 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaxon: Hierarchical Tax Code Prediction with Semantically Aligned LLM Expert Guidance
Jan 13, 2026Tax code prediction is a crucial yet underexplored task in automating invoicing and compliance management for large-scale e-commerce platforms. Each product must be accurately mapped to a node within a multi-level taxonomic hierarchy defined by national standards, where errors lead to financial inconsistencies and regulatory risks. This paper presents Taxon, a semantically aligned and expert-guided framework for hierarchical tax code prediction. Taxon integrates (i) a feature-gating mixture-of-experts architecture that adaptively routes multi-modal features across taxonomy levels, and (ii) a semantic consistency model distilled from large language models acting as domain experts to verify alignment between product titles and official tax definitions. To address noisy supervision in real business records, we design a multi-source training pipeline that combines curated tax databases, invoice validation logs, and merchant registration data to provide both structural and semantic supervision. Extensive experiments on the proprietary TaxCode dataset and public benchmarks demonstrate that Taxon achieves state-of-the-art performance, outperforming strong baselines. Further, an additional full hierarchical paths reconstruction procedure significantly improves structural consistency, yielding the highest overall F1 scores. Taxon has been deployed in production within Alibaba's tax service system, handling an average of over 500,000 tax code queries per day and reaching peak volumes above five million requests during business event with improved accuracy, interpretability, and robustness.
AstroReview: An LLM-driven Multi-Agent Framework for Telescope Proposal Peer Review and Refinement
Dec 31, 2025Competitive access to modern observatories has intensified as proposal volumes outpace available telescope time, making timely, consistent, and transparent peer review a critical bottleneck for the advancement of astronomy. Automating parts of this process is therefore both scientifically significant and operationally necessary to ensure fair allocation and reproducible decisions at scale. We present AstroReview, an open-source, agent-based framework that automates proposal review in three stages: (i) novelty and scientific merit, (ii) feasibility and expected yield, and (iii) meta-review and reliability verification. Task isolation and explicit reasoning traces curb hallucinations and improve transparency. Without any domain specific fine tuning, AstroReview used in our experiments only for the last stage, correctly identifies genuinely accepted proposals with an accuracy of 87%. The AstroReview in Action module replicates the review and refinement loop; with its integrated Proposal Authoring Agent, the acceptance rate of revised drafts increases by 66% after two iterations, showing that iterative feedback combined with automated meta-review and reliability verification delivers measurable quality gains. Together, these results point to a practical path toward scalable, auditable, and higher throughput proposal review for resource limited facilities.
DiverseGRPO: Mitigating Mode Collapse in Image Generation via Diversity-Aware GRPO
Dec 25, 2025



Reinforcement learning (RL), particularly GRPO, improves image generation quality significantly by comparing the relative performance of images generated within the same group. However, in the later stages of training, the model tends to produce homogenized outputs, lacking creativity and visual diversity, which restricts its application scenarios. This issue can be analyzed from both reward modeling and generation dynamics perspectives. First, traditional GRPO relies on single-sample quality as the reward signal, driving the model to converge toward a few high-reward generation modes while neglecting distribution-level diversity. Second, conventional GRPO regularization neglects the dominant role of early-stage denoising in preserving diversity, causing a misaligned regularization budget that limits the achievable quality--diversity trade-off. Motivated by these insights, we revisit the diversity degradation problem from both reward modeling and generation dynamics. At the reward level, we propose a distributional creativity bonus based on semantic grouping. Specifically, we construct a distribution-level representation via spectral clustering over samples generated from the same caption, and adaptively allocate exploratory rewards according to group sizes to encourage the discovery of novel visual modes. At the generation level, we introduce a structure-aware regularization, which enforces stronger early-stage constraints to preserve diversity without compromising reward optimization efficiency. Experiments demonstrate that our method achieves a 13\%--18\% improvement in semantic diversity under matched quality scores, establishing a new Pareto frontier between image quality and diversity for GRPO-based image generation.
Do Reviews Matter for Recommendations in the Era of Large Language Models?
Dec 15, 2025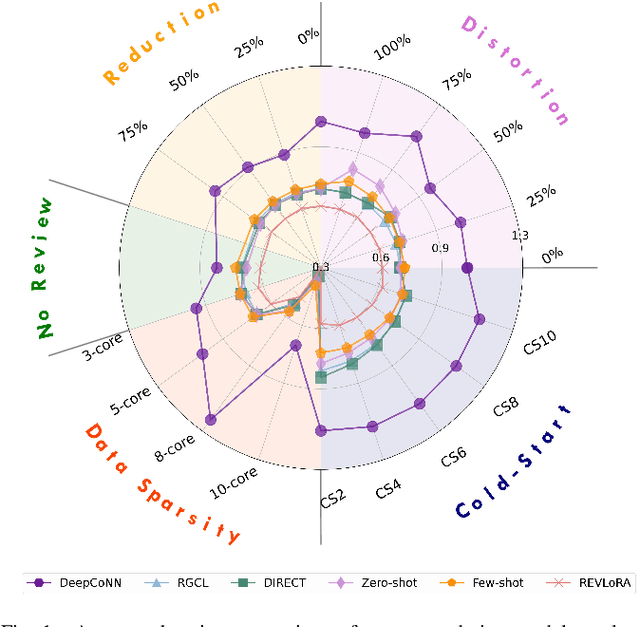
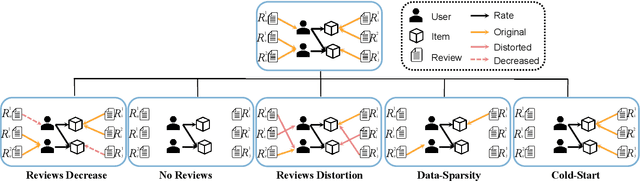
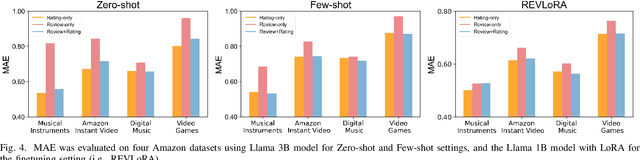
With the advent of large language models (LLMs), the landscape of recommender systems is undergoing a significant transformation. Traditionally, user reviews have served as a critical source of rich, contextual information for enhancing recommendation quality. However, as LLMs demonstrate an unprecedented ability to understand and generate human-like text, this raises the question of whether explicit user reviews remain essential in the era of LLMs. In this paper, we provide a systematic investigation of the evolving role of text reviews in recommendation by comparing deep learning methods and LLM approaches. Particularly, we conduct extensive experiments on eight public datasets with LLMs and evaluate their performance in zero-shot, few-shot, and fine-tuning scenarios. We further introduce a benchmarking evaluation framework for review-aware recommender systems, RAREval, to comprehensively assess the contribution of textual reviews to the recommendation performance of review-aware recommender systems. Our framework examines various scenarios, including the removal of some or all textual reviews, random distortion, as well as recommendation performance in data sparsity and cold-start user settings. Our findings demonstrate that LLMs are capable of functioning as effective review-aware recommendation engines, generally outperforming traditional deep learning approaches, particularly in scenarios characterized by data sparsity and cold-start conditions. In addition, the removal of some or all textual reviews and random distortion does not necessarily lead to declines in recommendation accuracy. These findings motivate a rethinking of how user preference from text reviews can be more effectively leveraged. All code and supplementary materials are available at: https://github.com/zhytk/RAREval-data-processing.
Knowledge Diversion for Efficient Morphology Control and Policy Transfer
Dec 10, 2025Universal morphology control aims to learn a universal policy that generalizes across heterogeneous agent morphologies, with Transformer-based controllers emerging as a popular choice. However, such architectures incur substantial computational costs, resulting in high deployment overhead, and existing methods exhibit limited cross-task generalization, necessitating training from scratch for each new task. To this end, we propose \textbf{DivMorph}, a modular training paradigm that leverages knowledge diversion to learn decomposable controllers. DivMorph factorizes randomly initialized Transformer weights into factor units via SVD prior to training and employs dynamic soft gating to modulate these units based on task and morphology embeddings, separating them into shared \textit{learngenes} and morphology- and task-specific \textit{tailors}, thereby achieving knowledge disentanglement. By selectively activating relevant components, DivMorph enables scalable and efficient policy deployment while supporting effective policy transfer to novel tasks. Extensive experiments demonstrate that DivMorph achieves state-of-the-art performance, achieving a 3$\times$ improvement in sample efficiency over direct finetuning for cross-task transfer and a 17$\times$ reduction in model size for single-agent deployment.
Metric-Fair Prompting: Treating Similar Samples Similarly
Dec 08, 2025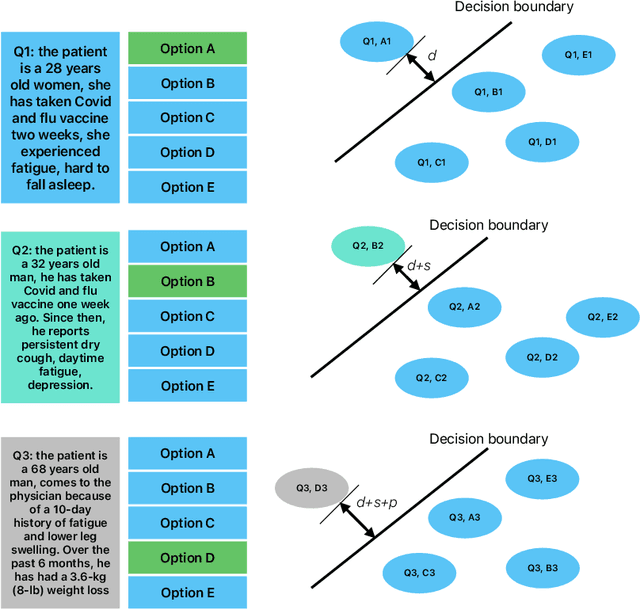


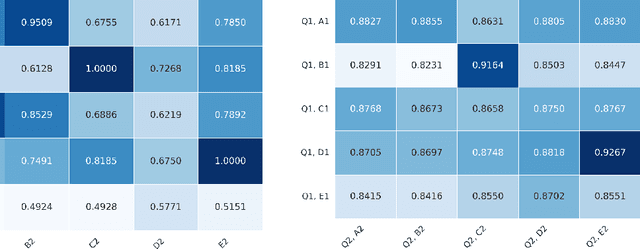
We introduce \emph{Metric-Fair Prompting}, a fairness-aware prompting framework that guides large language models (LLMs) to make decisions under metric-fairness constraints. In the application of multiple-choice medical question answering, each {(question, option)} pair is treated as a binary instance with label $+1$ (correct) or $-1$ (incorrect). To promote {individual fairness}~--~treating similar instances similarly~--~we compute question similarity using NLP embeddings and solve items in \emph{joint pairs of similar questions} rather than in isolation. The prompt enforces a global decision protocol: extract decisive clinical features, map each \((\text{question}, \text{option})\) to a score $f(x)$ that acts as confidence, and impose a Lipschitz-style constraint so that similar inputs receive similar scores and, hence, consistent outputs. Evaluated on the {MedQA (US)} benchmark, Metric-Fair Prompting is shown to improve performance over standard single-item prompting, demonstrating that fairness-guided, confidence-oriented reasoning can enhance LLM accuracy on high-stakes clinical multiple-choice questions.
Training-Free Multi-View Extension of IC-Light for Textual Position-Aware Scene Relighting
Nov 17, 2025We introduce GS-Light, an efficient, textual position-aware pipeline for text-guided relighting of 3D scenes represented via Gaussian Splatting (3DGS). GS-Light implements a training-free extension of a single-input diffusion model to handle multi-view inputs. Given a user prompt that may specify lighting direction, color, intensity, or reference objects, we employ a large vision-language model (LVLM) to parse the prompt into lighting priors. Using off-the-shelf estimators for geometry and semantics (depth, surface normals, and semantic segmentation), we fuse these lighting priors with view-geometry constraints to compute illumination maps and generate initial latent codes for each view. These meticulously derived init latents guide the diffusion model to generate relighting outputs that more accurately reflect user expectations, especially in terms of lighting direction. By feeding multi-view rendered images, along with the init latents, into our multi-view relighting model, we produce high-fidelity, artistically relit images. Finally, we fine-tune the 3DGS scene with the relit appearance to obtain a fully relit 3D scene. We evaluate GS-Light on both indoor and outdoor scenes, comparing it to state-of-the-art baselines including per-view relighting, video relighting, and scene editing methods. Using quantitative metrics (multi-view consistency, imaging quality, aesthetic score, semantic similarity, etc.) and qualitative assessment (user studies), GS-Light demonstrates consistent improvements over baselines. Code and assets will be made available upon publication.
GRPO-Guard: Mitigating Implicit Over-Optimization in Flow Matching via Regulated Clipping
Oct 25, 2025Recently, GRPO-based reinforcement learning has shown remarkable progress in optimizing flow-matching models, effectively improving their alignment with task-specific rewards. Within these frameworks, the policy update relies on importance-ratio clipping to constrain overconfident positive and negative gradients. However, in practice, we observe a systematic shift in the importance-ratio distribution-its mean falls below 1 and its variance differs substantially across timesteps. This left-shifted and inconsistent distribution prevents positive-advantage samples from entering the clipped region, causing the mechanism to fail in constraining overconfident positive updates. As a result, the policy model inevitably enters an implicit over-optimization stage-while the proxy reward continues to increase, essential metrics such as image quality and text-prompt alignment deteriorate sharply, ultimately making the learned policy impractical for real-world use. To address this issue, we introduce GRPO-Guard, a simple yet effective enhancement to existing GRPO frameworks. Our method incorporates ratio normalization, which restores a balanced and step-consistent importance ratio, ensuring that PPO clipping properly constrains harmful updates across denoising timesteps. In addition, a gradient reweighting strategy equalizes policy gradients over noise conditions, preventing excessive updates from particular timestep regions. Together, these designs act as a regulated clipping mechanism, stabilizing optimization and substantially mitigating implicit over-optimization without relying on heavy KL regularization. Extensive experiments on multiple diffusion backbones (e.g., SD3.5M, Flux.1-dev) and diverse proxy tasks demonstrate that GRPO-Guard significantly reduces over-optimization while maintaining or even improving generation quality.
Vicinity-Guided Discriminative Latent Diffusion for Privacy-Preserving Domain Adaptation
Oct 01, 2025Recent work on latent diffusion models (LDMs) has focused almost exclusively on generative tasks, leaving their potential for discriminative transfer largely unexplored. We introduce Discriminative Vicinity Diffusion (DVD), a novel LDM-based framework for a more practical variant of source-free domain adaptation (SFDA): the source provider may share not only a pre-trained classifier but also an auxiliary latent diffusion module, trained once on the source data and never exposing raw source samples. DVD encodes each source feature's label information into its latent vicinity by fitting a Gaussian prior over its k-nearest neighbors and training the diffusion network to drift noisy samples back to label-consistent representations. During adaptation, we sample from each target feature's latent vicinity, apply the frozen diffusion module to generate source-like cues, and use a simple InfoNCE loss to align the target encoder to these cues, explicitly transferring decision boundaries without source access. Across standard SFDA benchmarks, DVD outperforms state-of-the-art methods. We further show that the same latent diffusion module enhances the source classifier's accuracy on in-domain data and boosts performance in supervised classification and domain generalization experiments. DVD thus reinterprets LDMs as practical, privacy-preserving bridges for explicit knowledge transfer, addressing a core challenge in source-free domain adaptation that prior methods have yet to solve.
Towards Understanding Feature Learning in Parameter Transfer
Sep 26, 2025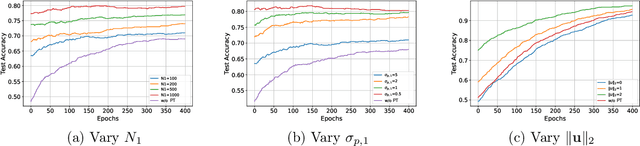
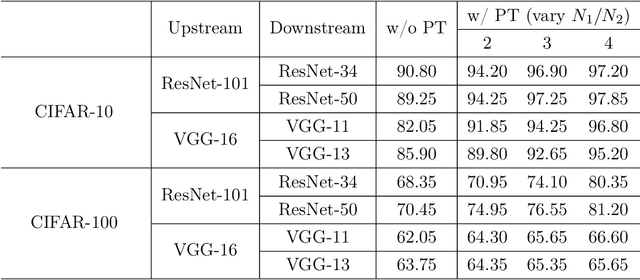
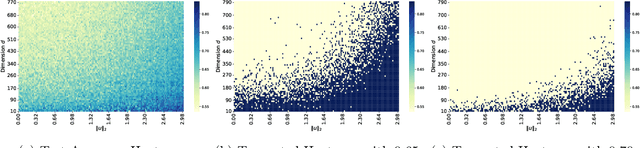
Parameter transfer is a central paradigm in transfer learning, enabling knowledge reuse across tasks and domains by sharing model parameters between upstream and downstream models. However, when only a subset of parameters from the upstream model is transferred to the downstream model, there remains a lack of theoretical understanding of the conditions under which such partial parameter reuse is beneficial and of the factors that govern its effectiveness. To address this gap, we analyze a setting in which both the upstream and downstream models are ReLU convolutional neural networks (CNNs). Within this theoretical framework, we characterize how the inherited parameters act as carriers of universal knowledge and identify key factors that amplify their beneficial impact on the target task. Furthermore, our analysis provides insight into why, in certain cases, transferring parameters can lead to lower test accuracy on the target task than training a new model from scratch. Numerical experiments and real-world data experiments are conducted to empirically validate our theoretical findings.