 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusion is not one-size-fits-all: Cross-Modal Representation Alignment for Time-to-Event Modeling
Jun 13, 2026Accurate time-to-event (TTE) prediction from multimodal clinical data remains challenging due to modality imbalance and distribution shift. We introduce a foundation model-driven framework for cross-modal representation alignment between CT imaging and longitudinal EHR data, designed to generalize across tasks and institutions. CT and EHR modalities are encoded independently using domain-specific foundation models and aligned in a shared latent space through four principled fusion strategies: late fusion, contrastive alignment, cross-attention, and co-attention. We evaluate two clinically distinct TTE tasks: pulmonary embolism (PE) mortality and cardiovascular disease (CVD) outcomes, on large-scale multi-institutional cohorts (PE: N=3,099 train; 1,098 internal; 435 external; CVD: N=2,951 train; 837 internal; 682 external). Fusion consistently improves concordance index by 1.5-5.4% over unimodal baselines when modalities contribute comparably. Overall, contrastive multimodal fusion, particularly with CLMBR representations, provided the most consistent and statistically robust improvements, especially for PE mortality prediction. For MACE, cross-attention (one-hot) achieved the highest internal performance and image-guided co-attention achieved the best external performance. We therefore introduce a generalizable foundation model-based cross-modal alignment framework and provide the first systematic analysis of fusion behavior under modality imbalance in TTE prediction. Our results establish task-aware multimodal alignment as a necessary design principle for robust generalization and scalable clinical deployment.
Fed-FBD: Federated Functional Block Diversification for Isolation, Privacy, and Surgical Unlearning
Jun 10, 2026Federated learning (FL) enables collaborative model training without sharing raw patient data, but standard approaches such as FedAvg treat each client as a black box and provide no mechanism for isolating an adversarial contributor, auditing per-client influence, or honoring a departed participant's right to be forgotten. We present Fed-FBD (Federated Functional Block Diversification), a modular federated architecture that decomposes a ResNet backbone into six functional blocks (the stem, four residual groups, and the classification head) and maintains a warehouse of N color variants, each assembled from independently tracked and contributor-stamped blocks. Fed-FBD provides three capabilities absent in FedAvg: (i) architecturally guaranteed block-level isolation, so that an adversarial or mislabelled client cannot contaminate the clean colous; (ii) privacy-by-design, where membership inference advantage is already indistinguishable from chance before any privacy mechanism is applied; and (iii) surgical machine unlearning of a departed participant's contribution at sub-second cost and without retraining. Experiments on six MedMNIST-2D datasets, PathMNIST at 224x224, and CIFAR-10 show that Fed-FBD trades a modest 0.3%-3.1% IID accuracy gap on the adequately sized datasets for these guarantees, remains within 0.8%-4.0% of FedAvg at Dirichlet alpha=1.0 on three of four datasets, and confines all six adversarial attacks we study to the poisoned client's own blocks with at most +/-0.01 AUC drift on the clean colors.
DynSess: Dynamic Session-Level Evaluation and Optimization Framework for Role-Playing Agents
May 28, 2026Role-playing with large language models is fundamentally a session-level task, requiring agents to sustain character identity and interaction quality across extended multi-turn conversations. Yet existing evaluation and optimization methods remain largely turn-level, failing to capture long-horizon quality. We propose DynSess, a unified session-level framework for role-playing agents. DynSess-Eval scores complete dialogue sessions via rubrics targeting long-horizon behaviors. Leveraging its session-level rewards, we construct high-quality training trajectories through multi-turn lookahead search and train DynSess-Character with two complementary variants: DSPO (off-policy) and GSRPO (on-policy). Experiments show that DynSess-Eval aligns with human judgments substantially better than prior evaluators, and blind human evaluation further shows that DynSess-Character matches the strongest character model despite using substantially fewer parameters, while maintaining strong role consistency and interactive ability. Our dataset and code will be released to facilitate future research.
From Facts to Insights: A Persona-Driven Dual Memory Framework and Dataset for Role-Playing Agents
May 25, 2026While role-playing agents excel in short-term interactions, long-term conversations overwhelm context windows, motivating external memory frameworks. Current systems typically rely on persona-agnostic summarization, which records facts without persona-specific interpretation, yielding generic responses that compromise persona fidelity. To bridge this gap, we introduce RoleMemo, a dataset featuring four reasoning tasks where the factual fragments must be interpreted through the persona to reach the correct answer. Evaluation on RoleMemo exposes critical limitations of persona-agnostic frameworks. We thus propose DualMem, which decouples memory into two streams: factual cognition and persona-conditioned insight. Trained through Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL), our framework with a 4B-parameter model outperforms zero-shot persona-agnostic frameworks powered by DeepSeek-V3.2 for sustained persona fidelity. Our resources are available at https://github.com/role2026/rolememo.
HY-Motion 1.0: Scaling Flow Matching Models for Text-To-Motion Generation
Dec 29, 2025We present HY-Motion 1.0, a series of state-of-the-art, large-scale, motion generation models capable of generating 3D human motions from textual descriptions. HY-Motion 1.0 represents the first successful attempt to scale up Diffusion Transformer (DiT)-based flow matching models to the billion-parameter scale within the motion generation domain, delivering instruction-following capabilities that significantly outperform current open-source benchmarks. Uniquely, we introduce a comprehensive, full-stage training paradigm -- including large-scale pretraining on over 3,000 hours of motion data, high-quality fine-tuning on 400 hours of curated data, and reinforcement learning from both human feedback and reward models -- to ensure precise alignment with the text instruction and high motion quality. This framework is supported by our meticulous data processing pipeline, which performs rigorous motion cleaning and captioning. Consequently, our model achieves the most extensive coverage, spanning over 200 motion categories across 6 major classes. We release HY-Motion 1.0 to the open-source community to foster future research and accelerate the transition of 3D human motion generation models towards commercial maturity.
The Fourth Monocular Depth Estimation Challenge
Apr 24, 2025
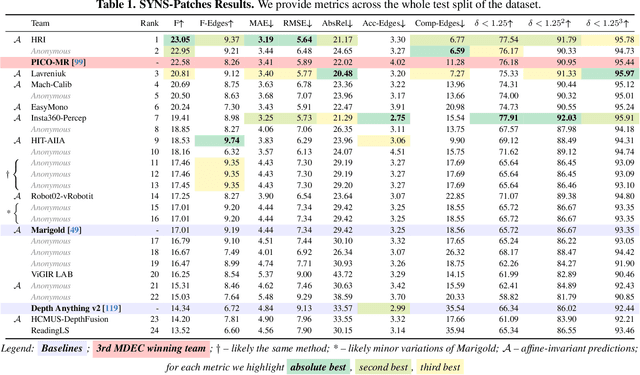
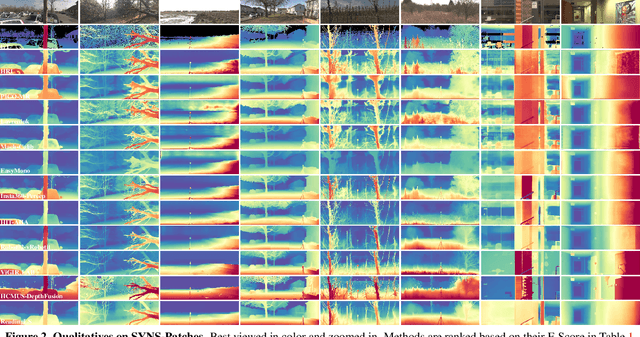
This paper presents the results of the fourth edition of the Monocular Depth Estimation Challenge (MDEC), which focuses on zero-shot generalization to the SYNS-Patches benchmark, a dataset featuring challenging environments in both natural and indoor settings. In this edition, we revised the evaluation protocol to use least-squares alignment with two degrees of freedom to support disparity and affine-invariant predictions. We also revised the baselines and included popular off-the-shelf methods: Depth Anything v2 and Marigold. The challenge received a total of 24 submissions that outperformed the baselines on the test set; 10 of these included a report describing their approach, with most leading methods relying on affine-invariant predictions. The challenge winners improved the 3D F-Score over the previous edition's best result, raising it from 22.58% to 23.05%.
Synthetic CT Generation from Time-of-Flight Non-Attenutaion-Corrected PET for Whole-Body PET Attenuation Correction
Apr 10, 2025Positron Emission Tomography (PET) imaging requires accurate attenuation correction (AC) to account for photon loss due to tissue density variations. In PET/MR systems, computed tomography (CT), which offers a straightforward estimation of AC is not available. This study presents a deep learning approach to generate synthetic CT (sCT) images directly from Time-of-Flight (TOF) non-attenuation corrected (NAC) PET images, enhancing AC for PET/MR. We first evaluated models pre-trained on large-scale natural image datasets for a CT-to-CT reconstruction task, finding that the pre-trained model outperformed those trained solely on medical datasets. The pre-trained model was then fine-tuned using an institutional dataset of 35 TOF NAC PET and CT volume pairs, achieving the lowest mean absolute error (MAE) of 74.49 HU and highest peak signal-to-noise ratio (PSNR) of 28.66 dB within the body contour region. Visual assessments demonstrated improved reconstruction of both bone and soft tissue structures from TOF NAC PET images. This work highlights the effectiveness of using pre-trained deep learning models for medical image translation tasks. Future work will assess the impact of sCT on PET attenuation correction and explore additional neural network architectures and datasets to further enhance performance and practical applications in PET imaging.
EasyCraft: A Robust and Efficient Framework for Automatic Avatar Crafting
Mar 03, 2025Character customization, or 'face crafting,' is a vital feature in role-playing games (RPGs), enhancing player engagement by enabling the creation of personalized avatars. Existing automated methods often struggle with generalizability across diverse game engines due to their reliance on the intermediate constraints of specific image domain and typically support only one type of input, either text or image. To overcome these challenges, we introduce EasyCraft, an innovative end-to-end feedforward framework that automates character crafting by uniquely supporting both text and image inputs. Our approach employs a translator capable of converting facial images of any style into crafting parameters. We first establish a unified feature distribution in the translator's image encoder through self-supervised learning on a large-scale dataset, enabling photos of any style to be embedded into a unified feature representation. Subsequently, we map this unified feature distribution to crafting parameters specific to a game engine, a process that can be easily adapted to most game engines and thus enhances EasyCraft's generalizability. By integrating text-to-image techniques with our translator, EasyCraft also facilitates precise, text-based character crafting. EasyCraft's ability to integrate diverse inputs significantly enhances the versatility and accuracy of avatar creation. Extensive experiments on two RPG games demonstrate the effectiveness of our method, achieving state-of-the-art results and facilitating adaptability across various avatar engines.
Unbiased Evaluation of Large Language Models from a Causal Perspective
Feb 10, 2025



Benchmark contamination has become a significant concern in the LLM evaluation community. Previous Agents-as-an-Evaluator address this issue by involving agents in the generation of questions. Despite their success, the biases in Agents-as-an-Evaluator methods remain largely unexplored. In this paper, we present a theoretical formulation of evaluation bias, providing valuable insights into designing unbiased evaluation protocols. Furthermore, we identify two type of bias in Agents-as-an-Evaluator through carefully designed probing tasks on a minimal Agents-as-an-Evaluator setup. To address these issues, we propose the Unbiased Evaluator, an evaluation protocol that delivers a more comprehensive, unbiased, and interpretable assessment of LLMs.Extensive experiments reveal significant room for improvement in current LLMs. Additionally, we demonstrate that the Unbiased Evaluator not only offers strong evidence of benchmark contamination but also provides interpretable evaluation results.
Invariant debiasing learning for recommendation via biased imputation
Dec 28, 2024



Previous debiasing studies utilize unbiased data to make supervision of model training. They suffer from the high trial risks and experimental costs to obtain unbiased data. Recent research attempts to use invariant learning to detach the invariant preference of users for unbiased recommendations in an unsupervised way. However, it faces the drawbacks of low model accuracy and unstable prediction performance due to the losing cooperation with variant preference. In this paper, we experimentally demonstrate that invariant learning causes information loss by directly discarding the variant information, which reduces the generalization ability and results in the degradation of model performance in unbiased recommendations. Based on this consideration, we propose a novel lightweight knowledge distillation framework (KDDebias) to automatically learn the unbiased preference of users from both invariant and variant information. Specifically, the variant information is imputed to the invariant user preference in the distance-aware knowledge distillation process. Extensive experiments on three public datasets, i.e., Yahoo!R3, Coat, and MIND, show that with the biased imputation from the variant preference of users, our proposed method achieves significant improvements with less than 50% learning parameters compared to the SOTA unsupervised debiasing model in recommender systems. Our code are publicly available at https://github.com/BAI-LAB/KD-Debias.