 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFasterPose: A Faster Simple Baseline for Human Pose Estimation
Jul 07, 2021
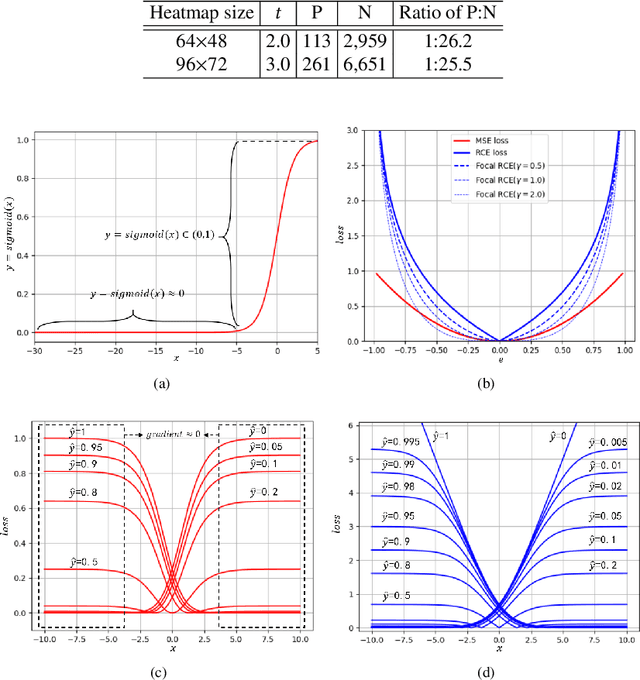
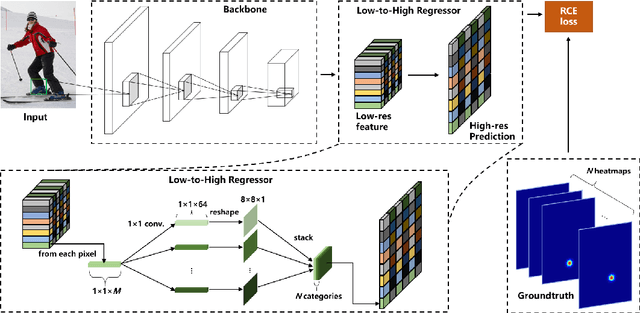
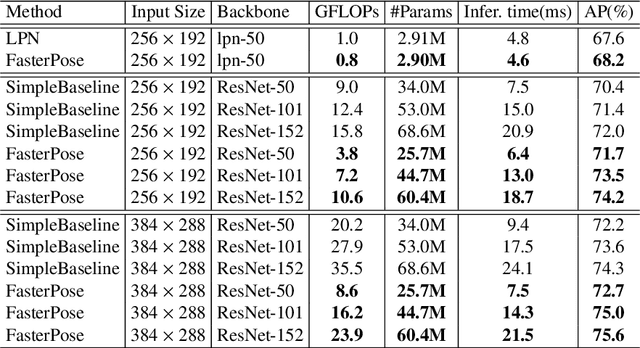
The performance of human pose estimation depends on the spatial accuracy of keypoint localization. Most existing methods pursue the spatial accuracy through learning the high-resolution (HR) representation from input images. By the experimental analysis, we find that the HR representation leads to a sharp increase of computational cost, while the accuracy improvement remains marginal compared with the low-resolution (LR) representation. In this paper, we propose a design paradigm for cost-effective network with LR representation for efficient pose estimation, named FasterPose. Whereas the LR design largely shrinks the model complexity, yet how to effectively train the network with respect to the spatial accuracy is a concomitant challenge. We study the training behavior of FasterPose, and formulate a novel regressive cross-entropy (RCE) loss function for accelerating the convergence and promoting the accuracy. The RCE loss generalizes the ordinary cross-entropy loss from the binary supervision to a continuous range, thus the training of pose estimation network is able to benefit from the sigmoid function. By doing so, the output heatmap can be inferred from the LR features without loss of spatial accuracy, while the computational cost and model size has been significantly reduced. Compared with the previously dominant network of pose estimation, our method reduces 58% of the FLOPs and simultaneously gains 1.3% improvement of accuracy. Extensive experiments show that FasterPose yields promising results on the common benchmarks, i.e., COCO and MPII, consistently validating the effectiveness and efficiency for practical utilization, especially the low-latency and low-energy-budget applications in the non-GPU scenarios.
Recent Advances in Monocular 2D and 3D Human Pose Estimation: A Deep Learning Perspective
Apr 23, 2021
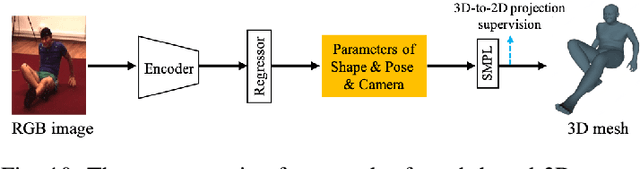

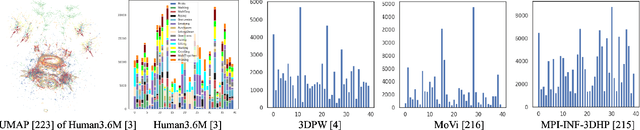
Estimation of the human pose from a monocular camera has been an emerging research topic in the computer vision community with many applications. Recently, benefited from the deep learning technologies, a significant amount of research efforts have greatly advanced the monocular human pose estimation both in 2D and 3D areas. Although there have been some works to summarize the different approaches, it still remains challenging for researchers to have an in-depth view of how these approaches work. In this paper, we provide a comprehensive and holistic 2D-to-3D perspective to tackle this problem. We categorize the mainstream and milestone approaches since the year 2014 under unified frameworks. By systematically summarizing the differences and connections between these approaches, we further analyze the solutions for challenging cases, such as the lack of data, the inherent ambiguity between 2D and 3D, and the complex multi-person scenarios. We also summarize the pose representation styles, benchmarks, evaluation metrics, and the quantitative performance of popular approaches. Finally, we discuss the challenges and give deep thinking of promising directions for future research. We believe this survey will provide the readers with a deep and insightful understanding of monocular human pose estimation.
Group-aware Label Transfer for Domain Adaptive Person Re-identification
Mar 23, 2021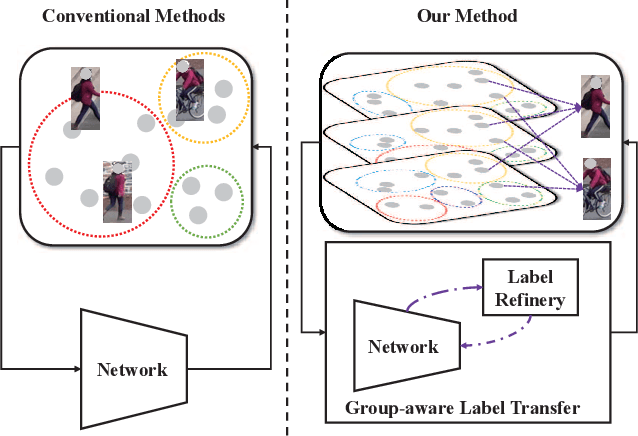
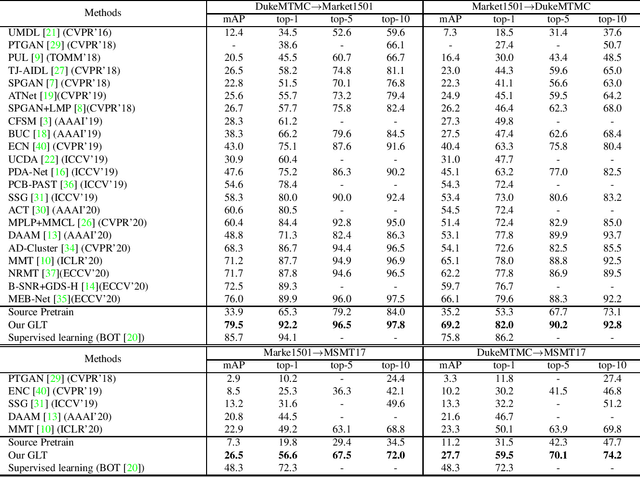
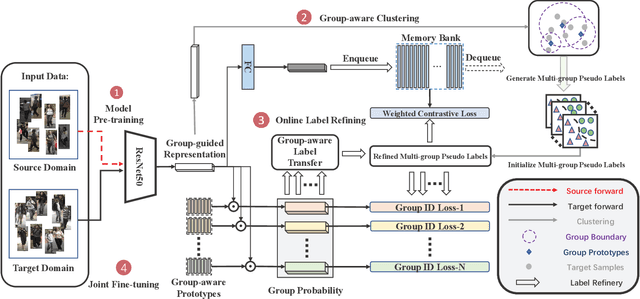
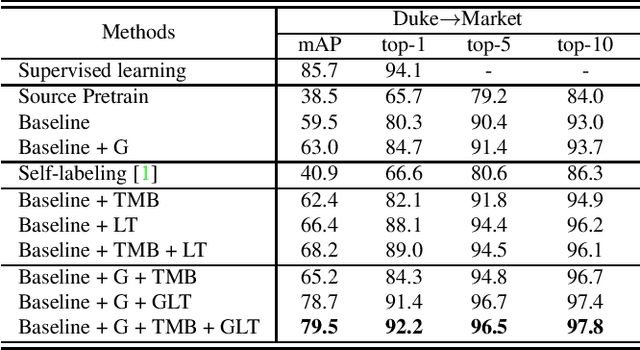
Unsupervised Domain Adaptive (UDA) person re-identification (ReID) aims at adapting the model trained on a labeled source-domain dataset to a target-domain dataset without any further annotations. Most successful UDA-ReID approaches combine clustering-based pseudo-label prediction with representation learning and perform the two steps in an alternating fashion. However, offline interaction between these two steps may allow noisy pseudo labels to substantially hinder the capability of the model. In this paper, we propose a Group-aware Label Transfer (GLT) algorithm, which enables the online interaction and mutual promotion of pseudo-label prediction and representation learning. Specifically, a label transfer algorithm simultaneously uses pseudo labels to train the data while refining the pseudo labels as an online clustering algorithm. It treats the online label refinery problem as an optimal transport problem, which explores the minimum cost for assigning M samples to N pseudo labels. More importantly, we introduce a group-aware strategy to assign implicit attribute group IDs to samples. The combination of the online label refining algorithm and the group-aware strategy can better correct the noisy pseudo label in an online fashion and narrow down the search space of the target identity. The effectiveness of the proposed GLT is demonstrated by the experimental results (Rank-1 accuracy) for Market1501$\to$DukeMTMC (82.0\%) and DukeMTMC$\to$Market1501 (92.2\%), remarkably closing the gap between unsupervised and supervised performance on person re-identification.
AttriMeter: An Attribute-guided Metric Interpreter for Person Re-Identification
Mar 02, 2021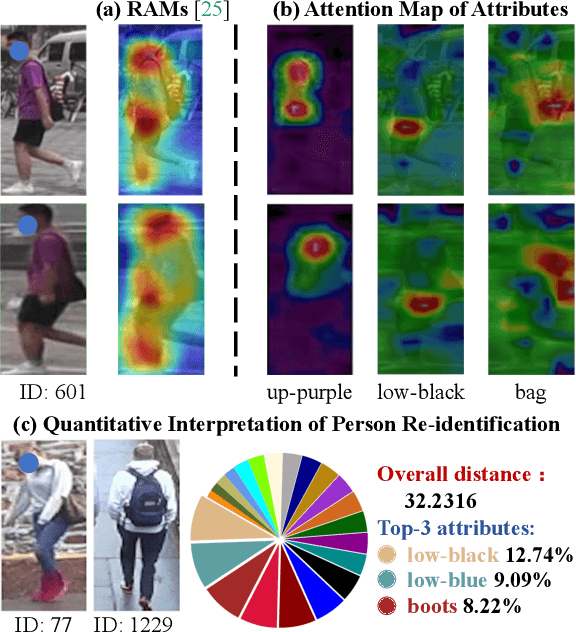

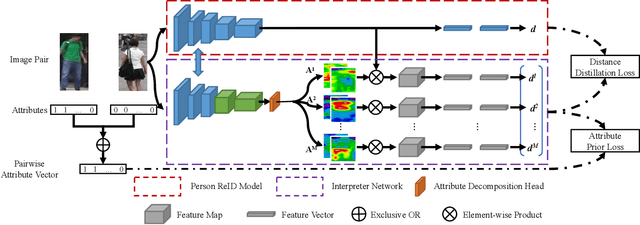
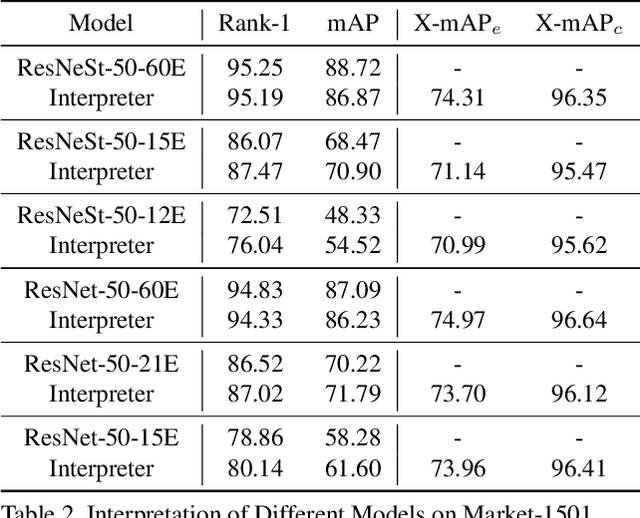
Person Re-identification (ReID) has achieved significant improvement due to the adoption of Convolutional Neural Networks (CNNs). However, person ReID systems only provide a distance or similarity when matching two persons, which makes users hardly understand why they are similar or not. Therefore, we propose an Attribute-guided Metric Interpreter, named AttriMeter, to semantically and quantitatively explain the results of CNN-based ReID models. The AttriMeter has a pluggable structure that can be grafted on arbitrary target models, i.e., the ReID models that need to be interpreted. With an attribute decomposition head, it can learn to generate a group of attribute-guided attention maps (AAMs) from the target model. By applying AAMs to features of two persons from the target model, their distance will be decomposed into a set of attribute-guided components that can measure the contributions of individual attributes. Moreover, we design a distance distillation loss to guarantee the consistency between the results from the target model and the decomposed components from AttriMeter, and an attribute prior loss to eliminate the biases caused by the unbalanced distribution of attributes. Finally, extensive experiments and analysis on a variety of ReID models and datasets show the effectiveness of AttriMeter.
TraND: Transferable Neighborhood Discovery for Unsupervised Cross-domain Gait Recognition
Feb 09, 2021
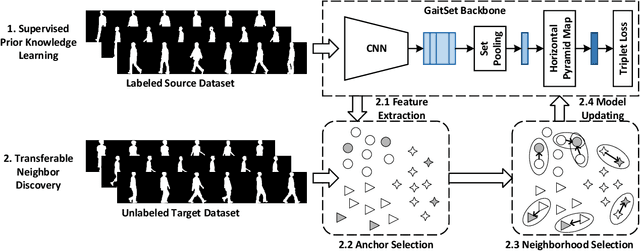
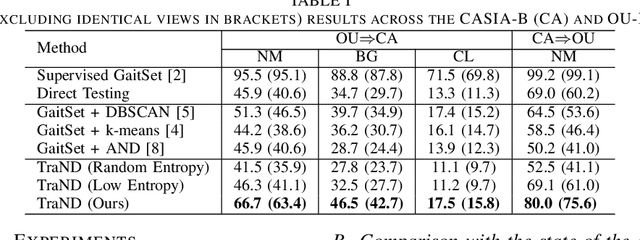
Gait, i.e., the movement pattern of human limbs during locomotion, is a promising biometric for the identification of persons. Despite significant improvement in gait recognition with deep learning, existing studies still neglect a more practical but challenging scenario -- unsupervised cross-domain gait recognition which aims to learn a model on a labeled dataset then adapts it to an unlabeled dataset. Due to the domain shift and class gap, directly applying a model trained on one source dataset to other target datasets usually obtains very poor results. Therefore, this paper proposes a Transferable Neighborhood Discovery (TraND) framework to bridge the domain gap for unsupervised cross-domain gait recognition. To learn effective prior knowledge for gait representation, we first adopt a backbone network pre-trained on the labeled source data in a supervised manner. Then we design an end-to-end trainable approach to automatically discover the confident neighborhoods of unlabeled samples in the latent space. During training, the class consistency indicator is adopted to select confident neighborhoods of samples based on their entropy measurements. Moreover, we explore a high-entropy-first neighbor selection strategy, which can effectively transfer prior knowledge to the target domain. Our method achieves state-of-the-art results on two public datasets, i.e., CASIA-B and OU-LP.
Synthetic Training for Monocular Human Mesh Recovery
Oct 27, 2020
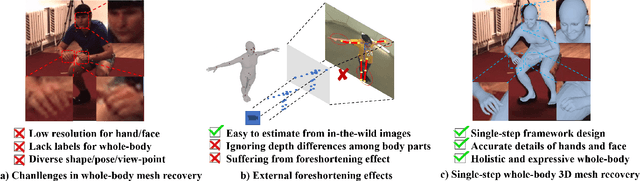
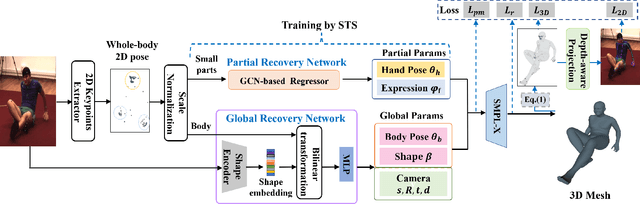
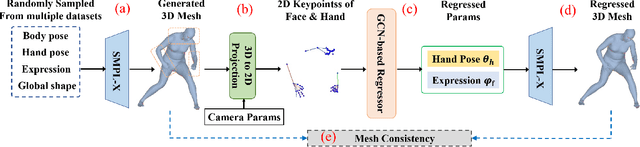
Recovering 3D human mesh from monocular images is a popular topic in computer vision and has a wide range of applications. This paper aims to estimate 3D mesh of multiple body parts (e.g., body, hands) with large-scale differences from a single RGB image. Existing methods are mostly based on iterative optimization, which is very time-consuming. We propose to train a single-shot model to achieve this goal. The main challenge is lacking training data that have complete 3D annotations of all body parts in 2D images. To solve this problem, we design a multi-branch framework to disentangle the regression of different body properties, enabling us to separate each component's training in a synthetic training manner using unpaired data available. Besides, to strengthen the generalization ability, most existing methods have used in-the-wild 2D pose datasets to supervise the estimated 3D pose via 3D-to-2D projection. However, we observe that the commonly used weak-perspective model performs poorly in dealing with the external foreshortening effect of camera projection. Therefore, we propose a depth-to-scale (D2S) projection to incorporate the depth difference into the projection function to derive per-joint scale variants for more proper supervision. The proposed method outperforms previous methods on the CMU Panoptic Studio dataset according to the evaluation results and achieves comparable results on the Human3.6M body and STB hand benchmarks. More impressively, the performance in close shot images gets significantly improved using the proposed D2S projection for weak supervision, while maintains obvious superiority in computational efficiency.
CenterHMR: a Bottom-up Single-shot Method for Multi-person 3D Mesh Recovery from a Single Image
Aug 27, 2020
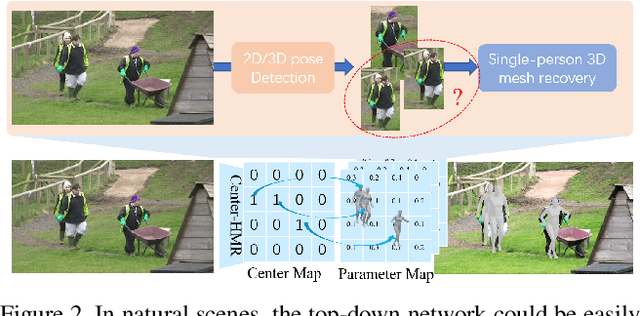
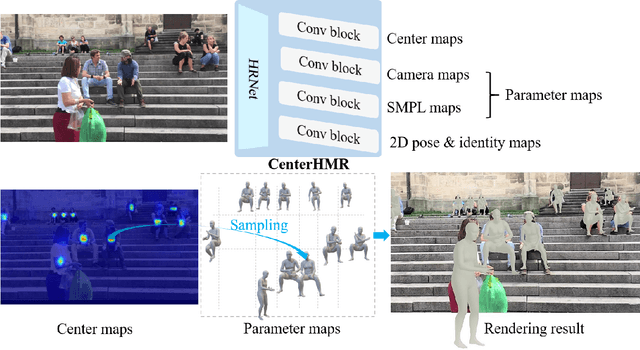

In this paper, we propose a method to recover multi-person 3D mesh from a single image. Existing methods follow a multi-stage detection-based pipeline, where the 3D mesh of each person is regressed from the cropped image patch. They have to suffer from the high complexity of the multi-stage process and the ambiguity of the image-level features. For example, it is hard for them to estimate multi-person 3D mesh from the inseparable crowded cases. Instead, in this paper, we present a novel bottom-up single-shot method, Center-based Human Mesh Recovery network (CenterHMR). The model is trained to simultaneously predict two maps, which represent the location of each human body center and the corresponding parameter vector of 3D human mesh at each center. This explicit center-based representation guarantees the pixel-level feature encoding. Besides, the 3D mesh result of each person is estimated from the features centered at the visible body parts, which improves the robustness under occlusion. CenterHMR surpasses previous methods on multi-person in-the-wild benchmark 3DPW and occlusion dataset 3DOH50K. Besides, CenterHMR has achieved a 2-nd place on ECCV 2020 3DPW Challenge. The code is released on https://github.com/Arthur151/CenterHMR.
Black Re-ID: A Head-shoulder Descriptor for the Challenging Problem of Person Re-Identification
Aug 19, 2020

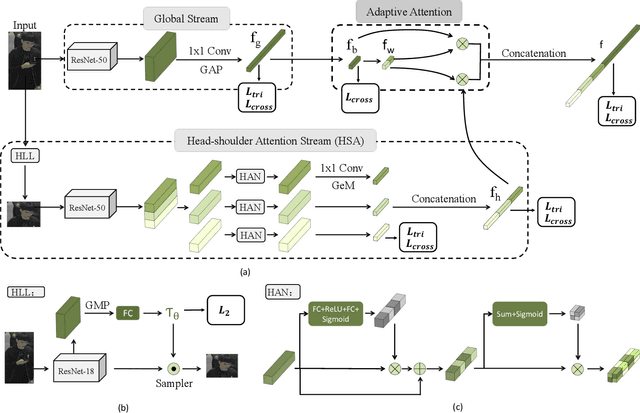
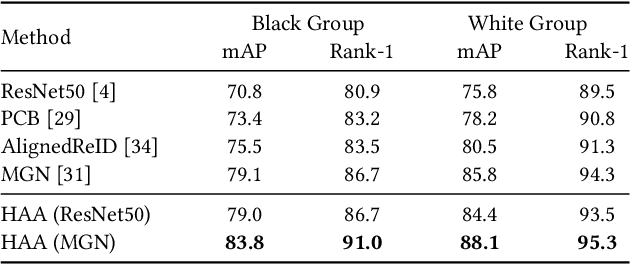
Person re-identification (Re-ID) aims at retrieving an input person image from a set of images captured by multiple cameras. Although recent Re-ID methods have made great success, most of them extract features in terms of the attributes of clothing (e.g., color, texture). However, it is common for people to wear black clothes or be captured by surveillance systems in low light illumination, in which cases the attributes of the clothing are severely missing. We call this problem the Black Re-ID problem. To solve this problem, rather than relying on the clothing information, we propose to exploit head-shoulder features to assist person Re-ID. The head-shoulder adaptive attention network (HAA) is proposed to learn the head-shoulder feature and an innovative ensemble method is designed to enhance the generalization of our model. Given the input person image, the ensemble method would focus on the head-shoulder feature by assigning a larger weight if the individual insides the image is in black clothing. Due to the lack of a suitable benchmark dataset for studying the Black Re-ID problem, we also contribute the first Black-reID dataset, which contains 1274 identities in training set. Extensive evaluations on the Black-reID, Market1501 and DukeMTMC-reID datasets show that our model achieves the best result compared with the state-of-the-art Re-ID methods on both Black and conventional Re-ID problems. Furthermore, our method is also proved to be effective in dealing with person Re-ID in similar clothing. Our code and dataset are avaliable on https://github.com/xbq1994/.
FastReID: A Pytorch Toolbox for General Instance Re-identification
Jun 29, 2020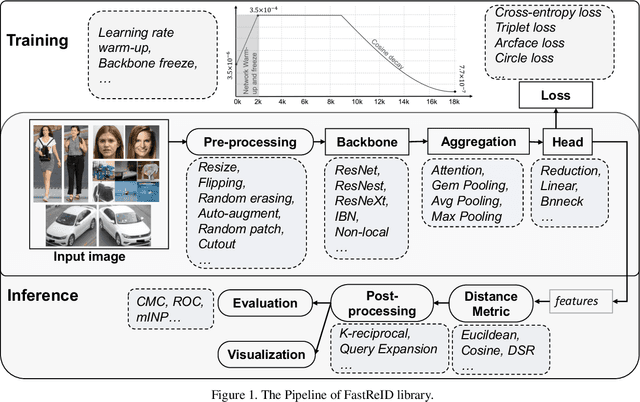
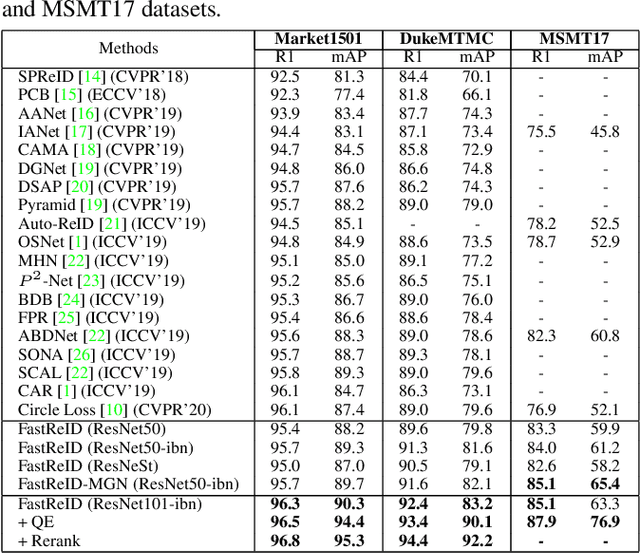

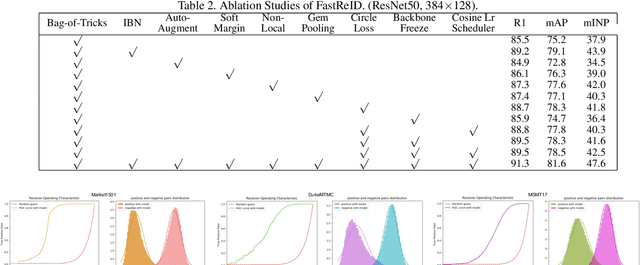
General Instance Re-identification is a very important task in the computer vision, which can be widely used in many practical applications, such as person/vehicle re-identification, face recognition, wildlife protection, commodity tracing, and snapshop, etc.. To meet the increasing application demand for general instance re-identification, we present FastReID as a widely used software system in JD AI Research. In FastReID, highly modular and extensible design makes it easy for the researcher to achieve new research ideas. Friendly manageable system configuration and engineering deployment functions allow practitioners to quickly deploy models into productions. We have implemented some state-of-the-art projects, including person re-id, partial re-id, cross-domain re-id and vehicle re-id, and plan to release these pre-trained models on multiple benchmark datasets. FastReID is by far the most general and high-performance toolbox that supports single and multiple GPU servers, you can reproduce our project results very easily and are very welcome to use it, the code and models are available at https://github.com/JDAI-CV/fast-reid.
A Real-time Action Representation with Temporal Encoding and Deep Compression
Jun 17, 2020
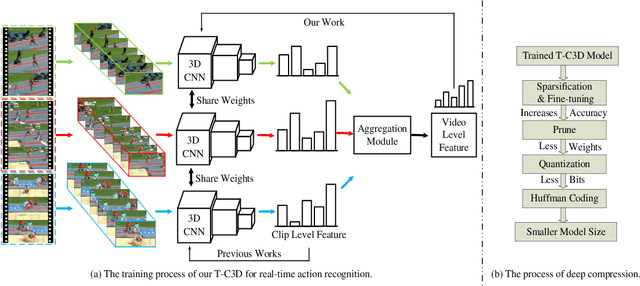
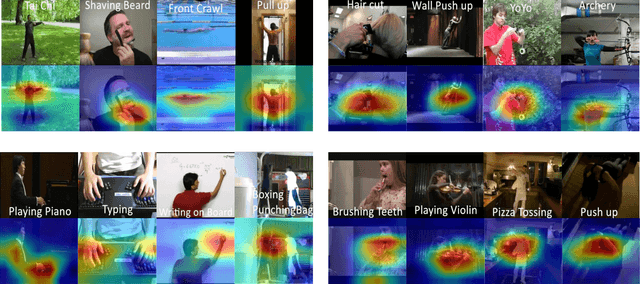
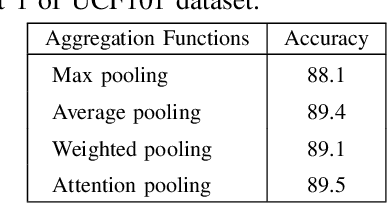
Deep neural networks have achieved remarkable success for video-based action recognition. However, most of existing approaches cannot be deployed in practice due to the high computational cost. To address this challenge, we propose a new real-time convolutional architecture, called Temporal Convolutional 3D Network (T-C3D), for action representation. T-C3D learns video action representations in a hierarchical multi-granularity manner while obtaining a high process speed. Specifically, we propose a residual 3D Convolutional Neural Network (CNN) to capture complementary information on the appearance of a single frame and the motion between consecutive frames. Based on this CNN, we develop a new temporal encoding method to explore the temporal dynamics of the whole video. Furthermore, we integrate deep compression techniques with T-C3D to further accelerate the deployment of models via reducing the size of the model. By these means, heavy calculations can be avoided when doing the inference, which enables the method to deal with videos beyond real-time speed while keeping promising performance. Our method achieves clear improvements on UCF101 action recognition benchmark against state-of-the-art real-time methods by 5.4% in terms of accuracy and 2 times faster in terms of inference speed with a less than 5MB storage model. We validate our approach by studying its action representation performance on four different benchmarks over three different tasks. Extensive experiments demonstrate comparable recognition performance to the state-of-the-art methods. The source code and the pre-trained models are publicly available at https://github.com/tc3d.