 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnleashing the Native Recommendation Potential: LLM-Based Generative Recommendation via Structured Term Identifiers
Jan 11, 2026Leveraging the vast open-world knowledge and understanding capabilities of Large Language Models (LLMs) to develop general-purpose, semantically-aware recommender systems has emerged as a pivotal research direction in generative recommendation. However, existing methods face bottlenecks in constructing item identifiers. Text-based methods introduce LLMs' vast output space, leading to hallucination, while methods based on Semantic IDs (SIDs) encounter a semantic gap between SIDs and LLMs' native vocabulary, requiring costly vocabulary expansion and alignment training. To address this, this paper introduces Term IDs (TIDs), defined as a set of semantically rich and standardized textual keywords, to serve as robust item identifiers. We propose GRLM, a novel framework centered on TIDs, employs Context-aware Term Generation to convert item's metadata into standardized TIDs and utilizes Integrative Instruction Fine-tuning to collaboratively optimize term internalization and sequential recommendation. Additionally, Elastic Identifier Grounding is designed for robust item mapping. Extensive experiments on real-world datasets demonstrate that GRLM significantly outperforms baselines across multiple scenarios, pointing a promising direction for generalizable and high-performance generative recommendation systems.
Exploring Recommender System Evaluation: A Multi-Modal User Agent Framework for A/B Testing
Jan 08, 2026In recommender systems, online A/B testing is a crucial method for evaluating the performance of different models. However, conducting online A/B testing often presents significant challenges, including substantial economic costs, user experience degradation, and considerable time requirements. With the Large Language Models' powerful capacity, LLM-based agent shows great potential to replace traditional online A/B testing. Nonetheless, current agents fail to simulate the perception process and interaction patterns, due to the lack of real environments and visual perception capability. To address these challenges, we introduce a multi-modal user agent for A/B testing (A/B Agent). Specifically, we construct a recommendation sandbox environment for A/B testing, enabling multimodal and multi-page interactions that align with real user behavior on online platforms. The designed agent leverages multimodal information perception, fine-grained user preferences, and integrates profiles, action memory retrieval, and a fatigue system to simulate complex human decision-making. We validated the potential of the agent as an alternative to traditional A/B testing from three perspectives: model, data, and features. Furthermore, we found that the data generated by A/B Agent can effectively enhance the capabilities of recommendation models. Our code is publicly available at https://github.com/Applied-Machine-Learning-Lab/ABAgent.
PROMISE: Process Reward Models Unlock Test-Time Scaling Laws in Generative Recommendations
Jan 08, 2026Generative Recommendation has emerged as a promising paradigm, reformulating recommendation as a sequence-to-sequence generation task over hierarchical Semantic IDs. However, existing methods suffer from a critical issue we term Semantic Drift, where errors in early, high-level tokens irreversibly divert the generation trajectory into irrelevant semantic subspaces. Inspired by Process Reward Models (PRMs) that enhance reasoning in Large Language Models, we propose Promise, a novel framework that integrates dense, step-by-step verification into generative models. Promise features a lightweight PRM to assess the quality of intermediate inference steps, coupled with a PRM-guided Beam Search strategy that leverages dense feedback to dynamically prune erroneous branches. Crucially, our approach unlocks Test-Time Scaling Laws for recommender systems: by increasing inference compute, smaller models can match or surpass larger models. Extensive offline experiments and online A/B tests on a large-scale platform demonstrate that Promise effectively mitigates Semantic Drift, significantly improving recommendation accuracy while enabling efficient deployment.
DeepSynth-Eval: Objectively Evaluating Information Consolidation in Deep Survey Writing
Jan 07, 2026The evolution of Large Language Models (LLMs) towards autonomous agents has catalyzed progress in Deep Research. While retrieval capabilities are well-benchmarked, the post-retrieval synthesis stage--where agents must digest massive amounts of context and consolidate fragmented evidence into coherent, long-form reports--remains under-evaluated due to the subjectivity of open-ended writing. To bridge this gap, we introduce DeepSynth-Eval, a benchmark designed to objectively evaluate information consolidation capabilities. We leverage high-quality survey papers as gold standards, reverse-engineering research requests and constructing "Oracle Contexts" from their bibliographies to isolate synthesis from retrieval noise. We propose a fine-grained evaluation protocol using General Checklists (for factual coverage) and Constraint Checklists (for structural organization), transforming subjective judgment into verifiable metrics. Experiments across 96 tasks reveal that synthesizing information from hundreds of references remains a significant challenge. Our results demonstrate that agentic plan-and-write workflows significantly outperform single-turn generation, effectively reducing hallucinations and improving adherence to complex structural constraints.
OpenOneRec Technical Report
Dec 31, 2025While the OneRec series has successfully unified the fragmented recommendation pipeline into an end-to-end generative framework, a significant gap remains between recommendation systems and general intelligence. Constrained by isolated data, they operate as domain specialists-proficient in pattern matching but lacking world knowledge, reasoning capabilities, and instruction following. This limitation is further compounded by the lack of a holistic benchmark to evaluate such integrated capabilities. To address this, our contributions are: 1) RecIF Bench & Open Data: We propose RecIF-Bench, a holistic benchmark covering 8 diverse tasks that thoroughly evaluate capabilities from fundamental prediction to complex reasoning. Concurrently, we release a massive training dataset comprising 96 million interactions from 160,000 users to facilitate reproducible research. 2) Framework & Scaling: To ensure full reproducibility, we open-source our comprehensive training pipeline, encompassing data processing, co-pretraining, and post-training. Leveraging this framework, we demonstrate that recommendation capabilities can scale predictably while mitigating catastrophic forgetting of general knowledge. 3) OneRec-Foundation: We release OneRec Foundation (1.7B and 8B), a family of models establishing new state-of-the-art (SOTA) results across all tasks in RecIF-Bench. Furthermore, when transferred to the Amazon benchmark, our models surpass the strongest baselines with an average 26.8% improvement in Recall@10 across 10 diverse datasets (Figure 1). This work marks a step towards building truly intelligent recommender systems. Nonetheless, realizing this vision presents significant technical and theoretical challenges, highlighting the need for broader research engagement in this promising direction.
No One Left Behind: How to Exploit the Incomplete and Skewed Multi-Label Data for Conversion Rate Prediction
Dec 15, 2025



In most real-world online advertising systems, advertisers typically have diverse customer acquisition goals. A common solution is to use multi-task learning (MTL) to train a unified model on post-click data to estimate the conversion rate (CVR) for these diverse targets. In practice, CVR prediction often encounters missing conversion data as many advertisers submit only a subset of user conversion actions due to privacy or other constraints, making the labels of multi-task data incomplete. If the model is trained on all available samples where advertisers submit user conversion actions, it may struggle when deployed to serve a subset of advertisers targeting specific conversion actions, as the training and deployment data distributions are mismatched. While considerable MTL efforts have been made, a long-standing challenge is how to effectively train a unified model with the incomplete and skewed multi-label data. In this paper, we propose a fine-grained Knowledge transfer framework for Asymmetric Multi-Label data (KAML). We introduce an attribution-driven masking strategy (ADM) to better utilize data with asymmetric multi-label data in training. However, the more relaxed masking in ADM is a double-edged sword: it provides additional training signals but also introduces noise due to skewed data. To address this, we propose a hierarchical knowledge extraction mechanism (HKE) to model the sample discrepancy within the target task tower. Finally, to maximize the utility of unlabeled samples, we incorporate ranking loss strategy to further enhance our model. The effectiveness of KAML has been demonstrated through comprehensive evaluations on offline industry datasets and online A/B tests, which show significant performance improvements over existing MTL baselines.
MGFRec: Towards Reinforced Reasoning Recommendation with Multiple Groundings and Feedback
Oct 27, 2025



The powerful reasoning and generative capabilities of large language models (LLMs) have inspired researchers to apply them to reasoning-based recommendation tasks, which require in-depth reasoning about user interests and the generation of recommended items. However, previous reasoning-based recommendation methods have typically performed inference within the language space alone, without incorporating the actual item space. This has led to over-interpreting user interests and deviating from real items. Towards this research gap, we propose performing multiple rounds of grounding during inference to help the LLM better understand the actual item space, which could ensure that its reasoning remains aligned with real items. Furthermore, we introduce a user agent that provides feedback during each grounding step, enabling the LLM to better recognize and adapt to user interests. Comprehensive experiments conducted on three Amazon review datasets demonstrate the effectiveness of incorporating multiple groundings and feedback. These findings underscore the critical importance of reasoning within the actual item space, rather than being confined to the language space, for recommendation tasks.
OneRec-V2 Technical Report
Aug 28, 2025



Recent breakthroughs in generative AI have transformed recommender systems through end-to-end generation. OneRec reformulates recommendation as an autoregressive generation task, achieving high Model FLOPs Utilization. While OneRec-V1 has shown significant empirical success in real-world deployment, two critical challenges hinder its scalability and performance: (1) inefficient computational allocation where 97.66% of resources are consumed by sequence encoding rather than generation, and (2) limitations in reinforcement learning relying solely on reward models. To address these challenges, we propose OneRec-V2, featuring: (1) Lazy Decoder-Only Architecture: Eliminates encoder bottlenecks, reducing total computation by 94% and training resources by 90%, enabling successful scaling to 8B parameters. (2) Preference Alignment with Real-World User Interactions: Incorporates Duration-Aware Reward Shaping and Adaptive Ratio Clipping to better align with user preferences using real-world feedback. Extensive A/B tests on Kuaishou demonstrate OneRec-V2's effectiveness, improving App Stay Time by 0.467%/0.741% while balancing multi-objective recommendations. This work advances generative recommendation scalability and alignment with real-world feedback, representing a step forward in the development of end-to-end recommender systems.
OneLoc: Geo-Aware Generative Recommender Systems for Local Life Service
Aug 20, 2025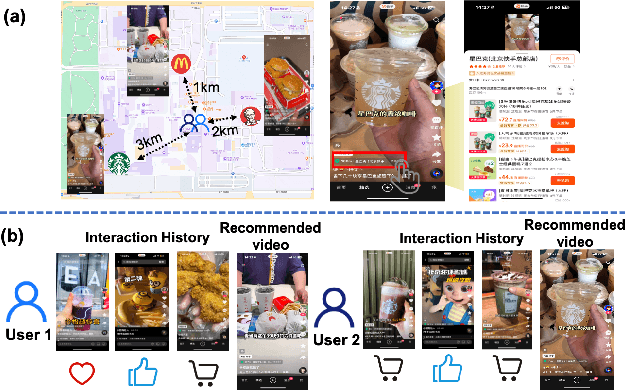
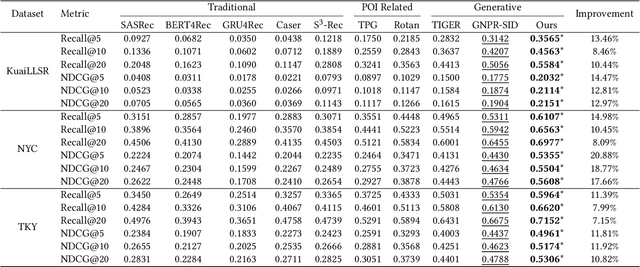
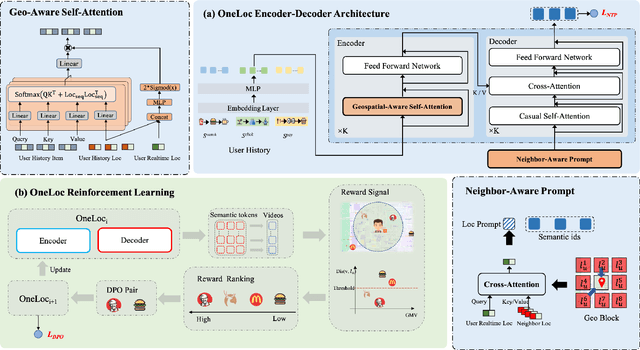

Local life service is a vital scenario in Kuaishou App, where video recommendation is intrinsically linked with store's location information. Thus, recommendation in our scenario is challenging because we should take into account user's interest and real-time location at the same time. In the face of such complex scenarios, end-to-end generative recommendation has emerged as a new paradigm, such as OneRec in the short video scenario, OneSug in the search scenario, and EGA in the advertising scenario. However, in local life service, an end-to-end generative recommendation model has not yet been developed as there are some key challenges to be solved. The first challenge is how to make full use of geographic information. The second challenge is how to balance multiple objectives, including user interests, the distance between user and stores, and some other business objectives. To address the challenges, we propose OneLoc. Specifically, we leverage geographic information from different perspectives: (1) geo-aware semantic ID incorporates both video and geographic information for tokenization, (2) geo-aware self-attention in the encoder leverages both video location similarity and user's real-time location, and (3) neighbor-aware prompt captures rich context information surrounding users for generation. To balance multiple objectives, we use reinforcement learning and propose two reward functions, i.e., geographic reward and GMV reward. With the above design, OneLoc achieves outstanding offline and online performance. In fact, OneLoc has been deployed in local life service of Kuaishou App. It serves 400 million active users daily, achieving 21.016% and 17.891% improvements in terms of gross merchandise value (GMV) and orders numbers.
Generative Representational Learning of Foundation Models for Recommendation
Jun 16, 2025Developing a single foundation model with the capability to excel across diverse tasks has been a long-standing objective in the field of artificial intelligence. As the wave of general-purpose foundation models sweeps across various domains, their influence has significantly extended to the field of recommendation systems. While recent efforts have explored recommendation foundation models for various generative tasks, they often overlook crucial embedding tasks and struggle with the complexities of multi-task learning, including knowledge sharing & conflict resolution, and convergence speed inconsistencies. To address these limitations, we introduce RecFound, a generative representational learning framework for recommendation foundation models. We construct the first comprehensive dataset for recommendation foundation models covering both generative and embedding tasks across diverse scenarios. Based on this dataset, we propose a novel multi-task training scheme featuring a Task-wise Mixture of Low-rank Experts (TMoLE) to handle knowledge sharing & conflict, a Step-wise Convergence-oriented Sample Scheduler (S2Sched) to address inconsistent convergence, and a Model Merge module to balance the performance across tasks. Experiments demonstrate that RecFound achieves state-of-the-art performance across various recommendation tasks, outperforming existing baselines.