 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePremier: Personalized Preference Modulation with Learnable User Embedding in Text-to-Image Generation
Mar 21, 2026Text-to-image generation has advanced rapidly, yet it still struggles to capture the nuanced user preferences. Existing approaches typically rely on multimodal large language models to infer user preferences, but the derived prompts or latent codes rarely reflect them faithfully, leading to suboptimal personalization. We present Premier, a novel preference modulation framework for personalized image generation. Premier represents each user's preference as a learnable embedding and introduces a preference adapter that fuses the user embedding with the text prompt. To enable accurate and fine-grained preference control, the fused preference embedding is further used to modulate the generative process. To enhance the distinctness of individual preference and improve alignment between outputs and user-specific styles, we incorporate a dispersion loss that enforces separation among user embeddings. When user data are scarce, new users are represented as linear combinations of existing preference embeddings learned during training, enabling effective generalization. Experiments show that Premier outperforms prior methods under the same history length, achieving stronger preference alignment and superior performance on text consistency, ViPer proxy metrics, and expert evaluations.
PCEvo: Path-Consistent Molecular Representation via Virtual Evolutionary
Jan 27, 2026Molecular representation learning aims to learn vector embeddings that capture molecular structure and geometry, thereby enabling property prediction and downstream scientific applications. In many AI for science tasks, labeled data are expensive to obtain and therefore limited in availability. Under the few-shot setting, models trained with scarce supervision often learn brittle structure-property relationships, resulting in substantially higher prediction errors and reduced generalization to unseen molecules. To address this limitation, we propose PCEvo, a path-consistent representation method that learns from virtual paths through dynamic structural evolution. PCEvo enumerates multiple chemically feasible edit paths between retrieved similar molecular pairs under topological dependency constraints. It transforms the labels of the two molecules into stepwise supervision along each virtual evolutionary path. It introduces a path-consistency objective that enforces prediction invariance across alternative paths connecting the same two molecules. Comprehensive experiments on the QM9 and MoleculeNet datasets demonstrate that PCEvo substantially improves the few-shot generalization performance of baseline methods. The code is available at https://anonymous.4open.science/r/PCEvo-4BF2.
DeepSynth-Eval: Objectively Evaluating Information Consolidation in Deep Survey Writing
Jan 07, 2026The evolution of Large Language Models (LLMs) towards autonomous agents has catalyzed progress in Deep Research. While retrieval capabilities are well-benchmarked, the post-retrieval synthesis stage--where agents must digest massive amounts of context and consolidate fragmented evidence into coherent, long-form reports--remains under-evaluated due to the subjectivity of open-ended writing. To bridge this gap, we introduce DeepSynth-Eval, a benchmark designed to objectively evaluate information consolidation capabilities. We leverage high-quality survey papers as gold standards, reverse-engineering research requests and constructing "Oracle Contexts" from their bibliographies to isolate synthesis from retrieval noise. We propose a fine-grained evaluation protocol using General Checklists (for factual coverage) and Constraint Checklists (for structural organization), transforming subjective judgment into verifiable metrics. Experiments across 96 tasks reveal that synthesizing information from hundreds of references remains a significant challenge. Our results demonstrate that agentic plan-and-write workflows significantly outperform single-turn generation, effectively reducing hallucinations and improving adherence to complex structural constraints.
Klear-AgentForge: Forging Agentic Intelligence through Posttraining Scaling
Nov 08, 2025



Despite the proliferation of powerful agentic models, the lack of critical post-training details hinders the development of strong counterparts in the open-source community. In this study, we present a comprehensive and fully open-source pipeline for training a high-performance agentic model for interacting with external tools and environments, named Klear-Qwen3-AgentForge, starting from the Qwen3-8B base model. We design effective supervised fine-tuning (SFT) with synthetic data followed by multi-turn reinforcement learning (RL) to unlock the potential for multiple diverse agentic tasks. We perform exclusive experiments on various agentic benchmarks in both tool use and coding domains. Klear-Qwen3-AgentForge-8B achieves state-of-the-art performance among LLMs of similar size and remains competitive with significantly larger models.
Zero-Shot Learning with Subsequence Reordering Pretraining for Compound-Protein Interaction
Jul 28, 2025Given the vastness of chemical space and the ongoing emergence of previously uncharacterized proteins, zero-shot compound-protein interaction (CPI) prediction better reflects the practical challenges and requirements of real-world drug development. Although existing methods perform adequately during certain CPI tasks, they still face the following challenges: (1) Representation learning from local or complete protein sequences often overlooks the complex interdependencies between subsequences, which are essential for predicting spatial structures and binding properties. (2) Dependence on large-scale or scarce multimodal protein datasets demands significant training data and computational resources, limiting scalability and efficiency. To address these challenges, we propose a novel approach that pretrains protein representations for CPI prediction tasks using subsequence reordering, explicitly capturing the dependencies between protein subsequences. Furthermore, we apply length-variable protein augmentation to ensure excellent pretraining performance on small training datasets. To evaluate the model's effectiveness and zero-shot learning ability, we combine it with various baseline methods. The results demonstrate that our approach can improve the baseline model's performance on the CPI task, especially in the challenging zero-shot scenario. Compared to existing pre-training models, our model demonstrates superior performance, particularly in data-scarce scenarios where training samples are limited. Our implementation is available at https://github.com/Hoch-Zhang/PSRP-CPI.
RLEP: Reinforcement Learning with Experience Replay for LLM Reasoning
Jul 10, 2025



Reinforcement learning (RL) for large language models is an energy-intensive endeavor: training can be unstable, and the policy may gradually drift away from its pretrained weights. We present \emph{RLEP}\, -- \,Reinforcement Learning with Experience rePlay\, -- \,a two-phase framework that first collects verified trajectories and then replays them during subsequent training. At every update step, the policy is optimized on mini-batches that blend newly generated rollouts with these replayed successes. By replaying high-quality examples, RLEP steers the model away from fruitless exploration, focuses learning on promising reasoning paths, and delivers both faster convergence and stronger final performance. On the Qwen2.5-Math-7B base model, RLEP reaches baseline peak accuracy with substantially fewer updates and ultimately surpasses it, improving accuracy on AIME-2024 from 38.2% to 39.9%, on AIME-2025 from 19.8% to 22.3%, and on AMC-2023 from 77.0% to 82.2%. Our code, datasets, and checkpoints are publicly available at https://github.com/Kwai-Klear/RLEP to facilitate reproducibility and further research.
Evaluating Multimodal Large Language Models on Video Captioning via Monte Carlo Tree Search
Jun 11, 2025Video captioning can be used to assess the video understanding capabilities of Multimodal Large Language Models (MLLMs). However, existing benchmarks and evaluation protocols suffer from crucial issues, such as inadequate or homogeneous creation of key points, exorbitant cost of data creation, and limited evaluation scopes. To address these issues, we propose an automatic framework, named AutoCaption, which leverages Monte Carlo Tree Search (MCTS) to construct numerous and diverse descriptive sentences (\textit{i.e.}, key points) that thoroughly represent video content in an iterative way. This iterative captioning strategy enables the continuous enhancement of video details such as actions, objects' attributes, environment details, etc. We apply AutoCaption to curate MCTS-VCB, a fine-grained video caption benchmark covering video details, thereby enabling a comprehensive evaluation of MLLMs on the video captioning task. We evaluate more than 20 open- and closed-source MLLMs of varying sizes on MCTS-VCB. Results show that MCTS-VCB can effectively and comprehensively evaluate the video captioning capability, with Gemini-1.5-Pro achieving the highest F1 score of 71.2. Interestingly, we fine-tune InternVL2.5-8B with the AutoCaption-generated data, which helps the model achieve an overall improvement of 25.0% on MCTS-VCB and 16.3% on DREAM-1K, further demonstrating the effectiveness of AutoCaption. The code and data are available at https://github.com/tjunlp-lab/MCTS-VCB.
DynTok: Dynamic Compression of Visual Tokens for Efficient and Effective Video Understanding
Jun 04, 2025Typical video modeling methods, such as LLava, represent videos as sequences of visual tokens, which are then processed by the LLM backbone for effective video understanding. However, this approach leads to a massive number of visual tokens, especially for long videos. A practical solution is to first extract relevant visual information from the large visual context before feeding it into the LLM backbone, thereby reducing computational overhead. In this work, we introduce DynTok, a novel \textbf{Dyn}amic video \textbf{Tok}en compression strategy. DynTok adaptively splits visual tokens into groups and merges them within each group, achieving high compression in regions with low information density while preserving essential content. Our method reduces the number of tokens to 44.4% of the original size while maintaining comparable performance. It further benefits from increasing the number of video frames and achieves 65.3% on Video-MME and 72.5% on MLVU. By applying this simple yet effective compression method, we expose the redundancy in video token representations and offer insights for designing more efficient video modeling techniques.
TUNA: Comprehensive Fine-grained Temporal Understanding Evaluation on Dense Dynamic Videos
May 26, 2025Videos are unique in their integration of temporal elements, including camera, scene, action, and attribute, along with their dynamic relationships over time. However, existing benchmarks for video understanding often treat these properties separately or narrowly focus on specific aspects, overlooking the holistic nature of video content. To address this, we introduce TUNA, a temporal-oriented benchmark for fine-grained understanding on dense dynamic videos, with two complementary tasks: captioning and QA. Our TUNA features diverse video scenarios and dynamics, assisted by interpretable and robust evaluation criteria. We evaluate several leading models on our benchmark, providing fine-grained performance assessments across various dimensions. This evaluation reveals key challenges in video temporal understanding, such as limited action description, inadequate multi-subject understanding, and insensitivity to camera motion, offering valuable insights for improving video understanding models. The data and code are available at https://friedrichor.github.io/projects/TUNA.
Modality Curation: Building Universal Embeddings for Advanced Multimodal Information Retrieval
May 26, 2025
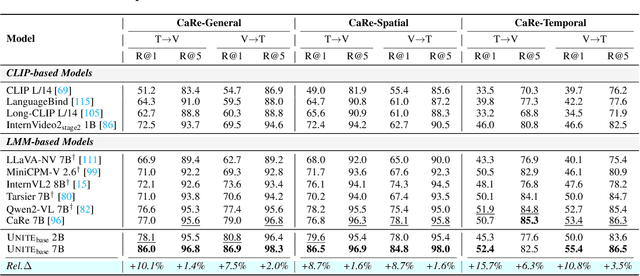

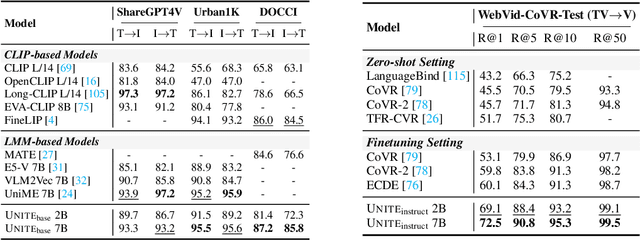
Multimodal information retrieval (MIR) faces inherent challenges due to the heterogeneity of data sources and the complexity of cross-modal alignment. While previous studies have identified modal gaps in feature spaces, a systematic approach to address these challenges remains unexplored. In this work, we introduce UNITE, a universal framework that tackles these challenges through two critical yet underexplored aspects: data curation and modality-aware training configurations. Our work provides the first comprehensive analysis of how modality-specific data properties influence downstream task performance across diverse scenarios. Moreover, we propose Modal-Aware Masked Contrastive Learning (MAMCL) to mitigate the competitive relationships among the instances of different modalities. Our framework achieves state-of-the-art results on multiple multimodal retrieval benchmarks, outperforming existing methods by notable margins. Through extensive experiments, we demonstrate that strategic modality curation and tailored training protocols are pivotal for robust cross-modal representation learning. This work not only advances MIR performance but also provides a foundational blueprint for future research in multimodal systems. Our project is available at https://friedrichor.github.io/projects/UNITE.