 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnchorWorld: Embodied Egocentric World Simulation with View-based Evolution Customization
Jun 05, 2026Despite being a pivotal frontier, interactive world modeling remains underexplored in terms of the versatile controllability required by practical scenarios. To bridge this gap, we present AnchorWorld, a framework that advances egocentric simulation through enhanced interaction integrity and a flexible mechanism for world customization. First, we utilize 3D human motion as the primary interaction modality. To complement the out-of-view or truncated body parts in egocentric views, we introduce an auxiliary training supervision that incorporates exogenous viewpoints decoupled from the agent's first-person sensorium. It allows the model to observe the agent's full-body positioning relative to the environment, facilitating a more robust spatial grounding of human-world interactions. Furthermore, we propose a simple yet effective mechanism for customizing self-evolving worlds. This is achieved by defining anchor views within a unified world coordinate system, coupled with textual descriptions dictating the dynamic evolution of local scenes. Experimental results show that AnchorWorld significantly outperforms state-of-the-art baselines, while ablation studies validate the effectiveness of our key designs. Notably, our customization scheme exhibits promising spatio-temporal geometric consistency and adheres strictly to the prescribed evolutionary dynamics.
DUO-VSR: Dual-Stream Distillation for One-Step Video Super-Resolution
Mar 23, 2026Diffusion-based video super-resolution (VSR) has recently achieved remarkable fidelity but still suffers from prohibitive sampling costs. While distribution matching distillation (DMD) can accelerate diffusion models toward one-step generation, directly applying it to VSR often results in training instability alongside degraded and insufficient supervision. To address these issues, we propose DUO-VSR, a three-stage framework built upon a Dual-Stream Distillation strategy that unifies distribution matching and adversarial supervision for one-step VSR. Firstly, a Progressive Guided Distillation Initialization is employed to stabilize subsequent training through trajectory-preserving distillation. Next, the Dual-Stream Distillation jointly optimizes the DMD and Real-Fake Score Feature GAN (RFS-GAN) streams, with the latter providing complementary adversarial supervision leveraging discriminative features from both real and fake score models. Finally, a Preference-Guided Refinement stage further aligns the student with perceptual quality preferences. Extensive experiments demonstrate that DUO-VSR achieves superior visual quality and efficiency over previous one-step VSR approaches.
SemanticGen: Video Generation in Semantic Space
Dec 24, 2025



State-of-the-art video generative models typically learn the distribution of video latents in the VAE space and map them to pixels using a VAE decoder. While this approach can generate high-quality videos, it suffers from slow convergence and is computationally expensive when generating long videos. In this paper, we introduce SemanticGen, a novel solution to address these limitations by generating videos in the semantic space. Our main insight is that, due to the inherent redundancy in videos, the generation process should begin in a compact, high-level semantic space for global planning, followed by the addition of high-frequency details, rather than directly modeling a vast set of low-level video tokens using bi-directional attention. SemanticGen adopts a two-stage generation process. In the first stage, a diffusion model generates compact semantic video features, which define the global layout of the video. In the second stage, another diffusion model generates VAE latents conditioned on these semantic features to produce the final output. We observe that generation in the semantic space leads to faster convergence compared to the VAE latent space. Our method is also effective and computationally efficient when extended to long video generation. Extensive experiments demonstrate that SemanticGen produces high-quality videos and outperforms state-of-the-art approaches and strong baselines.
SimpleGVR: A Simple Baseline for Latent-Cascaded Video Super-Resolution
Jun 24, 2025Latent diffusion models have emerged as a leading paradigm for efficient video generation. However, as user expectations shift toward higher-resolution outputs, relying solely on latent computation becomes inadequate. A promising approach involves decoupling the process into two stages: semantic content generation and detail synthesis. The former employs a computationally intensive base model at lower resolutions, while the latter leverages a lightweight cascaded video super-resolution (VSR) model to achieve high-resolution output. In this work, we focus on studying key design principles for latter cascaded VSR models, which are underexplored currently. First, we propose two degradation strategies to generate training pairs that better mimic the output characteristics of the base model, ensuring alignment between the VSR model and its upstream generator. Second, we provide critical insights into VSR model behavior through systematic analysis of (1) timestep sampling strategies, (2) noise augmentation effects on low-resolution (LR) inputs. These findings directly inform our architectural and training innovations. Finally, we introduce interleaving temporal unit and sparse local attention to achieve efficient training and inference, drastically reducing computational overhead. Extensive experiments demonstrate the superiority of our framework over existing methods, with ablation studies confirming the efficacy of each design choice. Our work establishes a simple yet effective baseline for cascaded video super-resolution generation, offering practical insights to guide future advancements in efficient cascaded synthesis systems.
ReCamMaster: Camera-Controlled Generative Rendering from A Single Video
Mar 14, 2025Camera control has been actively studied in text or image conditioned video generation tasks. However, altering camera trajectories of a given video remains under-explored, despite its importance in the field of video creation. It is non-trivial due to the extra constraints of maintaining multiple-frame appearance and dynamic synchronization. To address this, we present ReCamMaster, a camera-controlled generative video re-rendering framework that reproduces the dynamic scene of an input video at novel camera trajectories. The core innovation lies in harnessing the generative capabilities of pre-trained text-to-video models through a simple yet powerful video conditioning mechanism -- its capability often overlooked in current research. To overcome the scarcity of qualified training data, we construct a comprehensive multi-camera synchronized video dataset using Unreal Engine 5, which is carefully curated to follow real-world filming characteristics, covering diverse scenes and camera movements. It helps the model generalize to in-the-wild videos. Lastly, we further improve the robustness to diverse inputs through a meticulously designed training strategy. Extensive experiments tell that our method substantially outperforms existing state-of-the-art approaches and strong baselines. Our method also finds promising applications in video stabilization, super-resolution, and outpainting. Project page: https://jianhongbai.github.io/ReCamMaster/
CodePhys: Robust Video-based Remote Physiological Measurement through Latent Codebook Querying
Feb 11, 2025Remote photoplethysmography (rPPG) aims to measure non-contact physiological signals from facial videos, which has shown great potential in many applications. Most existing methods directly extract video-based rPPG features by designing neural networks for heart rate estimation. Although they can achieve acceptable results, the recovery of rPPG signal faces intractable challenges when interference from real-world scenarios takes place on facial video. Specifically, facial videos are inevitably affected by non-physiological factors (e.g., camera device noise, defocus, and motion blur), leading to the distortion of extracted rPPG signals. Recent rPPG extraction methods are easily affected by interference and degradation, resulting in noisy rPPG signals. In this paper, we propose a novel method named CodePhys, which innovatively treats rPPG measurement as a code query task in a noise-free proxy space (i.e., codebook) constructed by ground-truth PPG signals. We consider noisy rPPG features as queries and generate high-fidelity rPPG features by matching them with noise-free PPG features from the codebook. Our approach also incorporates a spatial-aware encoder network with a spatial attention mechanism to highlight physiologically active areas and uses a distillation loss to reduce the influence of non-periodic visual interference. Experimental results on four benchmark datasets demonstrate that CodePhys outperforms state-of-the-art methods in both intra-dataset and cross-dataset settings.
Improving Video Generation with Human Feedback
Jan 23, 2025



Video generation has achieved significant advances through rectified flow techniques, but issues like unsmooth motion and misalignment between videos and prompts persist. In this work, we develop a systematic pipeline that harnesses human feedback to mitigate these problems and refine the video generation model. Specifically, we begin by constructing a large-scale human preference dataset focused on modern video generation models, incorporating pairwise annotations across multi-dimensions. We then introduce VideoReward, a multi-dimensional video reward model, and examine how annotations and various design choices impact its rewarding efficacy. From a unified reinforcement learning perspective aimed at maximizing reward with KL regularization, we introduce three alignment algorithms for flow-based models by extending those from diffusion models. These include two training-time strategies: direct preference optimization for flow (Flow-DPO) and reward weighted regression for flow (Flow-RWR), and an inference-time technique, Flow-NRG, which applies reward guidance directly to noisy videos. Experimental results indicate that VideoReward significantly outperforms existing reward models, and Flow-DPO demonstrates superior performance compared to both Flow-RWR and standard supervised fine-tuning methods. Additionally, Flow-NRG lets users assign custom weights to multiple objectives during inference, meeting personalized video quality needs. Project page: https://gongyeliu.github.io/videoalign.
SynCamMaster: Synchronizing Multi-Camera Video Generation from Diverse Viewpoints
Dec 10, 2024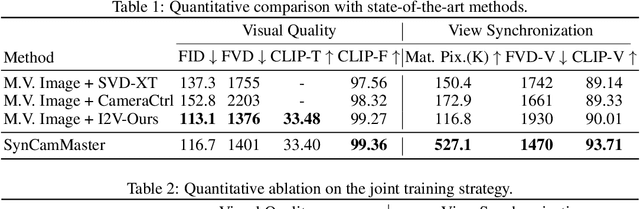
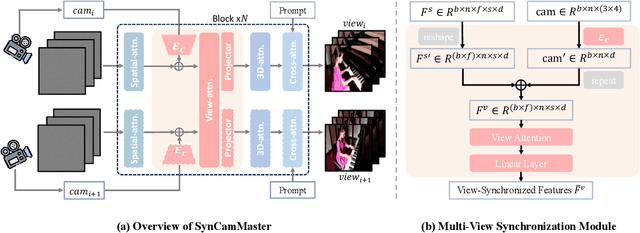
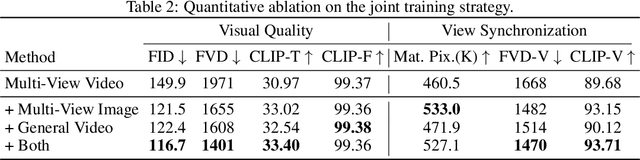
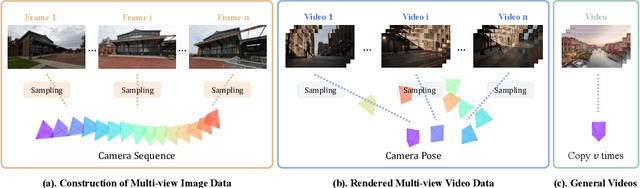
Recent advancements in video diffusion models have shown exceptional abilities in simulating real-world dynamics and maintaining 3D consistency. This progress inspires us to investigate the potential of these models to ensure dynamic consistency across various viewpoints, a highly desirable feature for applications such as virtual filming. Unlike existing methods focused on multi-view generation of single objects for 4D reconstruction, our interest lies in generating open-world videos from arbitrary viewpoints, incorporating 6 DoF camera poses. To achieve this, we propose a plug-and-play module that enhances a pre-trained text-to-video model for multi-camera video generation, ensuring consistent content across different viewpoints. Specifically, we introduce a multi-view synchronization module to maintain appearance and geometry consistency across these viewpoints. Given the scarcity of high-quality training data, we design a hybrid training scheme that leverages multi-camera images and monocular videos to supplement Unreal Engine-rendered multi-camera videos. Furthermore, our method enables intriguing extensions, such as re-rendering a video from novel viewpoints. We also release a multi-view synchronized video dataset, named SynCamVideo-Dataset. Project page: https://jianhongbai.github.io/SynCamMaster/.
3DTrajMaster: Mastering 3D Trajectory for Multi-Entity Motion in Video Generation
Dec 10, 2024



This paper aims to manipulate multi-entity 3D motions in video generation. Previous methods on controllable video generation primarily leverage 2D control signals to manipulate object motions and have achieved remarkable synthesis results. However, 2D control signals are inherently limited in expressing the 3D nature of object motions. To overcome this problem, we introduce 3DTrajMaster, a robust controller that regulates multi-entity dynamics in 3D space, given user-desired 6DoF pose (location and rotation) sequences of entities. At the core of our approach is a plug-and-play 3D-motion grounded object injector that fuses multiple input entities with their respective 3D trajectories through a gated self-attention mechanism. In addition, we exploit an injector architecture to preserve the video diffusion prior, which is crucial for generalization ability. To mitigate video quality degradation, we introduce a domain adaptor during training and employ an annealed sampling strategy during inference. To address the lack of suitable training data, we construct a 360-Motion Dataset, which first correlates collected 3D human and animal assets with GPT-generated trajectory and then captures their motion with 12 evenly-surround cameras on diverse 3D UE platforms. Extensive experiments show that 3DTrajMaster sets a new state-of-the-art in both accuracy and generalization for controlling multi-entity 3D motions. Project page: http://fuxiao0719.github.io/projects/3dtrajmaster
Noise Calibration: Plug-and-play Content-Preserving Video Enhancement using Pre-trained Video Diffusion Models
Jul 14, 2024



In order to improve the quality of synthesized videos, currently, one predominant method involves retraining an expert diffusion model and then implementing a noising-denoising process for refinement. Despite the significant training costs, maintaining consistency of content between the original and enhanced videos remains a major challenge. To tackle this challenge, we propose a novel formulation that considers both visual quality and consistency of content. Consistency of content is ensured by a proposed loss function that maintains the structure of the input, while visual quality is improved by utilizing the denoising process of pretrained diffusion models. To address the formulated optimization problem, we have developed a plug-and-play noise optimization strategy, referred to as Noise Calibration. By refining the initial random noise through a few iterations, the content of original video can be largely preserved, and the enhancement effect demonstrates a notable improvement. Extensive experiments have demonstrated the effectiveness of the proposed method.