 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Confidence-guided Shape Completion for Robotic Applications
Sep 09, 2022
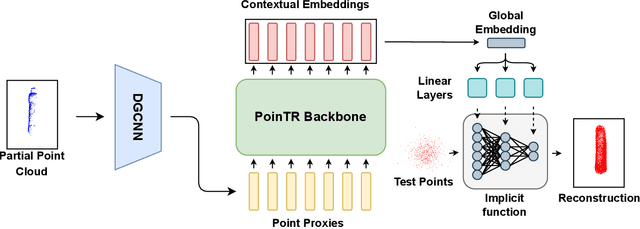


Many robotic tasks involving some form of 3D visual perception greatly benefit from a complete knowledge of the working environment. However, robots often have to tackle unstructured environments and their onboard visual sensors can only provide incomplete information due to limited workspaces, clutter or object self-occlusion. In recent years, deep learning architectures for shape completion have begun taking traction as effective means of inferring a complete 3D object representation from partial visual data. Nevertheless, most of the existing state-of-the-art approaches provide a fixed output resolution in the form of voxel grids, strictly related to the size of the neural network output stage. While this is enough for some tasks, e.g. obstacle avoidance in navigation, grasping and manipulation require finer resolutions and simply scaling up the neural network outputs is computationally expensive. In this paper, we address this limitation by proposing an object shape completion method based on an implicit 3D representation providing a confidence value for each reconstructed point. As a second contribution, we propose a gradient-based method for efficiently sampling such implicit function at an arbitrary resolution, tunable at inference time. We experimentally validate our approach by comparing reconstructed shapes with ground truths, and by deploying our shape completion algorithm in a robotic grasping pipeline. In both cases, we compare results with a state-of-the-art shape completion approach.
One-Shot Open-Set Skeleton-Based Action Recognition
Sep 09, 2022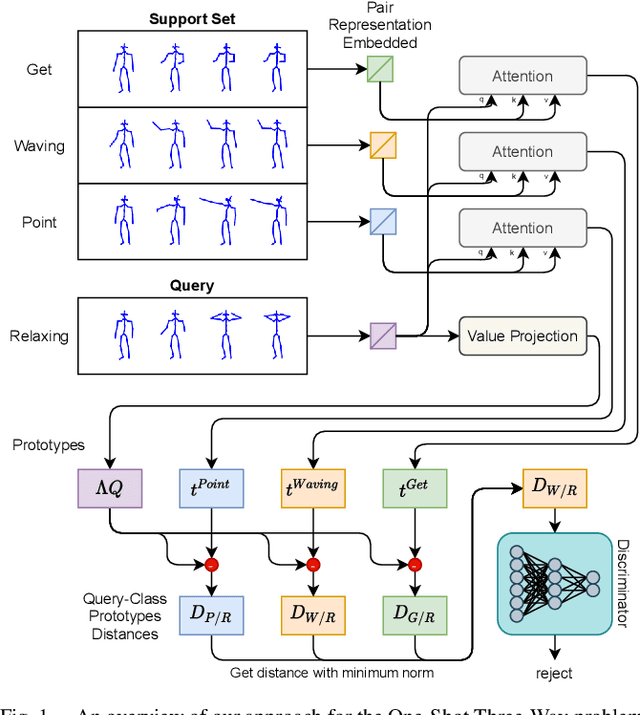
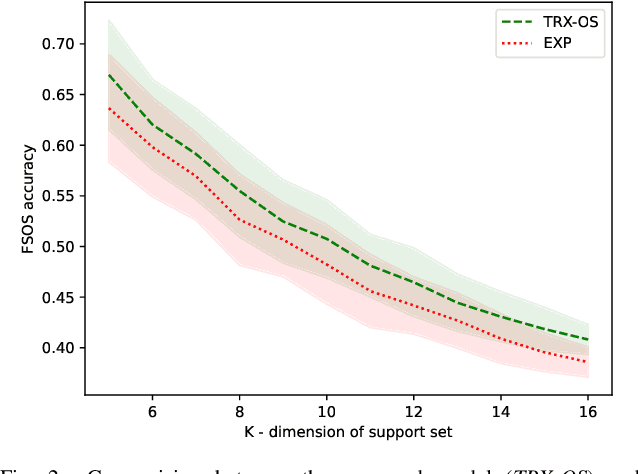
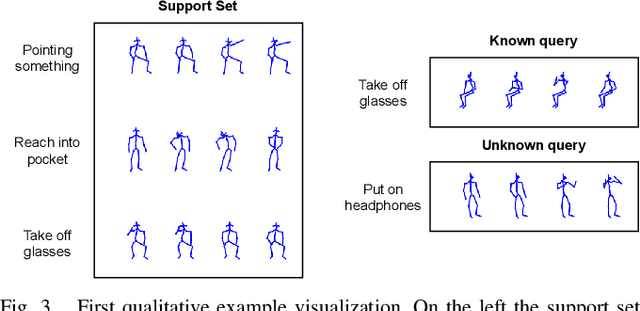
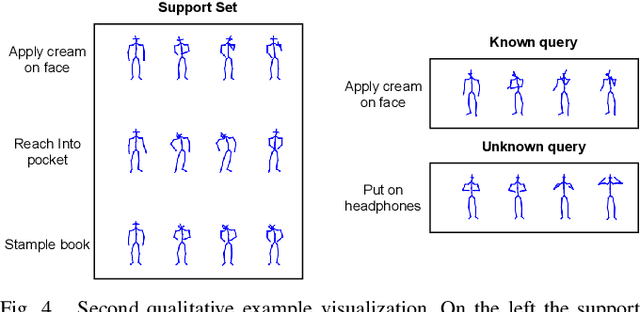
Action recognition is a fundamental capability for humanoid robots to interact and cooperate with humans. This application requires the action recognition system to be designed so that new actions can be easily added, while unknown actions are identified and ignored. In recent years, deep-learning approaches represented the principal solution to the Action Recognition problem. However, most models often require a large dataset of manually-labeled samples. In this work we target One-Shot deep-learning models, because they can deal with just a single instance for class. Unfortunately, One-Shot models assume that, at inference time, the action to recognize falls into the support set and they fail when the action lies outside the support set. Few-Shot Open-Set Recognition (FSOSR) solutions attempt to address that flaw, but current solutions consider only static images and not sequences of images. Static images remain insufficient to discriminate actions such as sitting-down and standing-up. In this paper we propose a novel model that addresses the FSOSR problem with a One-Shot model that is augmented with a discriminator that rejects unknown actions. This model is useful for applications in humanoid robotics, because it allows to easily add new classes and determine whether an input sequence is among the ones that are known to the system. We show how to train the whole model in an end-to-end fashion and we perform quantitative and qualitative analyses. Finally, we provide real-world examples.
Distilled Replay: Overcoming Forgetting through Synthetic Samples
Mar 29, 2021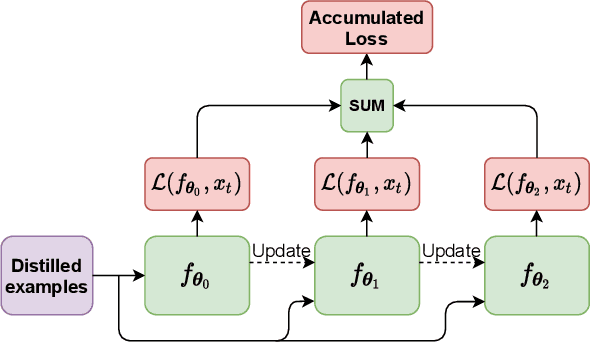

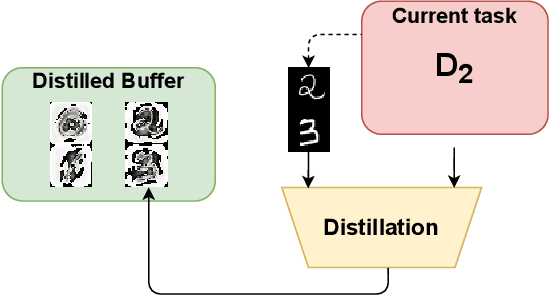
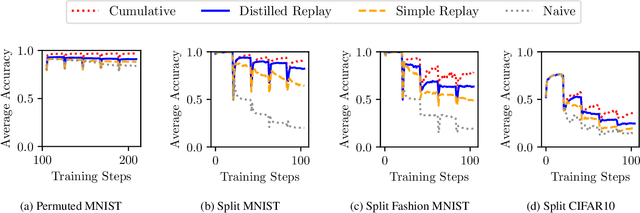
Replay strategies are Continual Learning techniques which mitigate catastrophic forgetting by keeping a buffer of patterns from previous experience, which are interleaved with new data during training. The amount of patterns stored in the buffer is a critical parameter which largely influences the final performance and the memory footprint of the approach. This work introduces Distilled Replay, a novel replay strategy for Continual Learning which is able to mitigate forgetting by keeping a very small buffer (up to $1$ pattern per class) of highly informative samples. Distilled Replay builds the buffer through a distillation process which compresses a large dataset into a tiny set of informative examples. We show the effectiveness of our Distilled Replay against naive replay, which randomly samples patterns from the dataset, on four popular Continual Learning benchmarks.