 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing Through the Chain: Mitigate Hallucination in Multimodal Reasoning Models via CoT Compression and Contrastive Preference Optimization
Feb 03, 2026While multimodal reasoning models (MLRMs) have exhibited impressive capabilities, they remain prone to hallucinations, and effective solutions are still underexplored. In this paper, we experimentally analyze the hallucination cause and propose C3PO, a training-based mitigation framework comprising \textbf{C}hain-of-Thought \textbf{C}ompression and \textbf{C}ontrastive \textbf{P}reference \textbf{O}ptimization. Firstly, we identify that introducing reasoning mechanisms exacerbates models' reliance on language priors while overlooking visual inputs, which can produce CoTs with reduced visual cues but redundant text tokens. To this end, we propose to selectively filter redundant thinking tokens for a more compact and signal-efficient CoT representation that preserves task-relevant information while suppressing noise. In addition, we observe that the quality of the reasoning trace largely determines whether hallucination emerges in subsequent responses. To leverage this insight, we introduce a reasoning-enhanced preference tuning scheme that constructs training pairs using high-quality AI feedback. We further design a multimodal hallucination-inducing mechanism that elicits models' inherent hallucination patterns via carefully crafted inducers, yielding informative negative signals for contrastive correction. We provide theoretical justification for the effectiveness and demonstrate consistent hallucination reduction across diverse MLRMs and benchmarks.
Towards Distillation-Resistant Large Language Models: An Information-Theoretic Perspective
Feb 03, 2026Proprietary large language models (LLMs) embody substantial economic value and are generally exposed only as black-box APIs, yet adversaries can still exploit their outputs to extract knowledge via distillation. Existing defenses focus exclusively on text-based distillation, leaving the important logit-based distillation largely unexplored. In this work, we analyze this problem and present an effective solution from an information-theoretic perspective. We characterize distillation-relevant information in teacher outputs using the conditional mutual information (CMI) between teacher logits and input queries conditioned on ground-truth labels. This quantity captures contextual information beneficial for model extraction, motivating us to defend distillation via CMI minimization. Guided by our theoretical analysis, we propose learning a transformation matrix that purifies the original outputs to enhance distillation resistance. We further derive a CMI-inspired anti-distillation objective to optimize this transformation, which effectively removes distillation-relevant information while preserving output utility. Extensive experiments across multiple LLMs and strong distillation algorithms demonstrate that the proposed method significantly degrades distillation performance while preserving task accuracy, effectively protecting models' intellectual property.
Large Foundation Model for Ads Recommendation
Aug 20, 2025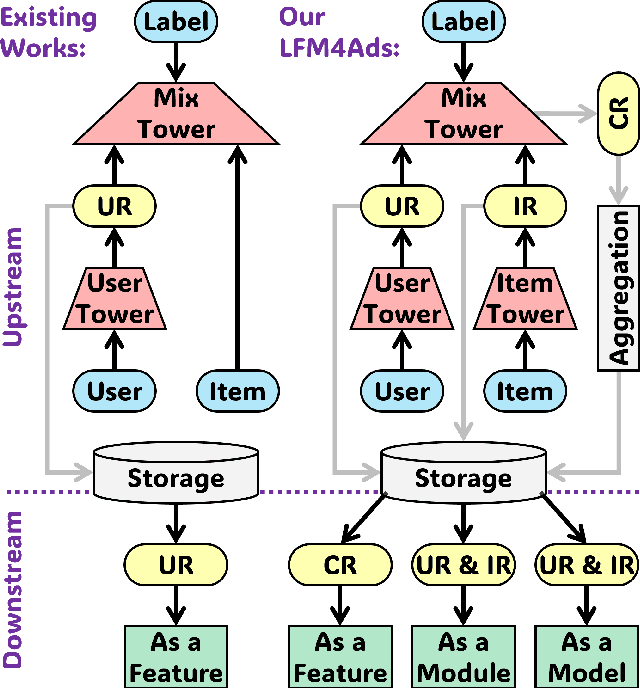
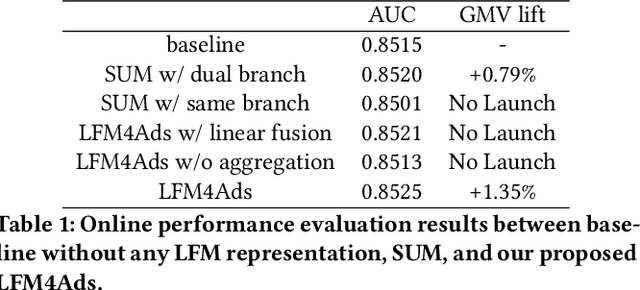
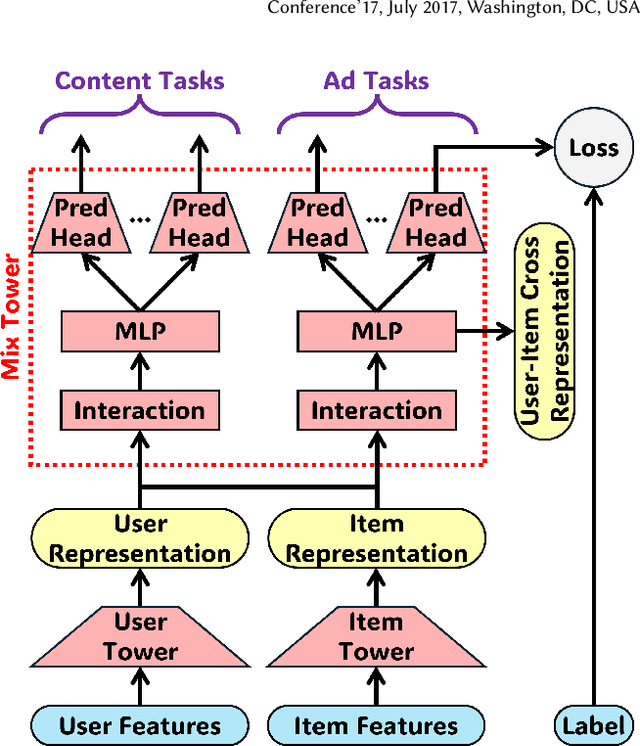
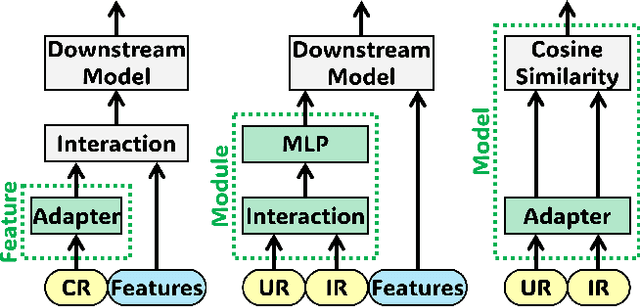
Online advertising relies on accurate recommendation models, with recent advances using pre-trained large-scale foundation models (LFMs) to capture users' general interests across multiple scenarios and tasks. However, existing methods have critical limitations: they extract and transfer only user representations (URs), ignoring valuable item representations (IRs) and user-item cross representations (CRs); and they simply use a UR as a feature in downstream applications, which fails to bridge upstream-downstream gaps and overlooks more transfer granularities. In this paper, we propose LFM4Ads, an All-Representation Multi-Granularity transfer framework for ads recommendation. It first comprehensively transfers URs, IRs, and CRs, i.e., all available representations in the pre-trained foundation model. To effectively utilize the CRs, it identifies the optimal extraction layer and aggregates them into transferable coarse-grained forms. Furthermore, we enhance the transferability via multi-granularity mechanisms: non-linear adapters for feature-level transfer, an Isomorphic Interaction Module for module-level transfer, and Standalone Retrieval for model-level transfer. LFM4Ads has been successfully deployed in Tencent's industrial-scale advertising platform, processing tens of billions of daily samples while maintaining terabyte-scale model parameters with billions of sparse embedding keys across approximately two thousand features. Since its production deployment in Q4 2024, LFM4Ads has achieved 10+ successful production launches across various advertising scenarios, including primary ones like Weixin Moments and Channels. These launches achieve an overall GMV lift of 2.45% across the entire platform, translating to estimated annual revenue increases in the hundreds of millions of dollars.
Your Language Model Can Secretly Write Like Humans: Contrastive Paraphrase Attacks on LLM-Generated Text Detectors
May 21, 2025



The misuse of large language models (LLMs), such as academic plagiarism, has driven the development of detectors to identify LLM-generated texts. To bypass these detectors, paraphrase attacks have emerged to purposely rewrite these texts to evade detection. Despite the success, existing methods require substantial data and computational budgets to train a specialized paraphraser, and their attack efficacy greatly reduces when faced with advanced detection algorithms. To address this, we propose \textbf{Co}ntrastive \textbf{P}araphrase \textbf{A}ttack (CoPA), a training-free method that effectively deceives text detectors using off-the-shelf LLMs. The first step is to carefully craft instructions that encourage LLMs to produce more human-like texts. Nonetheless, we observe that the inherent statistical biases of LLMs can still result in some generated texts carrying certain machine-like attributes that can be captured by detectors. To overcome this, CoPA constructs an auxiliary machine-like word distribution as a contrast to the human-like distribution generated by the LLM. By subtracting the machine-like patterns from the human-like distribution during the decoding process, CoPA is able to produce sentences that are less discernible by text detectors. Our theoretical analysis suggests the superiority of the proposed attack. Extensive experiments validate the effectiveness of CoPA in fooling text detectors across various scenarios.
A Noise-tolerant Differentiable Learning Approach for Single Occurrence Regular Expression with Interleaving
Dec 02, 2022



We study the problem of learning a single occurrence regular expression with interleaving (SOIRE) from a set of text strings possibly with noise. SOIRE fully supports interleaving and covers a large portion of regular expressions used in practice. Learning SOIREs is challenging because it requires heavy computation and text strings usually contain noise in practice. Most of the previous studies only learn restricted SOIREs and are not robust on noisy data. To tackle these issues, we propose a noise-tolerant differentiable learning approach SOIREDL for SOIRE. We design a neural network to simulate SOIRE matching and theoretically prove that certain assignments of the set of parameters learnt by the neural network, called faithful encodings, are one-to-one corresponding to SOIREs for a bounded size. Based on this correspondence, we interpret the target SOIRE from an assignment of the set of parameters of the neural network by exploring the nearest faithful encodings. Experimental results show that SOIREDL outperforms the state-of-the-art approaches, especially on noisy data.