 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinguistics-Aware Non-Distortionary LLM Watermarking
May 30, 2026Watermarking should identify language-model output without degrading quality or limiting verification to the model provider. Multilingual deployment makes this harder because morphology, segmentation, and script change where watermark evidence can enter naturally. We introduce LUNA, a linguistically adaptive watermark that combines model-free detection with single-token non-distortion under the standard random-key model. LUNA estimates normalized next-tag entropy from part-of-speech contexts in an external corpus and uses it to set the depth of a non-distortionary binary tournament sampler; the detector reconstructs the same schedule from text, a tokenizer, a tagger, and a secret key. We evaluate six typologically diverse languages and two domains against eight primary baselines. LUNA attains an AUROC of 0.9959 and the lowest mean absolute median perplexity shift of 0.045 across the twelve settings; its 95% bootstrap interval [0.022, 0.073] lies below all baseline intervals. LUNA also records the lowest mean Self-BLEU, Distinct-1, surprisal, and entropy shifts. It is the only method that simultaneously achieves AUROC > 0.99 and an absolute median perplexity shift below 0.1 in a majority of settings, reaching this regime in 9 of the 12 settings while no baseline reaches it in more than 2. Our code is available at: https://github.com/Shinwoo-Park/luna_watermark
Proactive Instance Navigation with Comparative Judgment for Ambiguous User Queries
May 07, 2026Natural-language instance navigation becomes challenging when the initial user request does not uniquely specify the target instance. A practical agent should reduce the user's burden by actively asking only the information needed to distinguish the target from similar distractors, rather than requiring a detailed description upfront. Existing approaches often fall short of this goal: they may stop at the first plausible candidate before sufficiently exploring alternatives, or, even after collecting multiple candidates, ask about the target's attributes derived from individual candidates rather than questions selected to distinguish candidates in the pool. As a result, despite the dialogue, the agent may still fail to distinguish the target from distractors, leading to premature decisions and lengthy user responses. We propose Proactive Instance Navigation with Comparative Judgment (ProCompNav), a two-stage framework that first constructs a candidate pool and then identifies the target through comparative judgment. At each round, ProCompNav extracts an attribute-value pair that splits the current pool, asks a binary yes/no question, and prunes all inconsistent candidates at once. This reframes disambiguation from open-ended target description to pool-level discriminative questioning, where each question is chosen to narrow the candidate set. On CoIN-Bench, ProCompNav improves Success Rate over interactive baselines with the same minimal input and non-interactive baselines with detailed descriptions, while substantially reducing Response Length. ProCompNav also achieves state-of-the-art Success Rate on TextNav, suggesting that comparative judgment is broadly useful for instance-level navigation among similar distractors.
FluoCLIP: Stain-Aware Focus Quality Assessment in Fluorescence Microscopy
Feb 27, 2026Accurate focus quality assessment (FQA) in fluorescence microscopy remains challenging, as the stain-dependent optical properties of fluorescent dyes cause abrupt and heterogeneous focus shifts. However, existing datasets and models overlook this variability, treating focus quality as a stain-agnostic problem. In this work, we formulate the task of stain-aware FQA, emphasizing that focus behavior in fluorescence microscopy must be modeled as a function of staining characteristics. Through quantitative analysis of existing datasets (FocusPath, BBBC006) and our newly curated FluoMix, we demonstrate that focus-rank relationships vary substantially across stains, underscoring the need for stain-aware modeling in fluorescence microscopy. To support this new formulation, we propose FluoMix, the first dataset for stain-aware FQA that encompasses multiple tissues, fluorescent stains, and focus variations. Building on this dataset, we propose FluoCLIP, a two-stage vision-language framework that leverages CLIP's alignment capability to interpret focus quality in the context of biological staining. In the stain-grounding phase, FluoCLIP learns general stain representations by aligning textual stain tokens with visual features, while in the stain-guided ranking phase, it optimizes stain-specific rank prompts for ordinal focus prediction. Together, our formulation, dataset, and framework establish the first foundation for stain-aware FQA, and FluoCLIP achieves strong generalization across diverse fluorescence microscopy conditions.
VIRO: Robust and Efficient Neuro-Symbolic Reasoning with Verification for Referring Expression Comprehension
Jan 19, 2026Referring Expression Comprehension (REC) aims to localize the image region corresponding to a natural-language query. Recent neuro-symbolic REC approaches leverage large language models (LLMs) and vision-language models (VLMs) to perform compositional reasoning, decomposing queries 4 structured programs and executing them step-by-step. While such approaches achieve interpretable reasoning and strong zero-shot generalization, they assume that intermediate reasoning steps are accurate. However, this assumption causes cascading errors: false detections and invalid relations propagate through the reasoning chain, yielding high-confidence false positives even when no target is present in the image. To address this limitation, we introduce Verification-Integrated Reasoning Operators (VIRO), a neuro-symbolic framework that embeds lightweight operator-level verifiers within reasoning steps. Each operator executes and validates its output, such as object existence or spatial relationship, thereby allowing the system to robustly handle no-target cases when verification conditions are not met. Our framework achieves state-of-the-art performance, reaching 61.1% balanced accuracy across target-present and no-target settings, and demonstrates generalization to real-world egocentric data. Furthermore, VIRO shows superior computational efficiency in terms of throughput, high reliability with a program failure rate of less than 0.3%, and scalability through decoupled program generation from execution.
WaterMod: Modular Token-Rank Partitioning for Probability-Balanced LLM Watermarking
Nov 13, 2025



Large language models now draft news, legal analyses, and software code with human-level fluency. At the same time, regulations such as the EU AI Act mandate that each synthetic passage carry an imperceptible, machine-verifiable mark for provenance. Conventional logit-based watermarks satisfy this requirement by selecting a pseudorandom green vocabulary at every decoding step and boosting its logits, yet the random split can exclude the highest-probability token and thus erode fluency. WaterMod mitigates this limitation through a probability-aware modular rule. The vocabulary is first sorted in descending model probability; the resulting ranks are then partitioned by the residue rank mod k, which distributes adjacent-and therefore semantically similar-tokens across different classes. A fixed bias of small magnitude is applied to one selected class. In the zero-bit setting (k=2), an entropy-adaptive gate selects either the even or the odd parity as the green list. Because the top two ranks fall into different parities, this choice embeds a detectable signal while guaranteeing that at least one high-probability token remains available for sampling. In the multi-bit regime (k>2), the current payload digit d selects the color class whose ranks satisfy rank mod k = d. Biasing the logits of that class embeds exactly one base-k digit per decoding step, thereby enabling fine-grained provenance tracing. The same modular arithmetic therefore supports both binary attribution and rich payloads. Experimental results demonstrate that WaterMod consistently attains strong watermark detection performance while maintaining generation quality in both zero-bit and multi-bit settings. This robustness holds across a range of tasks, including natural language generation, mathematical reasoning, and code synthesis. Our code and data are available at https://github.com/Shinwoo-Park/WaterMod.
Semantic Exploration with Adaptive Gating for Efficient Problem Solving with Language Models
Jan 10, 2025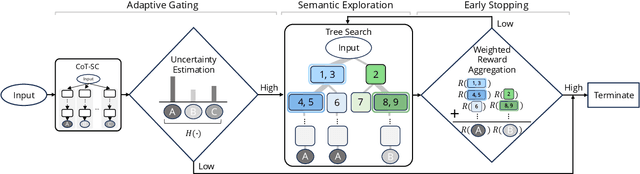
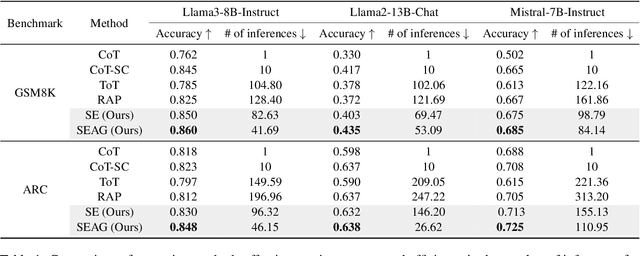
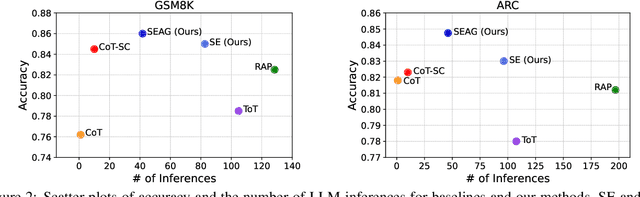
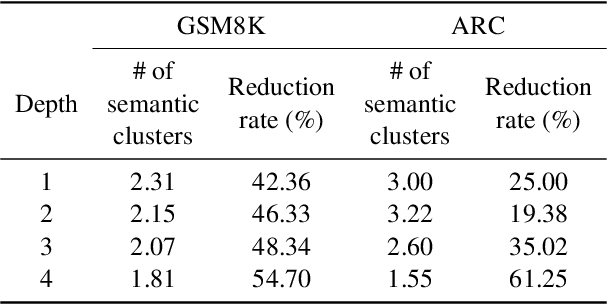
Recent advancements in large language models (LLMs) have shown remarkable potential in various complex tasks requiring multi-step reasoning methods like tree search to explore diverse reasoning paths. However, existing methods often suffer from computational inefficiency and redundancy. First, they overlook the diversity of task difficulties, leading to unnecessarily extensive searches even for easy tasks. Second, they neglect the semantics of reasoning paths, resulting in redundant exploration of semantically identical paths. To address these limitations, we propose Semantic Exploration with Adaptive Gating (SEAG), a computationally efficient method. SEAG employs an adaptive gating mechanism that dynamically decides whether to conduct a tree search, based on the confidence level of answers from a preceding simple reasoning method. Furthermore, its tree-based exploration consolidates semantically identical reasoning steps, reducing redundant explorations while maintaining or even improving accuracy. Our extensive experiments demonstrate that SEAG significantly improves accuracy by 4.3% on average while requiring only 31% of computational costs compared to existing tree search-based methods on complex reasoning benchmarks including GSM8K and ARC with diverse language models such as Llama2, Llama3, and Mistral.
Retrieval-Augmented Generation with Estimation of Source Reliability
Oct 30, 2024



Retrieval-augmented generation (RAG) addresses key limitations of large language models (LLMs), such as hallucinations and outdated knowledge, by incorporating external databases. These databases typically consult multiple sources to encompass up-to-date and various information. However, standard RAG methods often overlook the heterogeneous source reliability in the multi-source database and retrieve documents solely based on relevance, making them prone to propagating misinformation. To address this, we propose Reliability-Aware RAG (RA-RAG) which estimates the reliability of multiple sources and incorporates this information into both retrieval and aggregation processes. Specifically, it iteratively estimates source reliability and true answers for a set of queries with no labelling. Then, it selectively retrieves relevant documents from a few of reliable sources and aggregates them using weighted majority voting, where the selective retrieval ensures scalability while not compromising the performance. We also introduce a benchmark designed to reflect real-world scenarios with heterogeneous source reliability and demonstrate the effectiveness of RA-RAG compared to a set of baselines.
Hybrid-TTA: Continual Test-time Adaptation via Dynamic Domain Shift Detection
Sep 13, 2024Continual Test Time Adaptation (CTTA) has emerged as a critical approach for bridging the domain gap between the controlled training environments and the real-world scenarios, enhancing model adaptability and robustness. Existing CTTA methods, typically categorized into Full-Tuning (FT) and Efficient-Tuning (ET), struggle with effectively addressing domain shifts. To overcome these challenges, we propose Hybrid-TTA, a holistic approach that dynamically selects instance-wise tuning method for optimal adaptation. Our approach introduces the Dynamic Domain Shift Detection (DDSD) strategy, which identifies domain shifts by leveraging temporal correlations in input sequences and dynamically switches between FT and ET to adapt to varying domain shifts effectively. Additionally, the Masked Image Modeling based Adaptation (MIMA) framework is integrated to ensure domain-agnostic robustness with minimal computational overhead. Our Hybrid-TTA achieves a notable 1.6%p improvement in mIoU on the Cityscapes-to-ACDC benchmark dataset, surpassing previous state-of-the-art methods and offering a robust solution for real-world continual adaptation challenges.
Dynamic Guidance Adversarial Distillation with Enhanced Teacher Knowledge
Sep 03, 2024In the realm of Adversarial Distillation (AD), strategic and precise knowledge transfer from an adversarially robust teacher model to a less robust student model is paramount. Our Dynamic Guidance Adversarial Distillation (DGAD) framework directly tackles the challenge of differential sample importance, with a keen focus on rectifying the teacher model's misclassifications. DGAD employs Misclassification-Aware Partitioning (MAP) to dynamically tailor the distillation focus, optimizing the learning process by steering towards the most reliable teacher predictions. Additionally, our Error-corrective Label Swapping (ELS) corrects misclassifications of the teacher on both clean and adversarially perturbed inputs, refining the quality of knowledge transfer. Further, Predictive Consistency Regularization (PCR) guarantees consistent performance of the student model across both clean and adversarial inputs, significantly enhancing its overall robustness. By integrating these methodologies, DGAD significantly improves upon the accuracy of clean data and fortifies the model's defenses against sophisticated adversarial threats. Our experimental validation on CIFAR10, CIFAR100, and Tiny ImageNet datasets, employing various model architectures, demonstrates the efficacy of DGAD, establishing it as a promising approach for enhancing both the robustness and accuracy of student models in adversarial settings.
Emerging Property of Masked Token for Effective Pre-training
Apr 12, 2024



Driven by the success of Masked Language Modeling (MLM), the realm of self-supervised learning for computer vision has been invigorated by the central role of Masked Image Modeling (MIM) in driving recent breakthroughs. Notwithstanding the achievements of MIM across various downstream tasks, its overall efficiency is occasionally hampered by the lengthy duration of the pre-training phase. This paper presents a perspective that the optimization of masked tokens as a means of addressing the prevailing issue. Initially, we delve into an exploration of the inherent properties that a masked token ought to possess. Within the properties, we principally dedicated to articulating and emphasizing the `data singularity' attribute inherent in masked tokens. Through a comprehensive analysis of the heterogeneity between masked tokens and visible tokens within pre-trained models, we propose a novel approach termed masked token optimization (MTO), specifically designed to improve model efficiency through weight recalibration and the enhancement of the key property of masked tokens. The proposed method serves as an adaptable solution that seamlessly integrates into any MIM approach that leverages masked tokens. As a result, MTO achieves a considerable improvement in pre-training efficiency, resulting in an approximately 50% reduction in pre-training epochs required to attain converged performance of the recent approaches.