 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeasibility of Indoor Frame-Wise Lidar Semantic Segmentation via Distillation from Visual Foundation Model
Apr 20, 2026Frame-wise semantic segmentation of indoor lidar scans is a fundamental step toward higher-level 3D scene understanding and mapping applications. However, acquiring frame-wise ground truth for training deep learning models is costly and time-consuming. This challenge is largely addressed, for imagery, by Visual Foundation Models (VFMs) which segment image frames. The same VFMs may be used to train a lidar scan frame segmentation model via a 2D-to-3D distillation pipeline. The success of such distillation has been shown for autonomous driving scenes, but not yet for indoor scenes. Here, we study the feasibility of repeating this success for indoor scenes, in a frame-wise distillation manner by coupling each lidar scan with a VFM-processed camera image. The evaluation is done using indoor SLAM datasets, where pseudo-labels are used for downstream evaluation. Also, a small manually annotated lidar dataset is provided for validation, as there are no other lidar frame-wise indoor datasets with semantics. Results show that the distilled model achieves up to 56% mIoU under pseudo-label evaluation and around 36% mIoU with real-label, demonstrating the feasibility of cross-modal distillation for indoor lidar semantic segmentation without manual annotations.
FarmMind: Reasoning-Query-Driven Dynamic Segmentation for Farmland Remote Sensing Images
Jan 30, 2026Existing methods for farmland remote sensing image (FRSI) segmentation generally follow a static segmentation paradigm, where analysis relies solely on the limited information contained within a single input patch. Consequently, their reasoning capability is limited when dealing with complex scenes characterized by ambiguity and visual uncertainty. In contrast, human experts, when interpreting remote sensing images in such ambiguous cases, tend to actively query auxiliary images (such as higher-resolution, larger-scale, or temporally adjacent data) to conduct cross-verification and achieve more comprehensive reasoning. Inspired by this, we propose a reasoning-query-driven dynamic segmentation framework for FRSIs, named FarmMind. This framework breaks through the limitations of the static segmentation paradigm by introducing a reasoning-query mechanism, which dynamically and on-demand queries external auxiliary images to compensate for the insufficient information in a single input image. Unlike direct queries, this mechanism simulates the thinking process of human experts when faced with segmentation ambiguity: it first analyzes the root causes of segmentation ambiguities through reasoning, and then determines what type of auxiliary image needs to be queried based on this analysis. Extensive experiments demonstrate that FarmMind achieves superior segmentation performance and stronger generalization ability compared with existing methods. The source code and dataset used in this work are publicly available at: https://github.com/WithoutOcean/FarmMind.
CauTraj: A Causal-Knowledge-Guided Framework for Lane-Changing Trajectory Planning of Autonomous Vehicles
Dec 21, 2025



Enhancing the performance of trajectory planners for lane - changing vehicles is one of the key challenges in autonomous driving within human - machine mixed traffic. Most existing studies have not incorporated human drivers' prior knowledge when designing trajectory planning models. To address this issue, this study proposes a novel trajectory planning framework that integrates causal prior knowledge into the control process. Both longitudinal and lateral microscopic behaviors of vehicles are modeled to quantify interaction risk, and a staged causal graph is constructed to capture causal dependencies in lane-changing scenarios. Causal effects between the lane-changing vehicle and surrounding vehicles are then estimated using causal inference, including average causal effects (ATE) and conditional average treatment effects (CATE). These causal priors are embedded into a model predictive control (MPC) framework to enhance trajectory planning. The proposed approach is validated on naturalistic vehicle trajectory datasets. Experimental results show that: (1) causal inference provides interpretable and stable quantification of vehicle interactions; (2) individual causal effects reveal driver heterogeneity; and (3) compared with the baseline MPC, the proposed method achieves a closer alignment with human driving behaviors, reducing maximum trajectory deviation from 1.2 m to 0.2 m, lateral velocity fluctuation by 60%, and yaw angle variability by 50%. These findings provide methodological support for human-like trajectory planning and practical value for improving safety, stability, and realism in autonomous vehicle testing and traffic simulation platforms.
Multi-Agent VLMs Guided Self-Training with PNU Loss for Low-Resource Offensive Content Detection
Nov 14, 2025



Accurate detection of offensive content on social media demands high-quality labeled data; however, such data is often scarce due to the low prevalence of offensive instances and the high cost of manual annotation. To address this low-resource challenge, we propose a self-training framework that leverages abundant unlabeled data through collaborative pseudo-labeling. Starting with a lightweight classifier trained on limited labeled data, our method iteratively assigns pseudo-labels to unlabeled instances with the support of Multi-Agent Vision-Language Models (MA-VLMs). Un-labeled data on which the classifier and MA-VLMs agree are designated as the Agreed-Unknown set, while conflicting samples form the Disagreed-Unknown set. To enhance label reliability, MA-VLMs simulate dual perspectives, moderator and user, capturing both regulatory and subjective viewpoints. The classifier is optimized using a novel Positive-Negative-Unlabeled (PNU) loss, which jointly exploits labeled, Agreed-Unknown, and Disagreed-Unknown data while mitigating pseudo-label noise. Experiments on benchmark datasets demonstrate that our framework substantially outperforms baselines under limited supervision and approaches the performance of large-scale models
GPR: Towards a Generative Pre-trained One-Model Paradigm for Large-Scale Advertising Recommendation
Nov 13, 2025



As an intelligent infrastructure connecting users with commercial content, advertising recommendation systems play a central role in information flow and value creation within the digital economy. However, existing multi-stage advertising recommendation systems suffer from objective misalignment and error propagation, making it difficult to achieve global optimality, while unified generative recommendation models still struggle to meet the demands of practical industrial applications. To address these issues, we propose GPR (Generative Pre-trained Recommender), the first one-model framework that redefines advertising recommendation as an end-to-end generative task, replacing the traditional cascading paradigm with a unified generative approach. To realize GPR, we introduce three key innovations spanning unified representation, network architecture, and training strategy. First, we design a unified input schema and tokenization method tailored to advertising scenarios, mapping both ads and organic content into a shared multi-level semantic ID space, thereby enhancing semantic alignment and modeling consistency across heterogeneous data. Second, we develop the Heterogeneous Hierarchical Decoder (HHD), a dual-decoder architecture that decouples user intent modeling from ad generation, achieving a balance between training efficiency and inference flexibility while maintaining strong modeling capacity. Finally, we propose a multi-stage joint training strategy that integrates Multi-Token Prediction (MTP), Value-Aware Fine-Tuning and the Hierarchy Enhanced Policy Optimization (HEPO) algorithm, forming a complete generative recommendation pipeline that unifies interest modeling, value alignment, and policy optimization. GPR has been fully deployed in the Tencent Weixin Channels advertising system, delivering significant improvements in key business metrics including GMV and CTCVR.
Remote Sensing Image Intelligent Interpretation with the Language-Centered Perspective: Principles, Methods and Challenges
Aug 09, 2025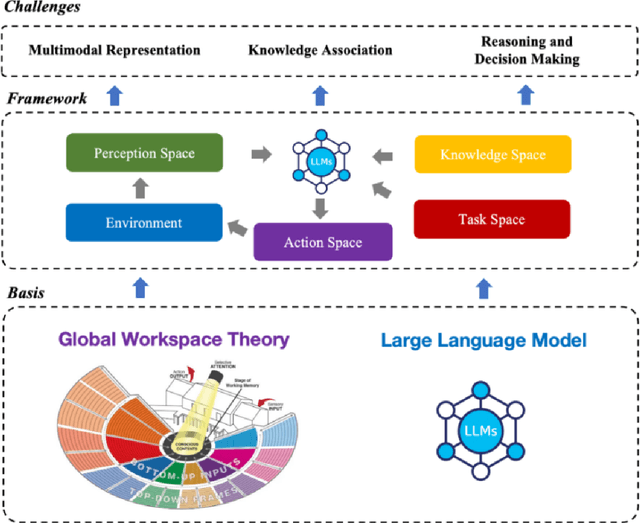
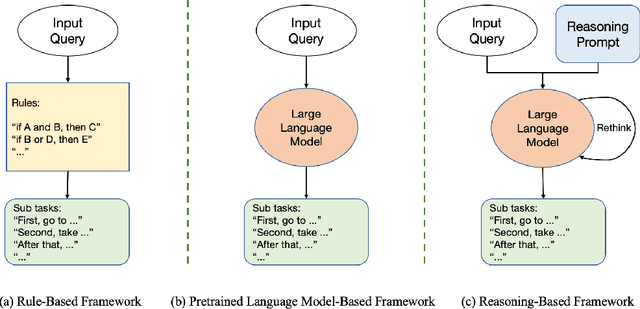
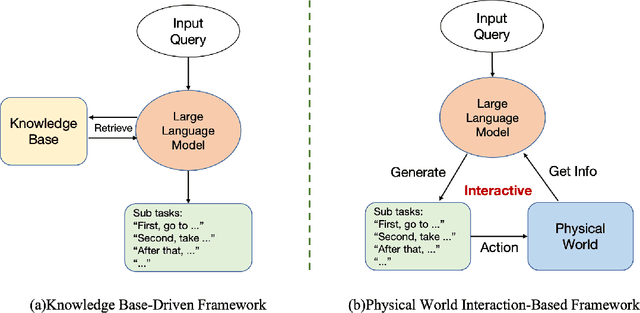
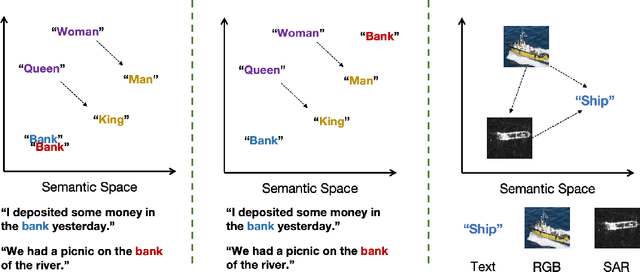
The mainstream paradigm of remote sensing image interpretation has long been dominated by vision-centered models, which rely on visual features for semantic understanding. However, these models face inherent limitations in handling multi-modal reasoning, semantic abstraction, and interactive decision-making. While recent advances have introduced Large Language Models (LLMs) into remote sensing workflows, existing studies primarily focus on downstream applications, lacking a unified theoretical framework that explains the cognitive role of language. This review advocates a paradigm shift from vision-centered to language-centered remote sensing interpretation. Drawing inspiration from the Global Workspace Theory (GWT) of human cognition, We propose a language-centered framework for remote sensing interpretation that treats LLMs as the cognitive central hub integrating perceptual, task, knowledge and action spaces to enable unified understanding, reasoning, and decision-making. We first explore the potential of LLMs as the central cognitive component in remote sensing interpretation, and then summarize core technical challenges, including unified multimodal representation, knowledge association, and reasoning and decision-making. Furthermore, we construct a global workspace-driven interpretation mechanism and review how language-centered solutions address each challenge. Finally, we outline future research directions from four perspectives: adaptive alignment of multimodal data, task understanding under dynamic knowledge constraints, trustworthy reasoning, and autonomous interaction. This work aims to provide a conceptual foundation for the next generation of remote sensing interpretation systems and establish a roadmap toward cognition-driven intelligent geospatial analysis.
A Joint Learning Framework with Feature Reconstruction and Prediction for Incomplete Satellite Image Time Series in Agricultural Semantic Segmentation
May 25, 2025



Satellite Image Time Series (SITS) is crucial for agricultural semantic segmentation. However, Cloud contamination introduces time gaps in SITS, disrupting temporal dependencies and causing feature shifts, leading to degraded performance of models trained on complete SITS. Existing methods typically address this by reconstructing the entire SITS before prediction or using data augmentation to simulate missing data. Yet, full reconstruction may introduce noise and redundancy, while the data-augmented model can only handle limited missing patterns, leading to poor generalization. We propose a joint learning framework with feature reconstruction and prediction to address incomplete SITS more effectively. During training, we simulate data-missing scenarios using temporal masks. The two tasks are guided by both ground-truth labels and the teacher model trained on complete SITS. The prediction task constrains the model from selectively reconstructing critical features from masked inputs that align with the teacher's temporal feature representations. It reduces unnecessary reconstruction and limits noise propagation. By integrating reconstructed features into the prediction task, the model avoids learning shortcuts and maintains its ability to handle varied missing patterns and complete SITS. Experiments on SITS from Hunan Province, Western France, and Catalonia show that our method improves mean F1-scores by 6.93% in cropland extraction and 7.09% in crop classification over baselines. It also generalizes well across satellite sensors, including Sentinel-2 and PlanetScope, under varying temporal missing rates and model backbones.
POPEN: Preference-Based Optimization and Ensemble for LVLM-Based Reasoning Segmentation
Apr 01, 2025



Existing LVLM-based reasoning segmentation methods often suffer from imprecise segmentation results and hallucinations in their text responses. This paper introduces POPEN, a novel framework designed to address these issues and achieve improved results. POPEN includes a preference-based optimization method to finetune the LVLM, aligning it more closely with human preferences and thereby generating better text responses and segmentation results. Additionally, POPEN introduces a preference-based ensemble method for inference, which integrates multiple outputs from the LVLM using a preference-score-based attention mechanism for refinement. To better adapt to the segmentation task, we incorporate several task-specific designs in our POPEN framework, including a new approach for collecting segmentation preference data with a curriculum learning mechanism, and a novel preference optimization loss to refine the segmentation capability of the LVLM. Experiments demonstrate that our method achieves state-of-the-art performance in reasoning segmentation, exhibiting minimal hallucination in text responses and the highest segmentation accuracy compared to previous advanced methods like LISA and PixelLM. Project page is https://lanyunzhu.site/POPEN/
A large-scale image-text dataset benchmark for farmland segmentation
Mar 29, 2025



The traditional deep learning paradigm that solely relies on labeled data has limitations in representing the spatial relationships between farmland elements and the surrounding environment.It struggles to effectively model the dynamic temporal evolution and spatial heterogeneity of farmland. Language,as a structured knowledge carrier,can explicitly express the spatiotemporal characteristics of farmland, such as its shape, distribution,and surrounding environmental information.Therefore,a language-driven learning paradigm can effectively alleviate the challenges posed by the spatiotemporal heterogeneity of farmland.However,in the field of remote sensing imagery of farmland,there is currently no comprehensive benchmark dataset to support this research direction.To fill this gap,we introduced language based descriptions of farmland and developed FarmSeg-VL dataset,the first fine-grained image-text dataset designed for spatiotemporal farmland segmentation.Firstly, this article proposed a semi-automatic annotation method that can accurately assign caption to each image, ensuring high data quality and semantic richness while improving the efficiency of dataset construction.Secondly,the FarmSeg-VL exhibits significant spatiotemporal characteristics.In terms of the temporal dimension,it covers all four seasons.In terms of the spatial dimension,it covers eight typical agricultural regions across China.In addition, in terms of captions,FarmSeg-VL covers rich spatiotemporal characteristics of farmland,including its inherent properties,phenological characteristics, spatial distribution,topographic and geomorphic features,and the distribution of surrounding environments.Finally,we present a performance analysis of VLMs and the deep learning models that rely solely on labels trained on the FarmSeg-VL,demonstrating its potential as a standard benchmark for farmland segmentation.
AdaS&S: a One-Shot Supernet Approach for Automatic Embedding Size Search in Deep Recommender System
Nov 12, 2024



Deep Learning Recommendation Model(DLRM)s utilize the embedding layer to represent various categorical features. Traditional DLRMs adopt unified embedding size for all features, leading to suboptimal performance and redundant parameters. Thus, lots of Automatic Embedding size Search (AES) works focus on obtaining mixed embedding sizes with strong model performance. However, previous AES works can hardly address several challenges together: (1) The search results of embedding sizes are unstable; (2) Recommendation effect with AES results is unsatisfactory; (3) Memory cost of embeddings is uncontrollable. To address these challenges, we propose a novel one-shot AES framework called AdaS&S, in which a supernet encompassing various candidate embeddings is built and AES is performed as searching network architectures within it. Our framework contains two main stages: In the first stage, we decouple training parameters from searching embedding sizes, and propose the Adaptive Sampling method to yield a well-trained supernet, which further helps to produce stable AES results. In the second stage, to obtain embedding sizes that benefits the model effect, we design a reinforcement learning search process which utilizes the supernet trained previously. Meanwhile, to adapt searching to specific resource constraint, we introduce the resource competition penalty to balance the model effectiveness and memory cost of embeddings. We conduct extensive experiments on public datasets to show the superiority of AdaS&S. Our method could improve AUC by about 0.3% while saving about 20% of model parameters. Empirical analysis also shows that the stability of searching results in AdaS&S significantly exceeds other methods.