 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCineScene: Implicit 3D as Effective Scene Representation for Cinematic Video Generation
Feb 06, 2026Cinematic video production requires control over scene-subject composition and camera movement, but live-action shooting remains costly due to the need for constructing physical sets. To address this, we introduce the task of cinematic video generation with decoupled scene context: given multiple images of a static environment, the goal is to synthesize high-quality videos featuring dynamic subject while preserving the underlying scene consistency and following a user-specified camera trajectory. We present CineScene, a framework that leverages implicit 3D-aware scene representation for cinematic video generation. Our key innovation is a novel context conditioning mechanism that injects 3D-aware features in an implicit way: By encoding scene images into visual representations through VGGT, CineScene injects spatial priors into a pretrained text-to-video generation model by additional context concatenation, enabling camera-controlled video synthesis with consistent scenes and dynamic subjects. To further enhance the model's robustness, we introduce a simple yet effective random-shuffling strategy for the input scene images during training. To address the lack of training data, we construct a scene-decoupled dataset with Unreal Engine 5, containing paired videos of scenes with and without dynamic subjects, panoramic images representing the underlying static scene, along with their camera trajectories. Experiments show that CineScene achieves state-of-the-art performance in scene-consistent cinematic video generation, handling large camera movements and demonstrating generalization across diverse environments.
OmniX: From Unified Panoramic Generation and Perception to Graphics-Ready 3D Scenes
Oct 30, 2025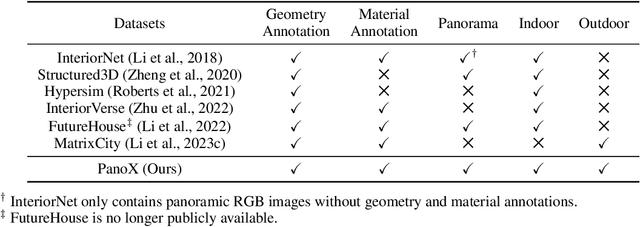

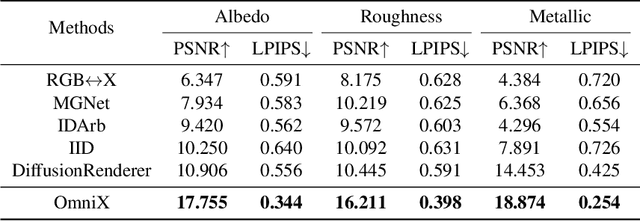
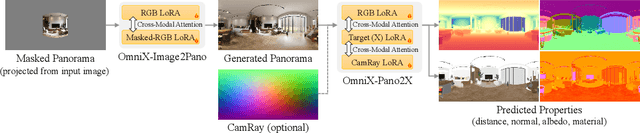
There are two prevalent ways to constructing 3D scenes: procedural generation and 2D lifting. Among them, panorama-based 2D lifting has emerged as a promising technique, leveraging powerful 2D generative priors to produce immersive, realistic, and diverse 3D environments. In this work, we advance this technique to generate graphics-ready 3D scenes suitable for physically based rendering (PBR), relighting, and simulation. Our key insight is to repurpose 2D generative models for panoramic perception of geometry, textures, and PBR materials. Unlike existing 2D lifting approaches that emphasize appearance generation and ignore the perception of intrinsic properties, we present OmniX, a versatile and unified framework. Based on a lightweight and efficient cross-modal adapter structure, OmniX reuses 2D generative priors for a broad range of panoramic vision tasks, including panoramic perception, generation, and completion. Furthermore, we construct a large-scale synthetic panorama dataset containing high-quality multimodal panoramas from diverse indoor and outdoor scenes. Extensive experiments demonstrate the effectiveness of our model in panoramic visual perception and graphics-ready 3D scene generation, opening new possibilities for immersive and physically realistic virtual world generation.
OmniPart: Part-Aware 3D Generation with Semantic Decoupling and Structural Cohesion
Jul 08, 2025The creation of 3D assets with explicit, editable part structures is crucial for advancing interactive applications, yet most generative methods produce only monolithic shapes, limiting their utility. We introduce OmniPart, a novel framework for part-aware 3D object generation designed to achieve high semantic decoupling among components while maintaining robust structural cohesion. OmniPart uniquely decouples this complex task into two synergistic stages: (1) an autoregressive structure planning module generates a controllable, variable-length sequence of 3D part bounding boxes, critically guided by flexible 2D part masks that allow for intuitive control over part decomposition without requiring direct correspondences or semantic labels; and (2) a spatially-conditioned rectified flow model, efficiently adapted from a pre-trained holistic 3D generator, synthesizes all 3D parts simultaneously and consistently within the planned layout. Our approach supports user-defined part granularity, precise localization, and enables diverse downstream applications. Extensive experiments demonstrate that OmniPart achieves state-of-the-art performance, paving the way for more interpretable, editable, and versatile 3D content.
DreamComposer++: Empowering Diffusion Models with Multi-View Conditions for 3D Content Generation
Jul 03, 2025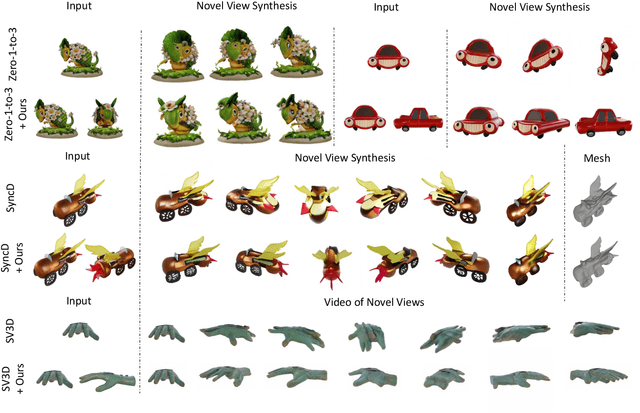
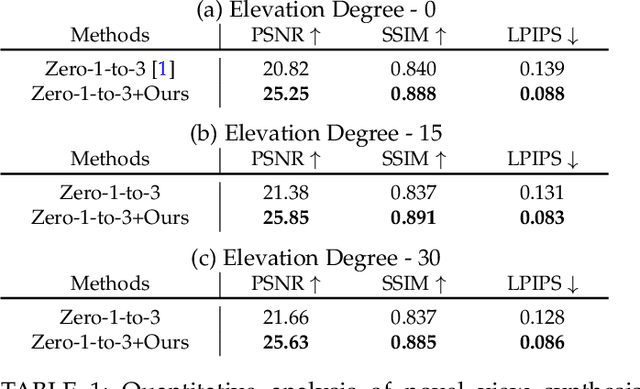
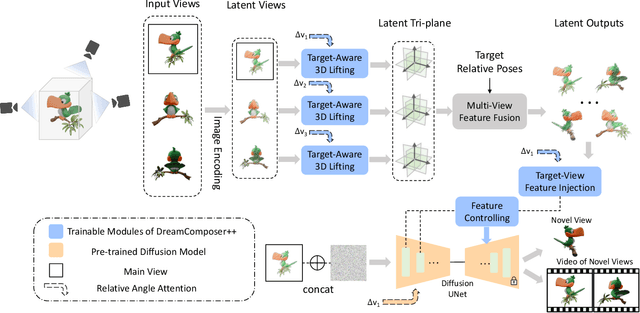

Recent advancements in leveraging pre-trained 2D diffusion models achieve the generation of high-quality novel views from a single in-the-wild image. However, existing works face challenges in producing controllable novel views due to the lack of information from multiple views. In this paper, we present DreamComposer++, a flexible and scalable framework designed to improve current view-aware diffusion models by incorporating multi-view conditions. Specifically, DreamComposer++ utilizes a view-aware 3D lifting module to extract 3D representations of an object from various views. These representations are then aggregated and rendered into the latent features of target view through the multi-view feature fusion module. Finally, the obtained features of target view are integrated into pre-trained image or video diffusion models for novel view synthesis. Experimental results demonstrate that DreamComposer++ seamlessly integrates with cutting-edge view-aware diffusion models and enhances their abilities to generate controllable novel views from multi-view conditions. This advancement facilitates controllable 3D object reconstruction and enables a wide range of applications.
FilMaster: Bridging Cinematic Principles and Generative AI for Automated Film Generation
Jun 23, 2025AI-driven content creation has shown potential in film production. However, existing film generation systems struggle to implement cinematic principles and thus fail to generate professional-quality films, particularly lacking diverse camera language and cinematic rhythm. This results in templated visuals and unengaging narratives. To address this, we introduce FilMaster, an end-to-end AI system that integrates real-world cinematic principles for professional-grade film generation, yielding editable, industry-standard outputs. FilMaster is built on two key principles: (1) learning cinematography from extensive real-world film data and (2) emulating professional, audience-centric post-production workflows. Inspired by these principles, FilMaster incorporates two stages: a Reference-Guided Generation Stage which transforms user input to video clips, and a Generative Post-Production Stage which transforms raw footage into audiovisual outputs by orchestrating visual and auditory elements for cinematic rhythm. Our generation stage highlights a Multi-shot Synergized RAG Camera Language Design module to guide the AI in generating professional camera language by retrieving reference clips from a vast corpus of 440,000 film clips. Our post-production stage emulates professional workflows by designing an Audience-Centric Cinematic Rhythm Control module, including Rough Cut and Fine Cut processes informed by simulated audience feedback, for effective integration of audiovisual elements to achieve engaging content. The system is empowered by generative AI models like (M)LLMs and video generation models. Furthermore, we introduce FilmEval, a comprehensive benchmark for evaluating AI-generated films. Extensive experiments show FilMaster's superior performance in camera language design and cinematic rhythm control, advancing generative AI in professional filmmaking.
HoloPart: Generative 3D Part Amodal Segmentation
Apr 10, 20253D part amodal segmentation--decomposing a 3D shape into complete, semantically meaningful parts, even when occluded--is a challenging but crucial task for 3D content creation and understanding. Existing 3D part segmentation methods only identify visible surface patches, limiting their utility. Inspired by 2D amodal segmentation, we introduce this novel task to the 3D domain and propose a practical, two-stage approach, addressing the key challenges of inferring occluded 3D geometry, maintaining global shape consistency, and handling diverse shapes with limited training data. First, we leverage existing 3D part segmentation to obtain initial, incomplete part segments. Second, we introduce HoloPart, a novel diffusion-based model, to complete these segments into full 3D parts. HoloPart utilizes a specialized architecture with local attention to capture fine-grained part geometry and global shape context attention to ensure overall shape consistency. We introduce new benchmarks based on the ABO and PartObjaverse-Tiny datasets and demonstrate that HoloPart significantly outperforms state-of-the-art shape completion methods. By incorporating HoloPart with existing segmentation techniques, we achieve promising results on 3D part amodal segmentation, opening new avenues for applications in geometry editing, animation, and material assignment.
Fuzzy Speculative Decoding for a Tunable Accuracy-Runtime Tradeoff
Feb 28, 2025



Speculative Decoding (SD) enforces strict distributional equivalence to the target model, limiting potential speed ups as distributions of near-equivalence achieve comparable outcomes in many cases. Furthermore, enforcing distributional equivalence means that users are unable to trade deviations from the target model distribution for further inference speed gains. To address these limitations, we introduce Fuzzy Speculative Decoding (FSD) - a decoding algorithm that generalizes SD by accepting candidate tokens purely based on the divergences between the target and draft model distributions. By allowing for controlled divergence from the target model, FSD enables users to flexibly trade generation quality for inference speed. Across several benchmarks, our method is able to achieve significant runtime improvements of over 5 tokens per second faster than SD at only an approximate 2% absolute reduction in benchmark accuracy. In many cases, FSD is even able to match SD benchmark accuracy at over 2 tokens per second faster, demonstrating that distributional equivalence is not necessary to maintain target model performance.
GenMAC: Compositional Text-to-Video Generation with Multi-Agent Collaboration
Dec 05, 2024



Text-to-video generation models have shown significant progress in the recent years. However, they still struggle with generating complex dynamic scenes based on compositional text prompts, such as attribute binding for multiple objects, temporal dynamics associated with different objects, and interactions between objects. Our key motivation is that complex tasks can be decomposed into simpler ones, each handled by a role-specialized MLLM agent. Multiple agents can collaborate together to achieve collective intelligence for complex goals. We propose GenMAC, an iterative, multi-agent framework that enables compositional text-to-video generation. The collaborative workflow includes three stages: Design, Generation, and Redesign, with an iterative loop between the Generation and Redesign stages to progressively verify and refine the generated videos. The Redesign stage is the most challenging stage that aims to verify the generated videos, suggest corrections, and redesign the text prompts, frame-wise layouts, and guidance scales for the next iteration of generation. To avoid hallucination of a single MLLM agent, we decompose this stage to four sequentially-executed MLLM-based agents: verification agent, suggestion agent, correction agent, and output structuring agent. Furthermore, to tackle diverse scenarios of compositional text-to-video generation, we design a self-routing mechanism to adaptively select the proper correction agent from a collection of correction agents each specialized for one scenario. Extensive experiments demonstrate the effectiveness of GenMAC, achieving state-of-the art performance in compositional text-to-video generation.
The Matrix: Infinite-Horizon World Generation with Real-Time Moving Control
Dec 04, 2024



We present The Matrix, the first foundational realistic world simulator capable of generating continuous 720p high-fidelity real-scene video streams with real-time, responsive control in both first- and third-person perspectives, enabling immersive exploration of richly dynamic environments. Trained on limited supervised data from AAA games like Forza Horizon 5 and Cyberpunk 2077, complemented by large-scale unsupervised footage from real-world settings like Tokyo streets, The Matrix allows users to traverse diverse terrains -- deserts, grasslands, water bodies, and urban landscapes -- in continuous, uncut hour-long sequences. Operating at 16 FPS, the system supports real-time interactivity and demonstrates zero-shot generalization, translating virtual game environments to real-world contexts where collecting continuous movement data is often infeasible. For example, The Matrix can simulate a BMW X3 driving through an office setting--an environment present in neither gaming data nor real-world sources. This approach showcases the potential of AAA game data to advance robust world models, bridging the gap between simulations and real-world applications in scenarios with limited data.
SAMPart3D: Segment Any Part in 3D Objects
Nov 11, 2024



3D part segmentation is a crucial and challenging task in 3D perception, playing a vital role in applications such as robotics, 3D generation, and 3D editing. Recent methods harness the powerful Vision Language Models (VLMs) for 2D-to-3D knowledge distillation, achieving zero-shot 3D part segmentation. However, these methods are limited by their reliance on text prompts, which restricts the scalability to large-scale unlabeled datasets and the flexibility in handling part ambiguities. In this work, we introduce SAMPart3D, a scalable zero-shot 3D part segmentation framework that segments any 3D object into semantic parts at multiple granularities, without requiring predefined part label sets as text prompts. For scalability, we use text-agnostic vision foundation models to distill a 3D feature extraction backbone, allowing scaling to large unlabeled 3D datasets to learn rich 3D priors. For flexibility, we distill scale-conditioned part-aware 3D features for 3D part segmentation at multiple granularities. Once the segmented parts are obtained from the scale-conditioned part-aware 3D features, we use VLMs to assign semantic labels to each part based on the multi-view renderings. Compared to previous methods, our SAMPart3D can scale to the recent large-scale 3D object dataset Objaverse and handle complex, non-ordinary objects. Additionally, we contribute a new 3D part segmentation benchmark to address the lack of diversity and complexity of objects and parts in existing benchmarks. Experiments show that our SAMPart3D significantly outperforms existing zero-shot 3D part segmentation methods, and can facilitate various applications such as part-level editing and interactive segmentation.