 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Serving for Dynamic Agent Workflows with Prediction-based KV-Cache Management
May 07, 2026LLM-based workflows compose specialized agents to execute complex tasks, and these agents usually share substantial context, allowing KV-Cache reuse to save computation. Existing approaches either manage KV-Cache at agent level and fail to exploit the reuse opportunities within workflows, or manage cache at the workflow level but assume that each workflow calls a static sequence of agents. However, practical workflows are typically dynamic, where the sequence of invoked agents and thus induced cache reuse opportunities depend on the context of each task. To serve such dynamic workflows efficiently, we build a system dubbed PBKV (\textbf{P}rediction-\textbf{B}ased \textbf{KV}-Cache Management). For each workflow, PBKV predicts the agent invocations in several future steps by fusing the guidance from historical workflows and context of the target workflow. Based on the predictions, PBKV estimates the reuse potential of cache entries and keeps the high-potential entries in GPU memory. To be robust to prediction errors, PBKV utilizes the predictions conservatively during both cache eviction and prefetching. Experiments on three workflow benchmarks show that PBKV achieves up to $1.85\times$ speedup over LRU on dynamic workflows, and up to $1.26\times$ speedup over the SOTA baseline KVFlow on the static workflow.
Scheduling LLM Inference with Uncertainty-Aware Output Length Predictions
Apr 01, 2026To schedule LLM inference, the \textit{shortest job first} (SJF) principle is favorable by prioritizing requests with short output lengths to avoid head-of-line (HOL) blocking. Existing methods usually predict a single output length for each request to facilitate scheduling. We argue that such a \textit{point estimate} does not match the \textit{stochastic} decoding process of LLM inference, where output length is \textit{uncertain} by nature and determined by when the end-of-sequence (EOS) token is sampled. Hence, the output length of each request should be fitted with a distribution rather than a single value. With an in-depth analysis of empirical data and the stochastic decoding process, we observe that output length follows a heavy-tailed distribution and can be fitted with the log-t distribution. On this basis, we propose a simple metric called Tail Inflated Expectation (TIE) to replace the output length in SJF scheduling, which adjusts the expectation of a log-t distribution with its tail probabilities to account for the risk that a request generates long outputs. To evaluate our TIE scheduler, we compare it with three strong baselines, and the results show that TIE reduces the per-token latency by $2.31\times$ for online inference and improves throughput by $1.42\times$ for offline data generation.
AdaCultureSafe: Adaptive Cultural Safety Grounded by Cultural Knowledge in Large Language Models
Mar 09, 2026With the widespread adoption of Large Language Models (LLMs), respecting indigenous cultures becomes essential for models' culturally safety and responsible global applications. Existing studies separately consider cultural safety and cultural knowledge and neglect that the former should be grounded by the latter. This severely prevents LLMs from yielding culture-specific respectful responses. Consequently, adaptive cultural safety remains a formidable task. In this work, we propose to jointly model cultural safety and knowledge. First and foremost, cultural-safety and knowledge-paired data serve as the key prerequisite to conduct this research. However, the cultural diversity across regions and the subtlety of cultural differences pose significant challenges to the creation of such paired evaluation data. To address this issue, we propose a novel framework that integrates authoritative cultural knowledge descriptions curation, LLM-automated query generation, and heavy manual verification. Accordingly, we obtain a dataset named AdaCultureSafe containing 4.8K manually decomposed fine-grained cultural descriptions and the corresponding 48K manually verified safety- and knowledge-oriented queries. Upon the constructed dataset, we evaluate three families of popular LLMs on their cultural safety and knowledge proficiency, via which we make a critical discovery: no significant correlation exists between their cultural safety and knowledge proficiency. We then delve into the utility-related neuron activations within LLMs to investigate the potential cause of the absence of correlation, which can be attributed to the difference of the objectives of pre-training and post-alignment. We finally present a knowledge-grounded method, which significantly enhances cultural safety by enforcing the integration of knowledge into the LLM response generation process.
Can a Small Model Learn to Look Before It Leaps? Dynamic Learning and Proactive Correction for Hallucination Detection
Nov 08, 2025Hallucination in large language models (LLMs) remains a critical barrier to their safe deployment. Existing tool-augmented hallucination detection methods require pre-defined fixed verification strategies, which are crucial to the quality and effectiveness of tool calls. Some methods directly employ powerful closed-source LLMs such as GPT-4 as detectors, which are effective but too costly. To mitigate the cost issue, some methods adopt the teacher-student architecture and finetune open-source small models as detectors via agent tuning. However, these methods are limited by fixed strategies. When faced with a dynamically changing execution environment, they may lack adaptability and inappropriately call tools, ultimately leading to detection failure. To address the problem of insufficient strategy adaptability, we propose the innovative ``Learning to Evaluate and Adaptively Plan''(LEAP) framework, which endows an efficient student model with the dynamic learning and proactive correction capabilities of the teacher model. Specifically, our method formulates the hallucination detection problem as a dynamic strategy learning problem. We first employ a teacher model to generate trajectories within the dynamic learning loop and dynamically adjust the strategy based on execution failures. We then distill this dynamic planning capability into an efficient student model via agent tuning. Finally, during strategy execution, the student model adopts a proactive correction mechanism, enabling it to propose, review, and optimize its own verification strategies before execution. We demonstrate through experiments on three challenging benchmarks that our LEAP-tuned model outperforms existing state-of-the-art methods.
Privacy-protected Retrieval-Augmented Generation for Knowledge Graph Question Answering
Aug 12, 2025LLMs often suffer from hallucinations and outdated or incomplete knowledge. RAG is proposed to address these issues by integrating external knowledge like that in KGs into LLMs. However, leveraging private KGs in RAG systems poses significant privacy risks due to the black-box nature of LLMs and potential insecure data transmission, especially when using third-party LLM APIs lacking transparency and control. In this paper, we investigate the privacy-protected RAG scenario for the first time, where entities in KGs are anonymous for LLMs, thus preventing them from accessing entity semantics. Due to the loss of semantics of entities, previous RAG systems cannot retrieve question-relevant knowledge from KGs by matching questions with the meaningless identifiers of anonymous entities. To realize an effective RAG system in this scenario, two key challenges must be addressed: (1) How can anonymous entities be converted into retrievable information. (2) How to retrieve question-relevant anonymous entities. Hence, we propose a novel ARoG framework including relation-centric abstraction and structure-oriented abstraction strategies. For challenge (1), the first strategy abstracts entities into high-level concepts by dynamically capturing the semantics of their adjacent relations. It supplements meaningful semantics which can further support the retrieval process. For challenge (2), the second strategy transforms unstructured natural language questions into structured abstract concept paths. These paths can be more effectively aligned with the abstracted concepts in KGs, thereby improving retrieval performance. To guide LLMs to effectively retrieve knowledge from KGs, the two strategies strictly protect privacy from being exposed to LLMs. Experiments on three datasets demonstrate that ARoG achieves strong performance and privacy-robustness.
A Survey on Training-free Alignment of Large Language Models
Aug 12, 2025The alignment of large language models (LLMs) aims to ensure their outputs adhere to human values, ethical standards, and legal norms. Traditional alignment methods often rely on resource-intensive fine-tuning (FT), which may suffer from knowledge degradation and face challenges in scenarios where the model accessibility or computational resources are constrained. In contrast, training-free (TF) alignment techniques--leveraging in-context learning, decoding-time adjustments, and post-generation corrections--offer a promising alternative by enabling alignment without heavily retraining LLMs, making them adaptable to both open-source and closed-source environments. This paper presents the first systematic review of TF alignment methods, categorizing them by stages of pre-decoding, in-decoding, and post-decoding. For each stage, we provide a detailed examination from the viewpoint of LLMs and multimodal LLMs (MLLMs), highlighting their mechanisms and limitations. Furthermore, we identify key challenges and future directions, paving the way for more inclusive and effective TF alignment techniques. By synthesizing and organizing the rapidly growing body of research, this survey offers a guidance for practitioners and advances the development of safer and more reliable LLMs.
MultiTaskDeltaNet: Change Detection-based Image Segmentation for Operando ETEM with Application to Carbon Gasification Kinetics
Jul 22, 2025



Transforming in-situ transmission electron microscopy (TEM) imaging into a tool for spatially-resolved operando characterization of solid-state reactions requires automated, high-precision semantic segmentation of dynamically evolving features. However, traditional deep learning methods for semantic segmentation often encounter limitations due to the scarcity of labeled data, visually ambiguous features of interest, and small-object scenarios. To tackle these challenges, we introduce MultiTaskDeltaNet (MTDN), a novel deep learning architecture that creatively reconceptualizes the segmentation task as a change detection problem. By implementing a unique Siamese network with a U-Net backbone and using paired images to capture feature changes, MTDN effectively utilizes minimal data to produce high-quality segmentations. Furthermore, MTDN utilizes a multi-task learning strategy to leverage correlations between physical features of interest. In an evaluation using data from in-situ environmental TEM (ETEM) videos of filamentous carbon gasification, MTDN demonstrated a significant advantage over conventional segmentation models, particularly in accurately delineating fine structural features. Notably, MTDN achieved a 10.22% performance improvement over conventional segmentation models in predicting small and visually ambiguous physical features. This work bridges several key gaps between deep learning and practical TEM image analysis, advancing automated characterization of nanomaterials in complex experimental settings.
Exploiting Text Semantics for Few and Zero Shot Node Classification on Text-attributed Graph
May 13, 2025



Text-attributed graph (TAG) provides a text description for each graph node, and few- and zero-shot node classification on TAGs have many applications in fields such as academia and social networks. Existing work utilizes various graph-based augmentation techniques to train the node and text embeddings, while text-based augmentations are largely unexplored. In this paper, we propose Text Semantics Augmentation (TSA) to improve accuracy by introducing more text semantic supervision signals. Specifically, we design two augmentation techniques, i.e., positive semantics matching and negative semantics contrast, to provide more reference texts for each graph node or text description. Positive semantic matching retrieves texts with similar embeddings to match with a graph node. Negative semantic contrast adds a negative prompt to construct a text description with the opposite semantics, which is contrasted with the original node and text. We evaluate TSA on 5 datasets and compare with 13 state-of-the-art baselines. The results show that TSA consistently outperforms all baselines, and its accuracy improvements over the best-performing baseline are usually over 5%.
Toxicity Detection towards Adaptability to Changing Perturbations
Dec 17, 2024Toxicity detection is crucial for maintaining the peace of the society. While existing methods perform well on normal toxic contents or those generated by specific perturbation methods, they are vulnerable to evolving perturbation patterns. However, in real-world scenarios, malicious users tend to create new perturbation patterns for fooling the detectors. For example, some users may circumvent the detector of large language models (LLMs) by adding `I am a scientist' at the beginning of the prompt. In this paper, we introduce a novel problem, i.e., continual learning jailbreak perturbation patterns, into the toxicity detection field. To tackle this problem, we first construct a new dataset generated by 9 types of perturbation patterns, 7 of them are summarized from prior work and 2 of them are developed by us. We then systematically validate the vulnerability of current methods on this new perturbation pattern-aware dataset via both the zero-shot and fine tuned cross-pattern detection. Upon this, we present the domain incremental learning paradigm and the corresponding benchmark to ensure the detector's robustness to dynamically emerging types of perturbed toxic text. Our code and dataset are provided in the appendix and will be publicly available at GitHub, by which we wish to offer new research opportunities for the security-relevant communities.
Origin-Destination Demand Prediction: An Urban Radiation and Attraction Perspective
Nov 29, 2024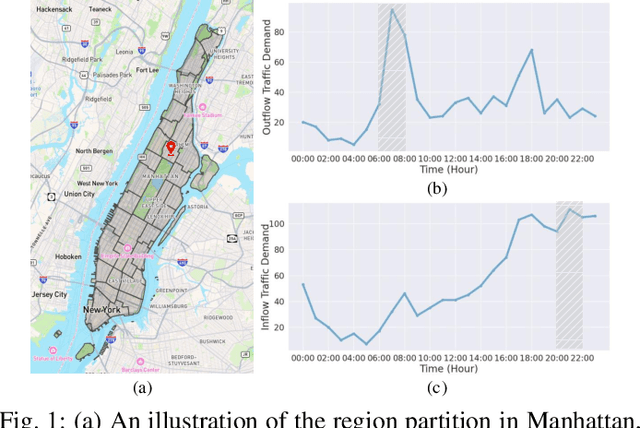
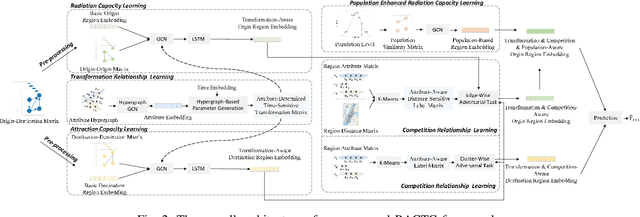
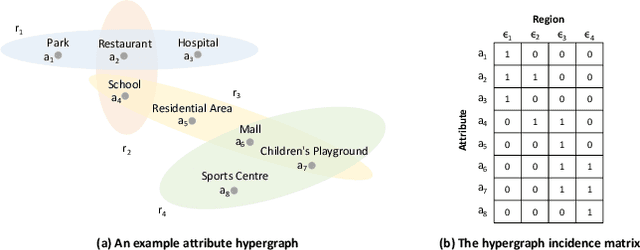
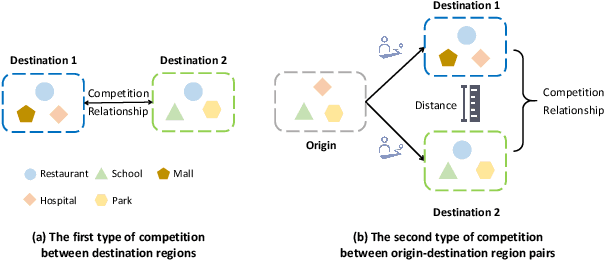
In recent years, origin-destination (OD) demand prediction has gained significant attention for its profound implications in urban development. Existing data-driven deep learning methods primarily focus on the spatial or temporal dependency between regions yet neglecting regions' fundamental functional difference. Though knowledge-driven physical methods have characterised regions' functions by their radiation and attraction capacities, these functions are defined on numerical factors like population without considering regions' intrinsic nominal attributes, e.g., a region is a residential or industrial district. Moreover, the complicated relationships between two types of capacities, e.g., the radiation capacity of a residential district in the morning will be transformed into the attraction capacity in the evening, are totally missing from physical methods. In this paper, we not only generalize the physical radiation and attraction capacities into the deep learning framework with the extended capability to fulfil regions' functions, but also present a new model that captures the relationships between two types of capacities. Specifically, we first model regions' radiation and attraction capacities using a bilateral branch network, each equipped with regions' attribute representations. We then describe the transformation relationship of different capacities of the same region using a hypergraph-based parameter generation method. We finally unveil the competition relationship of different regions with the same attraction capacity through cluster-based adversarial learning. Extensive experiments on two datasets demonstrate the consistent improvements of our method over the state-of-the-art baselines, as well as the good explainability of regions' functions using their nominal attributes.