation, and completion. Furthermore, we construct a large-scale synthetic panorama dataset containing high-quality multimodal panoramas from diverse indoor and outdoor scenes. Extensive experiments demonstrate the effectiveness of our model in panoramic visual perception and graphics-ready 3D scene generation, opening new possibilities for immersive and physically realistic virtual world generation.
VFXMaster: Unlocking Dynamic Visual Effect Generation via In-Context Learning
Oct 29, 2025Visual effects (VFX) are crucial to the expressive power of digital media, yet their creation remains a major challenge for generative AI. Prevailing methods often rely on the one-LoRA-per-effect paradigm, which is resource-intensive and fundamentally incapable of generalizing to unseen effects, thus limiting scalability and creation. To address this challenge, we introduce VFXMaster, the first unified, reference-based framework for VFX video generation. It recasts effect generation as an in-context learning task, enabling it to reproduce diverse dynamic effects from a reference video onto target content. In addition, it demonstrates remarkable generalization to unseen effect categories. Specifically, we design an in-context conditioning strategy that prompts the model with a reference example. An in-context attention mask is designed to precisely decouple and inject the essential effect attributes, allowing a single unified model to master the effect imitation without information leakage. In addition, we propose an efficient one-shot effect adaptation mechanism to boost generalization capability on tough unseen effects from a single user-provided video rapidly. Extensive experiments demonstrate that our method effectively imitates various categories of effect information and exhibits outstanding generalization to out-of-domain effects. To foster future research, we will release our code, models, and a comprehensive dataset to the community.
GRPO-Guard: Mitigating Implicit Over-Optimization in Flow Matching via Regulated Clipping
Oct 25, 2025Recently, GRPO-based reinforcement learning has shown remarkable progress in optimizing flow-matching models, effectively improving their alignment with task-specific rewards. Within these frameworks, the policy update relies on importance-ratio clipping to constrain overconfident positive and negative gradients. However, in practice, we observe a systematic shift in the importance-ratio distribution-its mean falls below 1 and its variance differs substantially across timesteps. This left-shifted and inconsistent distribution prevents positive-advantage samples from entering the clipped region, causing the mechanism to fail in constraining overconfident positive updates. As a result, the policy model inevitably enters an implicit over-optimization stage-while the proxy reward continues to increase, essential metrics such as image quality and text-prompt alignment deteriorate sharply, ultimately making the learned policy impractical for real-world use. To address this issue, we introduce GRPO-Guard, a simple yet effective enhancement to existing GRPO frameworks. Our method incorporates ratio normalization, which restores a balanced and step-consistent importance ratio, ensuring that PPO clipping properly constrains harmful updates across denoising timesteps. In addition, a gradient reweighting strategy equalizes policy gradients over noise conditions, preventing excessive updates from particular timestep regions. Together, these designs act as a regulated clipping mechanism, stabilizing optimization and substantially mitigating implicit over-optimization without relying on heavy KL regularization. Extensive experiments on multiple diffusion backbones (e.g., SD3.5M, Flux.1-dev) and diverse proxy tasks demonstrate that GRPO-Guard significantly reduces over-optimization while maintaining or even improving generation quality.
Harnessing Uncertainty: Entropy-Modulated Policy Gradients for Long-Horizon LLM Agents
Sep 11, 2025In long-horizon tasks, recent agents based on Large Language Models (LLMs) face a significant challenge that sparse, outcome-based rewards make it difficult to assign credit to intermediate steps. Previous methods mainly focus on creating dense reward signals to guide learning, either through traditional reinforcement learning techniques like inverse reinforcement learning or by using Process Reward Models for step-by-step feedback. In this paper, we identify a fundamental problem in the learning dynamics of LLMs: the magnitude of policy gradients is inherently coupled with the entropy, which leads to inefficient small updates for confident correct actions and potentially destabilizes large updates for uncertain ones. To resolve this, we propose Entropy-Modulated Policy Gradients (EMPG), a framework that re-calibrates the learning signal based on step-wise uncertainty and the final task outcome. EMPG amplifies updates for confident correct actions, penalizes confident errors, and attenuates updates from uncertain steps to stabilize exploration. We further introduce a bonus term for future clarity that encourages agents to find more predictable solution paths. Through comprehensive experiments on three challenging agent tasks, WebShop, ALFWorld, and Deep Search, we demonstrate that EMPG achieves substantial performance gains and significantly outperforms strong policy gradient baselines. Project page is at https://empgseed-seed.github.io/
Curse of Knowledge: When Complex Evaluation Context Benefits yet Biases LLM Judges
Sep 03, 2025As large language models (LLMs) grow more capable, they face increasingly diverse and complex tasks, making reliable evaluation challenging. The paradigm of LLMs as judges has emerged as a scalable solution, yet prior work primarily focuses on simple settings. Their reliability in complex tasks--where multi-faceted rubrics, unstructured reference answers, and nuanced criteria are critical--remains understudied. In this paper, we constructed ComplexEval, a challenge benchmark designed to systematically expose and quantify Auxiliary Information Induced Biases. We systematically investigated and validated 6 previously unexplored biases across 12 basic and 3 advanced scenarios. Key findings reveal: (1) all evaluated models exhibit significant susceptibility to these biases, with bias magnitude scaling with task complexity; (2) notably, Large Reasoning Models (LRMs) show paradoxical vulnerability. Our in-depth analysis offers crucial insights for improving the accuracy and verifiability of evaluation signals, paving the way for more general and robust evaluation models.
SimpleGVR: A Simple Baseline for Latent-Cascaded Video Super-Resolution
Jun 24, 2025Latent diffusion models have emerged as a leading paradigm for efficient video generation. However, as user expectations shift toward higher-resolution outputs, relying solely on latent computation becomes inadequate. A promising approach involves decoupling the process into two stages: semantic content generation and detail synthesis. The former employs a computationally intensive base model at lower resolutions, while the latter leverages a lightweight cascaded video super-resolution (VSR) model to achieve high-resolution output. In this work, we focus on studying key design principles for latter cascaded VSR models, which are underexplored currently. First, we propose two degradation strategies to generate training pairs that better mimic the output characteristics of the base model, ensuring alignment between the VSR model and its upstream generator. Second, we provide critical insights into VSR model behavior through systematic analysis of (1) timestep sampling strategies, (2) noise augmentation effects on low-resolution (LR) inputs. These findings directly inform our architectural and training innovations. Finally, we introduce interleaving temporal unit and sparse local attention to achieve efficient training and inference, drastically reducing computational overhead. Extensive experiments demonstrate the superiority of our framework over existing methods, with ablation studies confirming the efficacy of each design choice. Our work establishes a simple yet effective baseline for cascaded video super-resolution generation, offering practical insights to guide future advancements in efficient cascaded synthesis systems.