 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSSLR: A Semi-Supervised Learning Method for Isolated Sign Language Recognition
Apr 23, 2025Sign language is the primary communication language for people with disabling hearing loss. Sign language recognition (SLR) systems aim to recognize sign gestures and translate them into spoken language. One of the main challenges in SLR is the scarcity of annotated datasets. To address this issue, we propose a semi-supervised learning (SSL) approach for SLR (SSLR), employing a pseudo-label method to annotate unlabeled samples. The sign gestures are represented using pose information that encodes the signer's skeletal joint points. This information is used as input for the Transformer backbone model utilized in the proposed approach. To demonstrate the learning capabilities of SSL across various labeled data sizes, several experiments were conducted using different percentages of labeled data with varying numbers of classes. The performance of the SSL approach was compared with a fully supervised learning-based model on the WLASL-100 dataset. The obtained results of the SSL model outperformed the supervised learning-based model with less labeled data in many cases.
BigDocs: An Open and Permissively-Licensed Dataset for Training Multimodal Models on Document and Code Tasks
Dec 05, 2024



Multimodal AI has the potential to significantly enhance document-understanding tasks, such as processing receipts, understanding workflows, extracting data from documents, and summarizing reports. Code generation tasks that require long-structured outputs can also be enhanced by multimodality. Despite this, their use in commercial applications is often limited due to limited access to training data and restrictive licensing, which hinders open access. To address these limitations, we introduce BigDocs-7.5M, a high-quality, open-access dataset comprising 7.5 million multimodal documents across 30 tasks. We use an efficient data curation process to ensure our data is high-quality and license-permissive. Our process emphasizes accountability, responsibility, and transparency through filtering rules, traceable metadata, and careful content analysis. Additionally, we introduce BigDocs-Bench, a benchmark suite with 10 novel tasks where we create datasets that reflect real-world use cases involving reasoning over Graphical User Interfaces (GUI) and code generation from images. Our experiments show that training with BigDocs-Bench improves average performance up to 25.8% over closed-source GPT-4o in document reasoning and structured output tasks such as Screenshot2HTML or Image2Latex generation. Finally, human evaluations showed a preference for outputs from models trained on BigDocs over GPT-4o. This suggests that BigDocs can help both academics and the open-source community utilize and improve AI tools to enhance multimodal capabilities and document reasoning. The project is hosted at https://bigdocs.github.io .
Fast Convergence of Softmax Policy Mirror Ascent
Nov 18, 2024Natural policy gradient (NPG) is a common policy optimization algorithm and can be viewed as mirror ascent in the space of probabilities. Recently, Vaswani et al. [2021] introduced a policy gradient method that corresponds to mirror ascent in the dual space of logits. We refine this algorithm, removing its need for a normalization across actions and analyze the resulting method (referred to as SPMA). For tabular MDPs, we prove that SPMA with a constant step-size matches the linear convergence of NPG and achieves a faster convergence than constant step-size (accelerated) softmax policy gradient. To handle large state-action spaces, we extend SPMA to use a log-linear policy parameterization. Unlike that for NPG, generalizing SPMA to the linear function approximation (FA) setting does not require compatible function approximation. Unlike MDPO, a practical generalization of NPG, SPMA with linear FA only requires solving convex softmax classification problems. We prove that SPMA achieves linear convergence to the neighbourhood of the optimal value function. We extend SPMA to handle non-linear FA and evaluate its empirical performance on the MuJoCo and Atari benchmarks. Our results demonstrate that SPMA consistently achieves similar or better performance compared to MDPO, PPO and TRPO.
IntentGPT: Few-shot Intent Discovery with Large Language Models
Nov 16, 2024



In today's digitally driven world, dialogue systems play a pivotal role in enhancing user interactions, from customer service to virtual assistants. In these dialogues, it is important to identify user's goals automatically to resolve their needs promptly. This has necessitated the integration of models that perform Intent Detection. However, users' intents are diverse and dynamic, making it challenging to maintain a fixed set of predefined intents. As a result, a more practical approach is to develop a model capable of identifying new intents as they emerge. We address the challenge of Intent Discovery, an area that has drawn significant attention in recent research efforts. Existing methods need to train on a substantial amount of data for correctly identifying new intents, demanding significant human effort. To overcome this, we introduce IntentGPT, a novel training-free method that effectively prompts Large Language Models (LLMs) such as GPT-4 to discover new intents with minimal labeled data. IntentGPT comprises an \textit{In-Context Prompt Generator}, which generates informative prompts for In-Context Learning, an \textit{Intent Predictor} for classifying and discovering user intents from utterances, and a \textit{Semantic Few-Shot Sampler} that selects relevant few-shot examples and a set of known intents to be injected into the prompt. Our experiments show that IntentGPT outperforms previous methods that require extensive domain-specific data and fine-tuning, in popular benchmarks, including CLINC and BANKING, among others.
Capture the Flag: Uncovering Data Insights with Large Language Models
Dec 21, 2023The extraction of a small number of relevant insights from vast amounts of data is a crucial component of data-driven decision-making. However, accomplishing this task requires considerable technical skills, domain expertise, and human labor. This study explores the potential of using Large Language Models (LLMs) to automate the discovery of insights in data, leveraging recent advances in reasoning and code generation techniques. We propose a new evaluation methodology based on a "capture the flag" principle, measuring the ability of such models to recognize meaningful and pertinent information (flags) in a dataset. We further propose two proof-of-concept agents, with different inner workings, and compare their ability to capture such flags in a real-world sales dataset. While the work reported here is preliminary, our results are sufficiently interesting to mandate future exploration by the community.
TK-KNN: A Balanced Distance-Based Pseudo Labeling Approach for Semi-Supervised Intent Classification
Oct 17, 2023



The ability to detect intent in dialogue systems has become increasingly important in modern technology. These systems often generate a large amount of unlabeled data, and manually labeling this data requires substantial human effort. Semi-supervised methods attempt to remedy this cost by using a model trained on a few labeled examples and then by assigning pseudo-labels to further a subset of unlabeled examples that has a model prediction confidence higher than a certain threshold. However, one particularly perilous consequence of these methods is the risk of picking an imbalanced set of examples across classes, which could lead to poor labels. In the present work, we describe Top-K K-Nearest Neighbor (TK-KNN), which uses a more robust pseudo-labeling approach based on distance in the embedding space while maintaining a balanced set of pseudo-labeled examples across classes through a ranking-based approach. Experiments on several datasets show that TK-KNN outperforms existing models, particularly when labeled data is scarce on popular datasets such as CLINC150 and Banking77. Code is available at https://github.com/ServiceNow/tk-knn
Automatic Data Augmentation Learning using Bilevel Optimization for Histopathological Images
Jul 21, 2023



Training a deep learning model to classify histopathological images is challenging, because of the color and shape variability of the cells and tissues, and the reduced amount of available data, which does not allow proper learning of those variations. Variations can come from the image acquisition process, for example, due to different cell staining protocols or tissue deformation. To tackle this challenge, Data Augmentation (DA) can be used during training to generate additional samples by applying transformations to existing ones, to help the model become invariant to those color and shape transformations. The problem with DA is that it is not only dataset-specific but it also requires domain knowledge, which is not always available. Without this knowledge, selecting the right transformations can only be done using heuristics or through a computationally demanding search. To address this, we propose an automatic DA learning method. In this method, the DA parameters, i.e. the transformation parameters needed to improve the model training, are considered learnable and are learned automatically using a bilevel optimization approach in a quick and efficient way using truncated backpropagation. We validated the method on six different datasets. Experimental results show that our model can learn color and affine transformations that are more helpful to train an image classifier than predefined DA transformations, which are also more expensive as they need to be selected before the training by grid search on a validation set. We also show that similarly to a model trained with RandAugment, our model has also only a few method-specific hyperparameters to tune but is performing better. This makes our model a good solution for learning the best DA parameters, especially in the context of histopathological images, where defining potentially useful transformation heuristically is not trivial.
FigGen: Text to Scientific Figure Generation
Jun 21, 2023



The generative modeling landscape has experienced tremendous growth in recent years, particularly in generating natural images and art. Recent techniques have shown impressive potential in creating complex visual compositions while delivering impressive realism and quality. However, state-of-the-art methods have been focusing on the narrow domain of natural images, while other distributions remain unexplored. In this paper, we introduce the problem of text-to-figure generation, that is creating scientific figures of papers from text descriptions. We present FigGen, a diffusion-based approach for text-to-figure as well as the main challenges of the proposed task. Code and models are available at https://github.com/joanrod/figure-diffusion
Long-Context Language Decision Transformers and Exponential Tilt for Interactive Text Environments
Feb 10, 2023



Text-based game environments are challenging because agents must deal with long sequences of text, execute compositional actions using text and learn from sparse rewards. We address these challenges by proposing Long-Context Language Decision Transformers (LLDTs), a framework that is based on long transformer language models and decision transformers (DTs). LLDTs extend DTs with 3 components: (1) exponential tilt to guide the agent towards high obtainable goals, (2) novel goal conditioning methods yielding significantly better results than the traditional return-to-go (sum of all future rewards), and (3) a model of future observations. Our ablation results show that predicting future observations improves agent performance. To the best of our knowledge, LLDTs are the first to address offline RL with DTs on these challenging games. Our experiments show that LLDTs achieve the highest scores among many different types of agents on some of the most challenging Jericho games, such as Enchanter.
OCR-VQGAN: Taming Text-within-Image Generation
Oct 19, 2022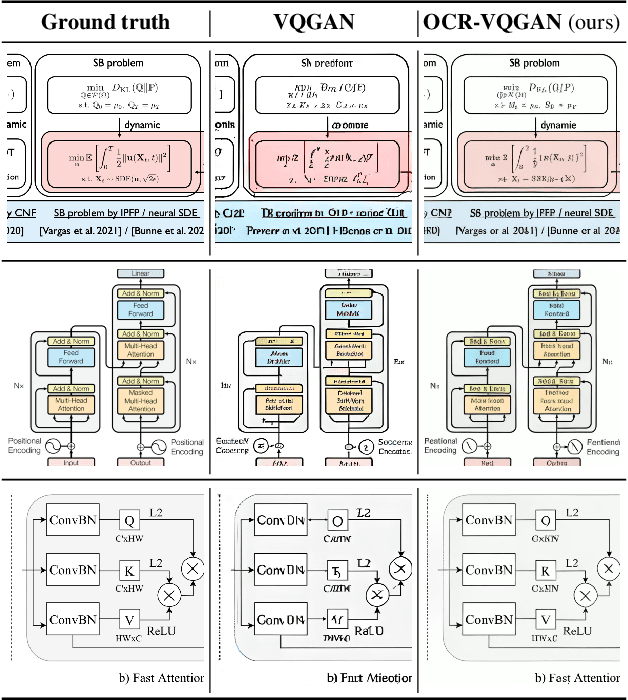
Synthetic image generation has recently experienced significant improvements in domains such as natural image or art generation. However, the problem of figure and diagram generation remains unexplored. A challenging aspect of generating figures and diagrams is effectively rendering readable texts within the images. To alleviate this problem, we present OCR-VQGAN, an image encoder, and decoder that leverages OCR pre-trained features to optimize a text perceptual loss, encouraging the architecture to preserve high-fidelity text and diagram structure. To explore our approach, we introduce the Paper2Fig100k dataset, with over 100k images of figures and texts from research papers. The figures show architecture diagrams and methodologies of articles available at arXiv.org from fields like artificial intelligence and computer vision. Figures usually include text and discrete objects, e.g., boxes in a diagram, with lines and arrows that connect them. We demonstrate the effectiveness of OCR-VQGAN by conducting several experiments on the task of figure reconstruction. Additionally, we explore the qualitative and quantitative impact of weighting different perceptual metrics in the overall loss function. We release code, models, and dataset at https://github.com/joanrod/ocr-vqgan.