 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProAct: Agentic Lookahead in Interactive Environments
Feb 05, 2026Existing Large Language Model (LLM) agents struggle in interactive environments requiring long-horizon planning, primarily due to compounding errors when simulating future states. To address this, we propose ProAct, a framework that enables agents to internalize accurate lookahead reasoning through a two-stage training paradigm. First, we introduce Grounded LookAhead Distillation (GLAD), where the agent undergoes supervised fine-tuning on trajectories derived from environment-based search. By compressing complex search trees into concise, causal reasoning chains, the agent learns the logic of foresight without the computational overhead of inference-time search. Second, to further refine decision accuracy, we propose the Monte-Carlo Critic (MC-Critic), a plug-and-play auxiliary value estimator designed to enhance policy-gradient algorithms like PPO and GRPO. By leveraging lightweight environment rollouts to calibrate value estimates, MC-Critic provides a low-variance signal that facilitates stable policy optimization without relying on expensive model-based value approximation. Experiments on both stochastic (e.g., 2048) and deterministic (e.g., Sokoban) environments demonstrate that ProAct significantly improves planning accuracy. Notably, a 4B parameter model trained with ProAct outperforms all open-source baselines and rivals state-of-the-art closed-source models, while demonstrating robust generalization to unseen environments. The codes and models are available at https://github.com/GreatX3/ProAct
AT$^2$PO: Agentic Turn-based Policy Optimization via Tree Search
Jan 08, 2026LLM agents have emerged as powerful systems for tackling multi-turn tasks by interleaving internal reasoning and external tool interactions. Agentic Reinforcement Learning has recently drawn significant research attention as a critical post-training paradigm to further refine these capabilities. In this paper, we present AT$^2$PO (Agentic Turn-based Policy Optimization via Tree Search), a unified framework for multi-turn agentic RL that addresses three core challenges: limited exploration diversity, sparse credit assignment, and misaligned policy optimization. AT$^2$PO introduces a turn-level tree structure that jointly enables Entropy-Guided Tree Expansion for strategic exploration and Turn-wise Credit Assignment for fine-grained reward propagation from sparse outcomes. Complementing this, we propose Agentic Turn-based Policy Optimization, a turn-level learning objective that aligns policy updates with the natural decision granularity of agentic interactions. ATPO is orthogonal to tree search and can be readily integrated into any multi-turn RL pipeline. Experiments across seven benchmarks demonstrate consistent improvements over the state-of-the-art baseline by up to 1.84 percentage points in average, with ablation studies validating the effectiveness of each component. Our code is available at https://github.com/zzfoutofspace/ATPO.
S1-MMAlign: A Large-Scale, Multi-Disciplinary Dataset for Scientific Figure-Text Understanding
Jan 01, 2026Multimodal learning has revolutionized general domain tasks, yet its application in scientific discovery is hindered by the profound semantic gap between complex scientific imagery and sparse textual descriptions. We present S1-MMAlign, a large-scale, multi-disciplinary multimodal dataset comprising over 15.5 million high-quality image-text pairs derived from 2.5 million open-access scientific papers. Spanning disciplines from physics and biology to engineering, the dataset captures diverse visual modalities including experimental setups, heatmaps, and microscopic imagery. To address the pervasive issue of weak alignment in raw scientific captions, we introduce an AI-ready semantic enhancement pipeline that utilizes the Qwen-VL multimodal large model series to recaption images by synthesizing context from paper abstracts and citation contexts. Technical validation demonstrates that this enhancement significantly improves data quality: SciBERT-based pseudo-perplexity metrics show reduced semantic ambiguity, while CLIP scores indicate an 18.21% improvement in image-text alignment. S1-MMAlign provides a foundational resource for advancing scientific reasoning and cross-modal understanding in the era of AI for Science. The dataset is publicly available at https://huggingface.co/datasets/ScienceOne-AI/S1-MMAlign.
HY-Motion 1.0: Scaling Flow Matching Models for Text-To-Motion Generation
Dec 29, 2025We present HY-Motion 1.0, a series of state-of-the-art, large-scale, motion generation models capable of generating 3D human motions from textual descriptions. HY-Motion 1.0 represents the first successful attempt to scale up Diffusion Transformer (DiT)-based flow matching models to the billion-parameter scale within the motion generation domain, delivering instruction-following capabilities that significantly outperform current open-source benchmarks. Uniquely, we introduce a comprehensive, full-stage training paradigm -- including large-scale pretraining on over 3,000 hours of motion data, high-quality fine-tuning on 400 hours of curated data, and reinforcement learning from both human feedback and reward models -- to ensure precise alignment with the text instruction and high motion quality. This framework is supported by our meticulous data processing pipeline, which performs rigorous motion cleaning and captioning. Consequently, our model achieves the most extensive coverage, spanning over 200 motion categories across 6 major classes. We release HY-Motion 1.0 to the open-source community to foster future research and accelerate the transition of 3D human motion generation models towards commercial maturity.
From Feature Interaction to Feature Generation: A Generative Paradigm of CTR Prediction Models
Dec 16, 2025



Click-Through Rate (CTR) prediction, a core task in recommendation systems, aims to estimate the probability of users clicking on items. Existing models predominantly follow a discriminative paradigm, which relies heavily on explicit interactions between raw ID embeddings. However, this paradigm inherently renders them susceptible to two critical issues: embedding dimensional collapse and information redundancy, stemming from the over-reliance on feature interactions \emph{over raw ID embeddings}. To address these limitations, we propose a novel \emph{Supervised Feature Generation (SFG)} framework, \emph{shifting the paradigm from discriminative ``feature interaction" to generative ``feature generation"}. Specifically, SFG comprises two key components: an \emph{Encoder} that constructs hidden embeddings for each feature, and a \emph{Decoder} tasked with regenerating the feature embeddings of all features from these hidden representations. Unlike existing generative approaches that adopt self-supervised losses, we introduce a supervised loss to utilize the supervised signal, \ie, click or not, in the CTR prediction task. This framework exhibits strong generalizability: it can be seamlessly integrated with most existing CTR models, reformulating them under the generative paradigm. Extensive experiments demonstrate that SFG consistently mitigates embedding collapse and reduces information redundancy, while yielding substantial performance gains across various datasets and base models. The code is available at https://github.com/USTC-StarTeam/GE4Rec.
InpaintDPO: Mitigating Spatial Relationship Hallucinations in Foreground-conditioned Inpainting via Diverse Preference Optimization
Dec 16, 2025



Foreground-conditioned inpainting, which aims at generating a harmonious background for a given foreground subject based on the text prompt, is an important subfield in controllable image generation. A common challenge in current methods, however, is the occurrence of Spatial Relationship Hallucinations between the foreground subject and the generated background, including inappropriate scale, positional relationships, and viewpoints. Critically, the subjective nature of spatial rationality makes it challenging to quantify, hindering the use of traditional reward-based RLHF methods. To address this issue, we propose InpaintDPO, the first Direct Preference Optimization (DPO) based framework dedicated to spatial rationality in foreground-conditioned inpainting, ensuring plausible spatial relationships between foreground and background elements. To resolve the gradient conflicts in standard DPO caused by identical foreground in win-lose pairs, we propose MaskDPO, which confines preference optimization exclusively to the background to enhance background spatial relationships, while retaining the inpainting loss in the foreground region for robust foreground preservation. To enhance coherence at the foreground-background boundary, we propose Conditional Asymmetric Preference Optimization, which samples pairs with differentiated cropping operations and applies global preference optimization to promote contextual awareness and enhance boundary coherence. Finally, based on the observation that winning samples share a commonality in plausible spatial relationships, we propose Shared Commonality Preference Optimization to enhance the model's understanding of spatial commonality across high-quality winning samples, further promoting shared spatial rationality.
GPR: Towards a Generative Pre-trained One-Model Paradigm for Large-Scale Advertising Recommendation
Nov 13, 2025



As an intelligent infrastructure connecting users with commercial content, advertising recommendation systems play a central role in information flow and value creation within the digital economy. However, existing multi-stage advertising recommendation systems suffer from objective misalignment and error propagation, making it difficult to achieve global optimality, while unified generative recommendation models still struggle to meet the demands of practical industrial applications. To address these issues, we propose GPR (Generative Pre-trained Recommender), the first one-model framework that redefines advertising recommendation as an end-to-end generative task, replacing the traditional cascading paradigm with a unified generative approach. To realize GPR, we introduce three key innovations spanning unified representation, network architecture, and training strategy. First, we design a unified input schema and tokenization method tailored to advertising scenarios, mapping both ads and organic content into a shared multi-level semantic ID space, thereby enhancing semantic alignment and modeling consistency across heterogeneous data. Second, we develop the Heterogeneous Hierarchical Decoder (HHD), a dual-decoder architecture that decouples user intent modeling from ad generation, achieving a balance between training efficiency and inference flexibility while maintaining strong modeling capacity. Finally, we propose a multi-stage joint training strategy that integrates Multi-Token Prediction (MTP), Value-Aware Fine-Tuning and the Hierarchy Enhanced Policy Optimization (HEPO) algorithm, forming a complete generative recommendation pipeline that unifies interest modeling, value alignment, and policy optimization. GPR has been fully deployed in the Tencent Weixin Channels advertising system, delivering significant improvements in key business metrics including GMV and CTCVR.
Hunyuan3D Studio: End-to-End AI Pipeline for Game-Ready 3D Asset Generation
Sep 16, 2025



The creation of high-quality 3D assets, a cornerstone of modern game development, has long been characterized by labor-intensive and specialized workflows. This paper presents Hunyuan3D Studio, an end-to-end AI-powered content creation platform designed to revolutionize the game production pipeline by automating and streamlining the generation of game-ready 3D assets. At its core, Hunyuan3D Studio integrates a suite of advanced neural modules (such as Part-level 3D Generation, Polygon Generation, Semantic UV, etc.) into a cohesive and user-friendly system. This unified framework allows for the rapid transformation of a single concept image or textual description into a fully-realized, production-quality 3D model complete with optimized geometry and high-fidelity PBR textures. We demonstrate that assets generated by Hunyuan3D Studio are not only visually compelling but also adhere to the stringent technical requirements of contemporary game engines, significantly reducing iteration time and lowering the barrier to entry for 3D content creation. By providing a seamless bridge from creative intent to technical asset, Hunyuan3D Studio represents a significant leap forward for AI-assisted workflows in game development and interactive media.
R-4B: Incentivizing General-Purpose Auto-Thinking Capability in MLLMs via Bi-Mode Annealing and Reinforce Learning
Aug 28, 2025



Multimodal Large Language Models (MLLMs) equipped with step-by-step thinking capabilities have demonstrated remarkable performance on complex reasoning problems. However, this thinking process is redundant for simple problems solvable without complex reasoning. To address this inefficiency, we propose R-4B, an auto-thinking MLLM, which can adaptively decide when to think based on problem complexity. The central idea of R-4B is to empower the model with both thinking and non-thinking capabilities using bi-mode annealing, and apply Bi-mode Policy Optimization~(BPO) to improve the model's accuracy in determining whether to activate the thinking process. Specifically, we first train the model on a carefully curated dataset spanning various topics, which contains samples from both thinking and non-thinking modes. Then it undergoes a second phase of training under an improved GRPO framework, where the policy model is forced to generate responses from both modes for each input query. Experimental results show that R-4B achieves state-of-the-art performance across 25 challenging benchmarks. It outperforms Qwen2.5-VL-7B in most tasks and achieves performance comparable to larger models such as Kimi-VL-A3B-Thinking-2506 (16B) on reasoning-intensive benchmarks with lower computational cost.
Large Foundation Model for Ads Recommendation
Aug 20, 2025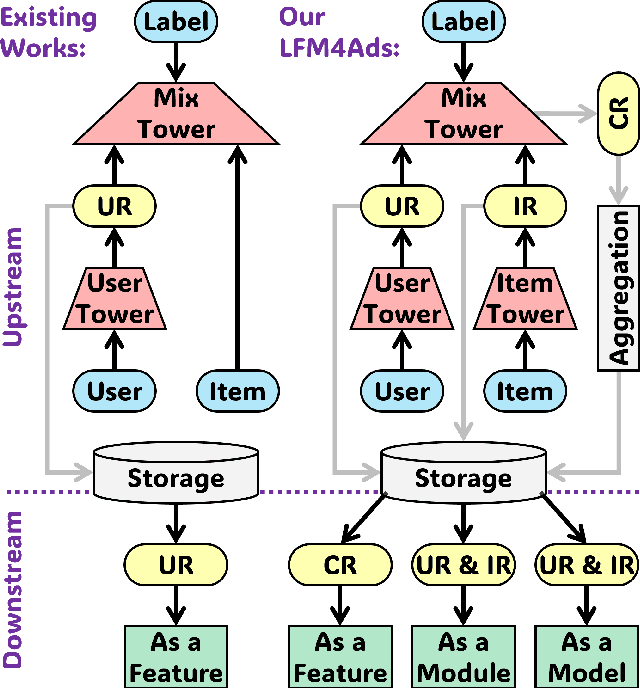
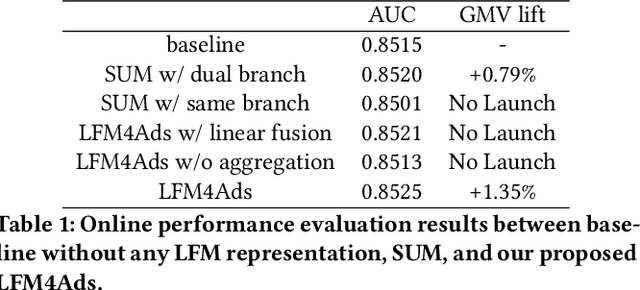
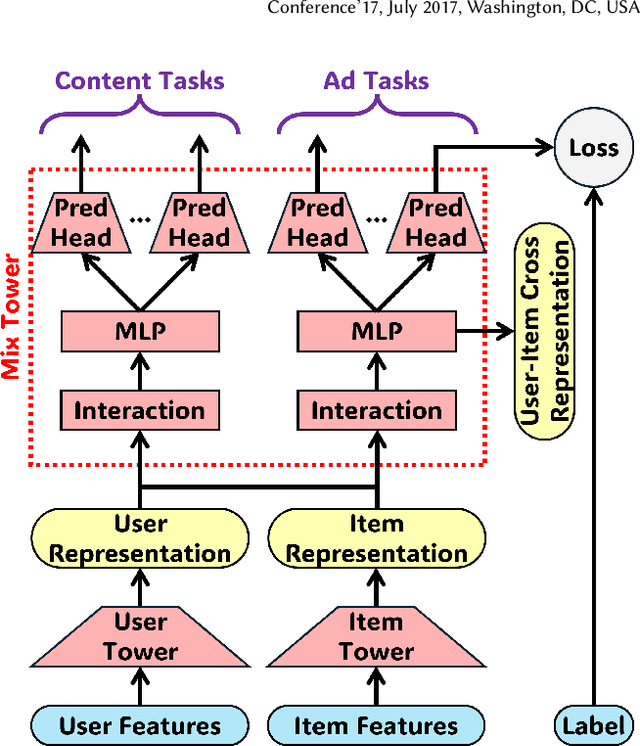
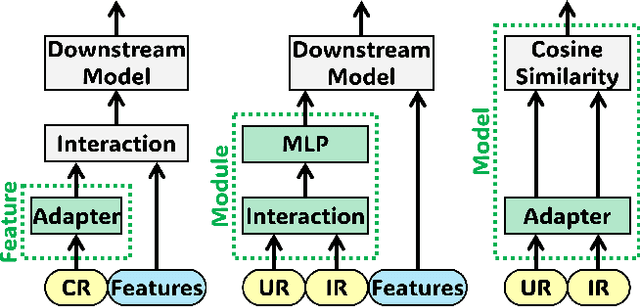
Online advertising relies on accurate recommendation models, with recent advances using pre-trained large-scale foundation models (LFMs) to capture users' general interests across multiple scenarios and tasks. However, existing methods have critical limitations: they extract and transfer only user representations (URs), ignoring valuable item representations (IRs) and user-item cross representations (CRs); and they simply use a UR as a feature in downstream applications, which fails to bridge upstream-downstream gaps and overlooks more transfer granularities. In this paper, we propose LFM4Ads, an All-Representation Multi-Granularity transfer framework for ads recommendation. It first comprehensively transfers URs, IRs, and CRs, i.e., all available representations in the pre-trained foundation model. To effectively utilize the CRs, it identifies the optimal extraction layer and aggregates them into transferable coarse-grained forms. Furthermore, we enhance the transferability via multi-granularity mechanisms: non-linear adapters for feature-level transfer, an Isomorphic Interaction Module for module-level transfer, and Standalone Retrieval for model-level transfer. LFM4Ads has been successfully deployed in Tencent's industrial-scale advertising platform, processing tens of billions of daily samples while maintaining terabyte-scale model parameters with billions of sparse embedding keys across approximately two thousand features. Since its production deployment in Q4 2024, LFM4Ads has achieved 10+ successful production launches across various advertising scenarios, including primary ones like Weixin Moments and Channels. These launches achieve an overall GMV lift of 2.45% across the entire platform, translating to estimated annual revenue increases in the hundreds of millions of dollars.