 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeaver: Foundation Models for Creative Writing
Jan 30, 2024



This work introduces Weaver, our first family of large language models (LLMs) dedicated to content creation. Weaver is pre-trained on a carefully selected corpus that focuses on improving the writing capabilities of large language models. We then fine-tune Weaver for creative and professional writing purposes and align it to the preference of professional writers using a suit of novel methods for instruction data synthesis and LLM alignment, making it able to produce more human-like texts and follow more diverse instructions for content creation. The Weaver family consists of models of Weaver Mini (1.8B), Weaver Base (6B), Weaver Pro (14B), and Weaver Ultra (34B) sizes, suitable for different applications and can be dynamically dispatched by a routing agent according to query complexity to balance response quality and computation cost. Evaluation on a carefully curated benchmark for assessing the writing capabilities of LLMs shows Weaver models of all sizes outperform generalist LLMs several times larger than them. Notably, our most-capable Weaver Ultra model surpasses GPT-4, a state-of-the-art generalist LLM, on various writing scenarios, demonstrating the advantage of training specialized LLMs for writing purposes. Moreover, Weaver natively supports retrieval-augmented generation (RAG) and function calling (tool usage). We present various use cases of these abilities for improving AI-assisted writing systems, including integration of external knowledge bases, tools, or APIs, and providing personalized writing assistance. Furthermore, we discuss and summarize a guideline and best practices for pre-training and fine-tuning domain-specific LLMs.
Full Reference Screen Content Image Quality Assessment by Fusing Multi-level Structure Similarity
Aug 07, 2020
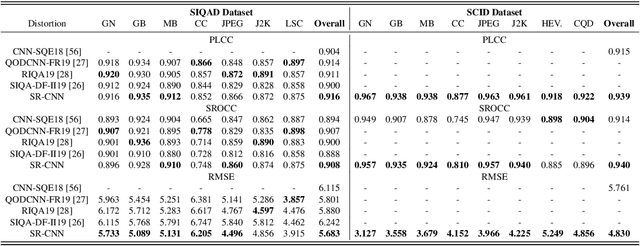
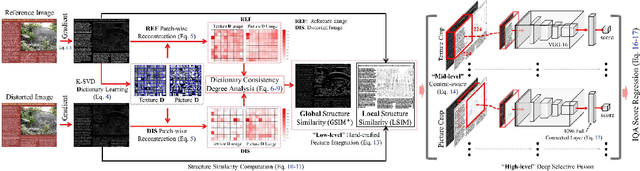
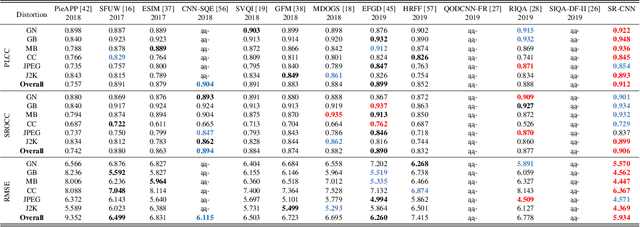
The screen content images (SCIs) usually comprise various content types with sharp edges, in which the artifacts or distortions can be well sensed by the vanilla structure similarity measurement in a full reference manner. Nonetheless, almost all of the current SOTA structure similarity metrics are "locally" formulated in a single-level manner, while the true human visual system (HVS) follows the multi-level manner, and such mismatch could eventually prevent these metrics from achieving trustworthy quality assessment. To ameliorate, this paper advocates a novel solution to measure structure similarity "globally" from the perspective of sparse representation. To perform multi-level quality assessment in accordance with the real HVS, the above-mentioned global metric will be integrated with the conventional local ones by resorting to the newly devised selective deep fusion network. To validate its efficacy and effectiveness, we have compared our method with 12 SOTA methods over two widely-used large-scale public SCI datasets, and the quantitative results indicate that our method yields significantly higher consistency with subjective quality score than the currently leading works. Both the source code and data are also publicly available to gain widespread acceptance and facilitate new advancement and its validation.