 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual Pre-Training Mitigates Forgetting in Language and Vision
May 19, 2022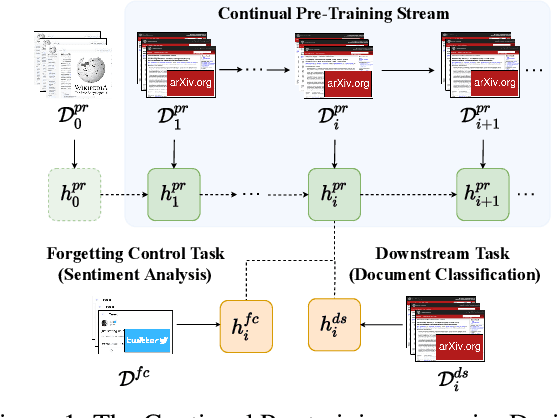
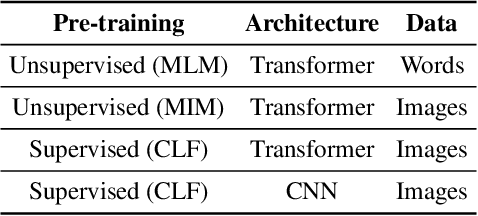
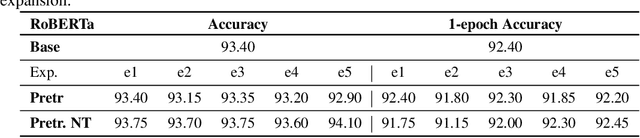
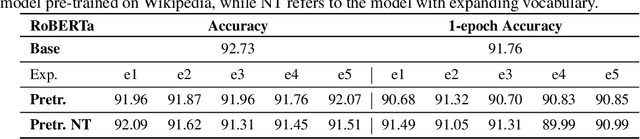
Pre-trained models are nowadays a fundamental component of machine learning research. In continual learning, they are commonly used to initialize the model before training on the stream of non-stationary data. However, pre-training is rarely applied during continual learning. We formalize and investigate the characteristics of the continual pre-training scenario in both language and vision environments, where a model is continually pre-trained on a stream of incoming data and only later fine-tuned to different downstream tasks. We show that continually pre-trained models are robust against catastrophic forgetting and we provide strong empirical evidence supporting the fact that self-supervised pre-training is more effective in retaining previous knowledge than supervised protocols. Code is provided at https://github.com/AndreaCossu/continual-pretraining-nlp-vision .
Generative Negative Replay for Continual Learning
Apr 12, 2022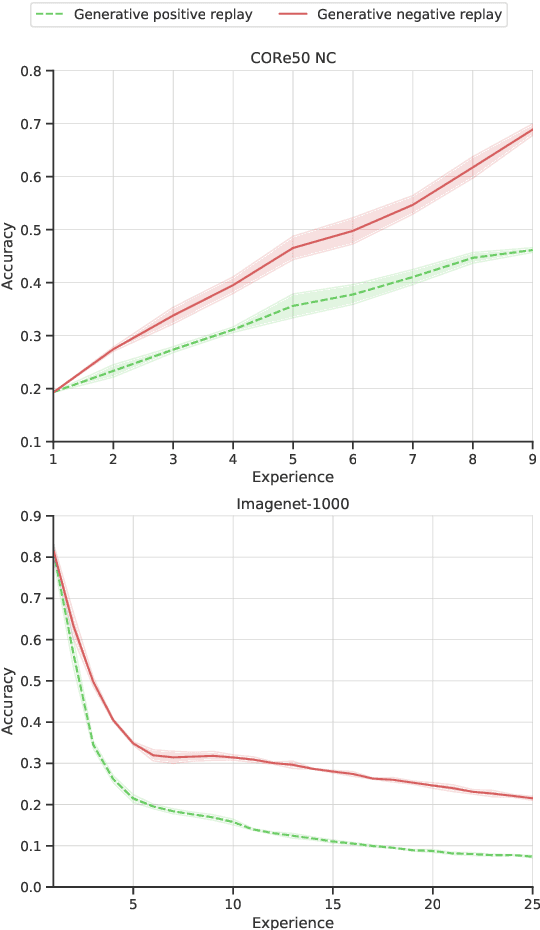
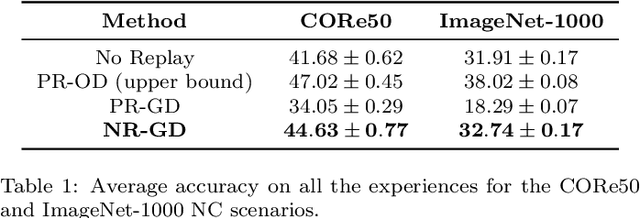

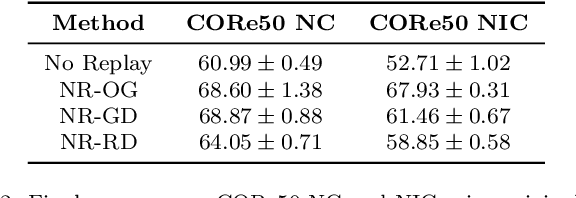
Learning continually is a key aspect of intelligence and a necessary ability to solve many real-life problems. One of the most effective strategies to control catastrophic forgetting, the Achilles' heel of continual learning, is storing part of the old data and replaying them interleaved with new experiences (also known as the replay approach). Generative replay, which is using generative models to provide replay patterns on demand, is particularly intriguing, however, it was shown to be effective mainly under simplified assumptions, such as simple scenarios and low-dimensional data. In this paper, we show that, while the generated data are usually not able to improve the classification accuracy for the old classes, they can be effective as negative examples (or antagonists) to better learn the new classes, especially when the learning experiences are small and contain examples of just one or few classes. The proposed approach is validated on complex class-incremental and data-incremental continual learning scenarios (CORe50 and ImageNet-1000) composed of high-dimensional data and a large number of training experiences: a setup where existing generative replay approaches usually fail.
Avalanche RL: a Continual Reinforcement Learning Library
Mar 24, 2022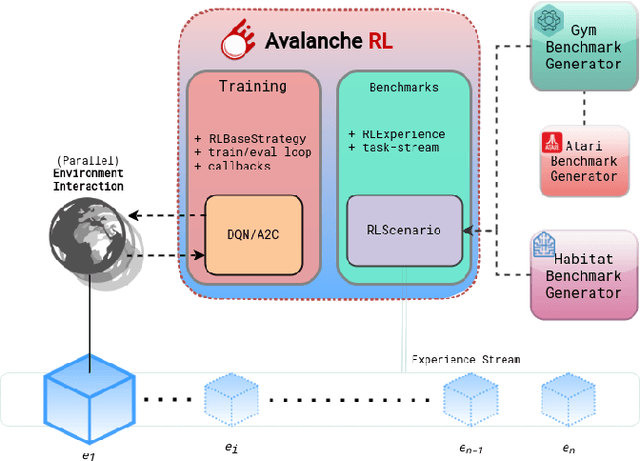

Continual Reinforcement Learning (CRL) is a challenging setting where an agent learns to interact with an environment that is constantly changing over time (the stream of experiences). In this paper, we describe Avalanche RL, a library for Continual Reinforcement Learning which allows to easily train agents on a continuous stream of tasks. Avalanche RL is based on PyTorch and supports any OpenAI Gym environment. Its design is based on Avalanche, one of the more popular continual learning libraries, which allow us to reuse a large number of continual learning strategies and improve the interaction between reinforcement learning and continual learning researchers. Additionally, we propose Continual Habitat-Lab, a novel benchmark and a high-level library which enables the usage of the photorealistic simulator Habitat-Sim for CRL research. Overall, Avalanche RL attempts to unify under a common framework continual reinforcement learning applications, which we hope will foster the growth of the field.
Practical Recommendations for Replay-based Continual Learning Methods
Mar 19, 2022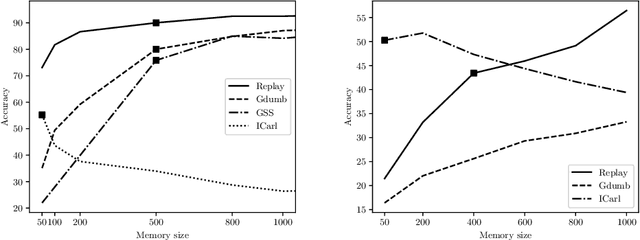
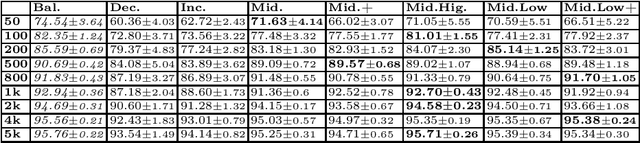
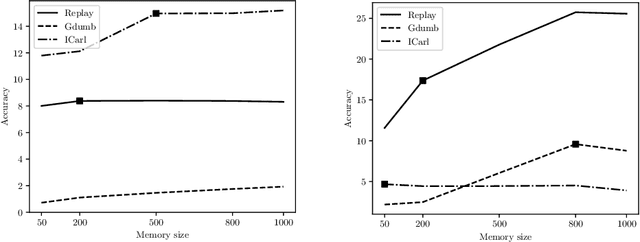

Continual Learning requires the model to learn from a stream of dynamic, non-stationary data without forgetting previous knowledge. Several approaches have been developed in the literature to tackle the Continual Learning challenge. Among them, Replay approaches have empirically proved to be the most effective ones. Replay operates by saving some samples in memory which are then used to rehearse knowledge during training in subsequent tasks. However, an extensive comparison and deeper understanding of different replay implementation subtleties is still missing in the literature. The aim of this work is to compare and analyze existing replay-based strategies and provide practical recommendations on developing efficient, effective and generally applicable replay-based strategies. In particular, we investigate the role of the memory size value, different weighting policies and discuss about the impact of data augmentation, which allows reaching better performance with lower memory sizes.
AI-as-a-Service Toolkit for Human-Centered Intelligence in Autonomous Driving
Feb 09, 2022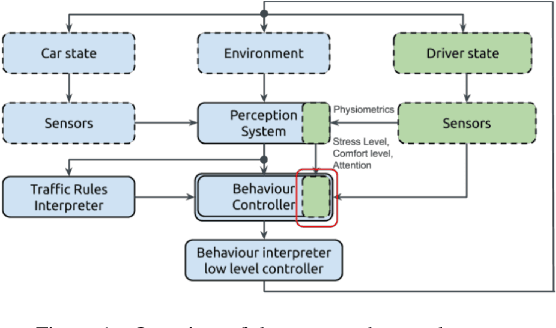
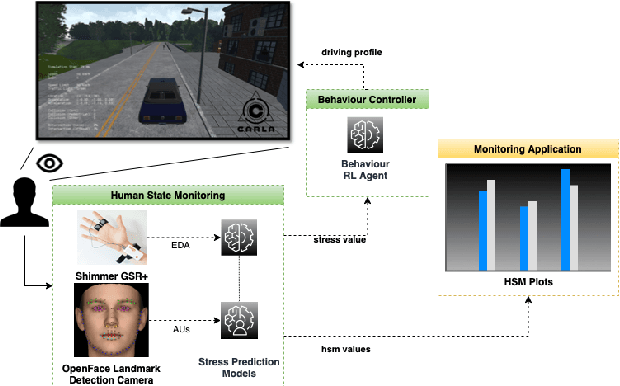
This paper presents a proof-of-concept implementation of the AI-as-a-Service toolkit developed within the H2020 TEACHING project and designed to implement an autonomous driving personalization system according to the output of an automatic driver's stress recognition algorithm, both of them realizing a Cyber-Physical System of Systems. In addition, we implemented a data-gathering subsystem to collect data from different sensors, i.e., wearables and cameras, to automatize stress recognition. The system was attached for testing to a driving simulation software, CARLA, which allows testing the approach's feasibility with minimum cost and without putting at risk drivers and passengers. At the core of the relative subsystems, different learning algorithms were implemented using Deep Neural Networks, Recurrent Neural Networks, and Reinforcement Learning.
Ex-Model: Continual Learning from a Stream of Trained Models
Dec 13, 2021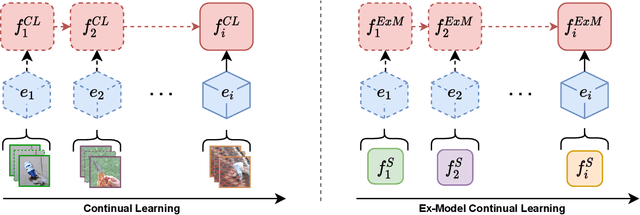
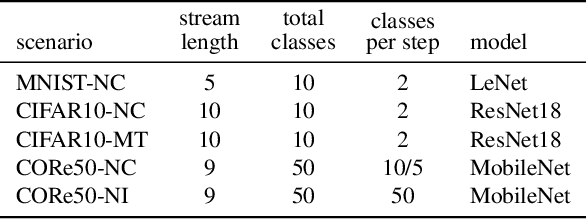
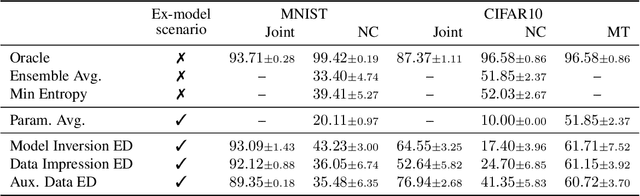

Learning continually from non-stationary data streams is a challenging research topic of growing popularity in the last few years. Being able to learn, adapt, and generalize continually in an efficient, effective, and scalable way is fundamental for a sustainable development of Artificial Intelligent systems. However, an agent-centric view of continual learning requires learning directly from raw data, which limits the interaction between independent agents, the efficiency, and the privacy of current approaches. Instead, we argue that continual learning systems should exploit the availability of compressed information in the form of trained models. In this paper, we introduce and formalize a new paradigm named "Ex-Model Continual Learning" (ExML), where an agent learns from a sequence of previously trained models instead of raw data. We further contribute with three ex-model continual learning algorithms and an empirical setting comprising three datasets (MNIST, CIFAR-10 and CORe50), and eight scenarios, where the proposed algorithms are extensively tested. Finally, we highlight the peculiarities of the ex-model paradigm and we point out interesting future research directions.
Is Class-Incremental Enough for Continual Learning?
Dec 06, 2021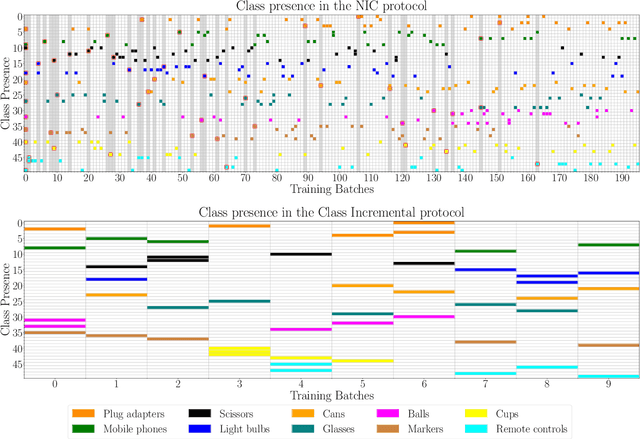
The ability of a model to learn continually can be empirically assessed in different continual learning scenarios. Each scenario defines the constraints and the opportunities of the learning environment. Here, we challenge the current trend in the continual learning literature to experiment mainly on class-incremental scenarios, where classes present in one experience are never revisited. We posit that an excessive focus on this setting may be limiting for future research on continual learning, since class-incremental scenarios artificially exacerbate catastrophic forgetting, at the expense of other important objectives like forward transfer and computational efficiency. In many real-world environments, in fact, repetition of previously encountered concepts occurs naturally and contributes to softening the disruption of previous knowledge. We advocate for a more in-depth study of alternative continual learning scenarios, in which repetition is integrated by design in the stream of incoming information. Starting from already existing proposals, we describe the advantages such class-incremental with repetition scenarios could offer for a more comprehensive assessment of continual learning models.
Sustainable Artificial Intelligence through Continual Learning
Nov 17, 2021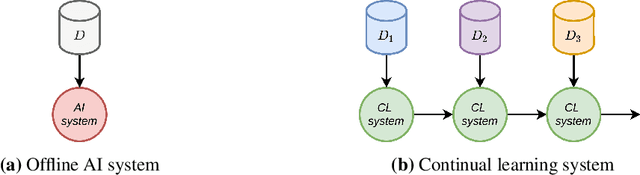
The increasing attention on Artificial Intelligence (AI) regulation has led to the definition of a set of ethical principles grouped into the Sustainable AI framework. In this article, we identify Continual Learning, an active area of AI research, as a promising approach towards the design of systems compliant with the Sustainable AI principles. While Sustainable AI outlines general desiderata for ethical applications, Continual Learning provides means to put such desiderata into practice.
International Workshop on Continual Semi-Supervised Learning: Introduction, Benchmarks and Baselines
Oct 27, 2021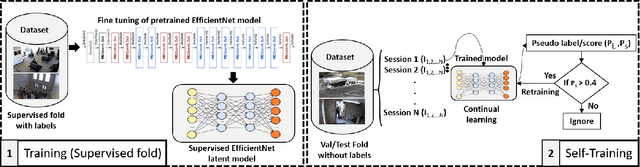


The aim of this paper is to formalize a new continual semi-supervised learning (CSSL) paradigm, proposed to the attention of the machine learning community via the IJCAI 2021 International Workshop on Continual Semi-Supervised Learning (CSSL-IJCAI), with the aim of raising field awareness about this problem and mobilizing its effort in this direction. After a formal definition of continual semi-supervised learning and the appropriate training and testing protocols, the paper introduces two new benchmarks specifically designed to assess CSSL on two important computer vision tasks: activity recognition and crowd counting. We describe the Continual Activity Recognition (CAR) and Continual Crowd Counting (CCC) challenges built upon those benchmarks, the baseline models proposed for the challenges, and describe a simple CSSL baseline which consists in applying batch self-training in temporal sessions, for a limited number of rounds. The results show that learning from unlabelled data streams is extremely challenging, and stimulate the search for methods that can encode the dynamics of the data stream.
TEACHING -- Trustworthy autonomous cyber-physical applications through human-centred intelligence
Jul 14, 2021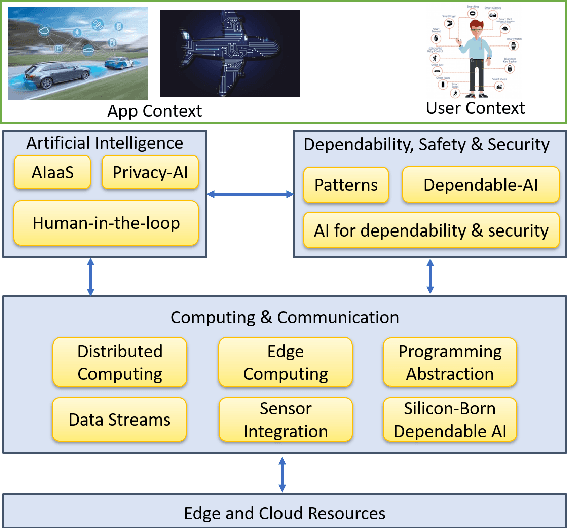
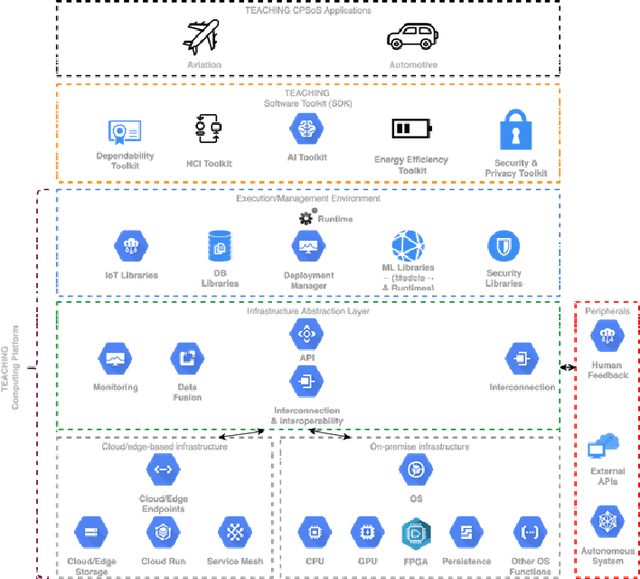
This paper discusses the perspective of the H2020 TEACHING project on the next generation of autonomous applications running in a distributed and highly heterogeneous environment comprising both virtual and physical resources spanning the edge-cloud continuum. TEACHING puts forward a human-centred vision leveraging the physiological, emotional, and cognitive state of the users as a driver for the adaptation and optimization of the autonomous applications. It does so by building a distributed, embedded and federated learning system complemented by methods and tools to enforce its dependability, security and privacy preservation. The paper discusses the main concepts of the TEACHING approach and singles out the main AI-related research challenges associated with it. Further, we provide a discussion of the design choices for the TEACHING system to tackle the aforementioned challenges