 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTEDiff: Strengthening Text Embedding for Text-to-Image Alignment in Diffusion Model
Jun 09, 2026Although pretrained text-to-image (T2I) generation models can produce high-quality images, they often fail to faithfully reflect the semantic intent of complex prompts due to stochastic noise and inherent model limitations. This issue frequently manifests as the model overlooking specific objects or failing to correctly bind attributes to their corresponding entities, a challenge referred to as semantic alignment. Unlike existing approaches that rely on computationally expensive fine-tuning or labor-intensive layout priors, we propose STEDiff, a training-free method designed to enhance semantic representations directly within the text-embedding space. Specifically, we introduce a method that primarily leverages the [EOT] token to strengthen the relevant semantics of sub-sentences and then replaces the corresponding tokens in the original prompt. Furthermore, a novel semantic enhancement loss is incorporated to enforce spatial constraints, ensuring that the semantics of each entity are precisely mapped to their respective image regions. Extensive quantitative and qualitative evaluations on the T2I-CompBench demonstrate that our method notably improves semantic consistency and generation integrity in complex scenarios.
MiRD: Reliable Set-Valued Prediction for Open-Ended Question Answering via Miscoverage Risk Decomposition
May 25, 2026Reliable set-valued prediction provides a principled way to mitigate hallucinations in open-ended question answering (QA), yet existing conformal approaches typically rely on a fragile premise: finite sampling must already produce at least one admissible candidate, or calibration examples violating this condition are discarded. In this paper, we introduce MiRD, a two-stage framework that decomposes overall miscoverage into sampling failure and conditional selection failure. In Stage I, MiRD establishes an expectation-level marginal upper bound on the probability that finite sampling produces no admissible answer under a fixed budget. In Stage II, conditioned on sampling success, MiRD calibrates a conformal selection threshold using admission-correlated nonconformity scores defined over the full calibration set, thereby preserving calibration-set integrity. Across three open-ended QA datasets and eight models, MiRD controls sampling risk, conditional selection risk, and overall miscoverage, while yielding tighter first-stage bounds than PAC-style alternatives and more adaptive prediction sets than successful-only calibration.
Set-Valued Prediction for Large Language Models with Feasibility-Aware Coverage Guarantees
Mar 24, 2026Large language models (LLMs) inherently operate over a large generation space, yet conventional usage typically reports the most likely generation (MLG) as a point prediction, which underestimates the model's capability: although the top-ranked response can be incorrect, valid answers may still exist within the broader output space and can potentially be discovered through repeated sampling. This observation motivates moving from point prediction to set-valued prediction, where the model produces a set of candidate responses rather than a single MLG. In this paper, we propose a principled framework for set-valued prediction, which provides feasibility-aware coverage guarantees. We show that, given the finite-sampling nature of LLM generation, coverage is not always achievable: even with multiple samplings, LLMs may fail to yield an acceptable response for certain questions within the sampled candidate set. To address this, we establish a minimum achievable risk level (MRL), below which statistical coverage guarantees cannot be satisfied. Building on this insight, we then develop a data-driven calibration procedure that constructs prediction sets from sampled responses by estimating a rigorous threshold, ensuring that the resulting set contains a correct answer with a desired probability whenever the target risk level is feasible. Extensive experiments on six language generation tasks with five LLMs demonstrate both the statistical validity and the predictive efficiency of our framework.
Large Foundation Model for Ads Recommendation
Aug 20, 2025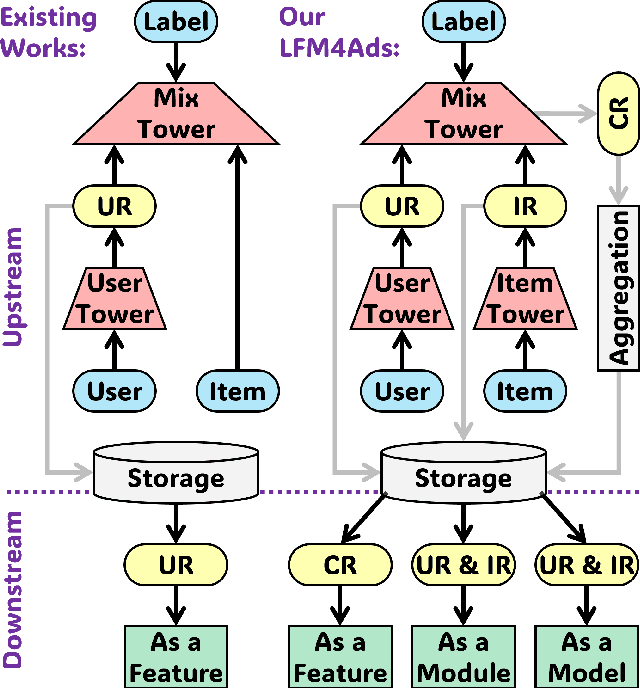
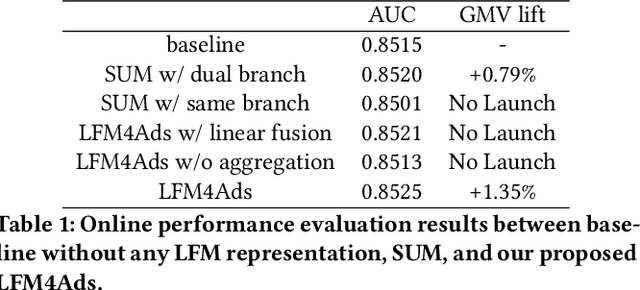
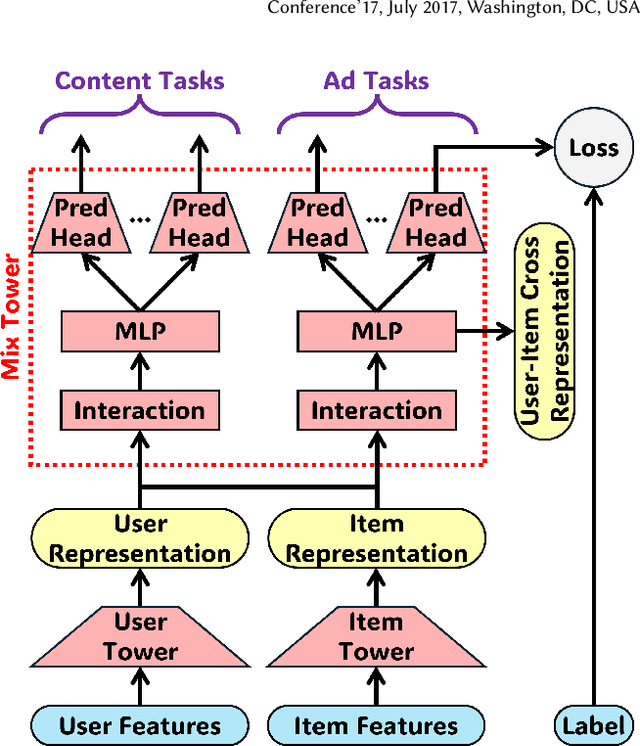
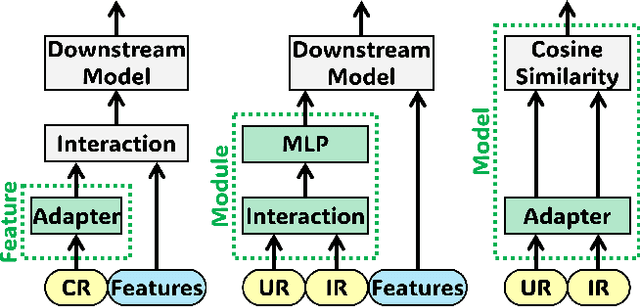
Online advertising relies on accurate recommendation models, with recent advances using pre-trained large-scale foundation models (LFMs) to capture users' general interests across multiple scenarios and tasks. However, existing methods have critical limitations: they extract and transfer only user representations (URs), ignoring valuable item representations (IRs) and user-item cross representations (CRs); and they simply use a UR as a feature in downstream applications, which fails to bridge upstream-downstream gaps and overlooks more transfer granularities. In this paper, we propose LFM4Ads, an All-Representation Multi-Granularity transfer framework for ads recommendation. It first comprehensively transfers URs, IRs, and CRs, i.e., all available representations in the pre-trained foundation model. To effectively utilize the CRs, it identifies the optimal extraction layer and aggregates them into transferable coarse-grained forms. Furthermore, we enhance the transferability via multi-granularity mechanisms: non-linear adapters for feature-level transfer, an Isomorphic Interaction Module for module-level transfer, and Standalone Retrieval for model-level transfer. LFM4Ads has been successfully deployed in Tencent's industrial-scale advertising platform, processing tens of billions of daily samples while maintaining terabyte-scale model parameters with billions of sparse embedding keys across approximately two thousand features. Since its production deployment in Q4 2024, LFM4Ads has achieved 10+ successful production launches across various advertising scenarios, including primary ones like Weixin Moments and Channels. These launches achieve an overall GMV lift of 2.45% across the entire platform, translating to estimated annual revenue increases in the hundreds of millions of dollars.
MDE-Edit: Masked Dual-Editing for Multi-Object Image Editing via Diffusion Models
May 08, 2025Multi-object editing aims to modify multiple objects or regions in complex scenes while preserving structural coherence. This task faces significant challenges in scenarios involving overlapping or interacting objects: (1) Inaccurate localization of target objects due to attention misalignment, leading to incomplete or misplaced edits; (2) Attribute-object mismatch, where color or texture changes fail to align with intended regions due to cross-attention leakage, creating semantic conflicts (\textit{e.g.}, color bleeding into non-target areas). Existing methods struggle with these challenges: approaches relying on global cross-attention mechanisms suffer from attention dilution and spatial interference between objects, while mask-based methods fail to bind attributes to geometrically accurate regions due to feature entanglement in multi-object scenarios. To address these limitations, we propose a training-free, inference-stage optimization approach that enables precise localized image manipulation in complex multi-object scenes, named MDE-Edit. MDE-Edit optimizes the noise latent feature in diffusion models via two key losses: Object Alignment Loss (OAL) aligns multi-layer cross-attention with segmentation masks for precise object positioning, and Color Consistency Loss (CCL) amplifies target attribute attention within masks while suppressing leakage to adjacent regions. This dual-loss design ensures localized and coherent multi-object edits. Extensive experiments demonstrate that MDE-Edit outperforms state-of-the-art methods in editing accuracy and visual quality, offering a robust solution for complex multi-object image manipulation tasks.
Robust Misinformation Detection by Visiting Potential Commonsense Conflict
Apr 30, 2025



The development of Internet technology has led to an increased prevalence of misinformation, causing severe negative effects across diverse domains. To mitigate this challenge, Misinformation Detection (MD), aiming to detect online misinformation automatically, emerges as a rapidly growing research topic in the community. In this paper, we propose a novel plug-and-play augmentation method for the MD task, namely Misinformation Detection with Potential Commonsense Conflict (MD-PCC). We take inspiration from the prior studies indicating that fake articles are more likely to involve commonsense conflict. Accordingly, we construct commonsense expressions for articles, serving to express potential commonsense conflicts inferred by the difference between extracted commonsense triplet and golden ones inferred by the well-established commonsense reasoning tool COMET. These expressions are then specified for each article as augmentation. Any specific MD methods can be then trained on those commonsense-augmented articles. Besides, we also collect a novel commonsense-oriented dataset named CoMis, whose all fake articles are caused by commonsense conflict. We integrate MD-PCC with various existing MD backbones and compare them across both 4 public benchmark datasets and CoMis. Empirical results demonstrate that MD-PCC can consistently outperform the existing MD baselines.
CeViT: Copula-Enhanced Vision Transformer in multi-task learning and bi-group image covariates with an application to myopia screening
Jan 11, 2025



We aim to assist image-based myopia screening by resolving two longstanding problems, "how to integrate the information of ocular images of a pair of eyes" and "how to incorporate the inherent dependence among high-myopia status and axial length for both eyes." The classification-regression task is modeled as a novel 4-dimensional muti-response regression, where discrete responses are allowed, that relates to two dependent 3rd-order tensors (3D ultrawide-field fundus images). We present a Vision Transformer-based bi-channel architecture, named CeViT, where the common features of a pair of eyes are extracted via a shared Transformer encoder, and the interocular asymmetries are modeled through separated multilayer perceptron heads. Statistically, we model the conditional dependence among mixture of discrete-continuous responses given the image covariates by a so-called copula loss. We establish a new theoretical framework regarding fine-tuning on CeViT based on latent representations, allowing the black-box fine-tuning procedure interpretable and guaranteeing higher relative efficiency of fine-tuning weight estimation in the asymptotic setting. We apply CeViT to an annotated ultrawide-field fundus image dataset collected by Shanghai Eye \& ENT Hospital, demonstrating that CeViT enhances the baseline model in both accuracy of classifying high-myopia and prediction of AL on both eyes.
AdaptLIL: A Gaze-Adaptive Visualization for Ontology Mapping
Nov 18, 2024This paper showcases AdaptLIL, a real-time adaptive link-indented list ontology mapping visualization that uses eye gaze as the primary input source. Through a multimodal combination of real-time systems, deep learning, and web development applications, this system uniquely curtails graphical overlays (adaptations) to pairwise mappings of link-indented list ontology visualizations for individual users based solely on their eye gaze.
Wavelet-based Mamba with Fourier Adjustment for Low-light Image Enhancement
Oct 27, 2024



Frequency information (e.g., Discrete Wavelet Transform and Fast Fourier Transform) has been widely applied to solve the issue of Low-Light Image Enhancement (LLIE). However, existing frequency-based models primarily operate in the simple wavelet or Fourier space of images, which lacks utilization of valid global and local information in each space. We found that wavelet frequency information is more sensitive to global brightness due to its low-frequency component while Fourier frequency information is more sensitive to local details due to its phase component. In order to achieve superior preliminary brightness enhancement by optimally integrating spatial channel information with low-frequency components in the wavelet transform, we introduce channel-wise Mamba, which compensates for the long-range dependencies of CNNs and has lower complexity compared to Diffusion and Transformer models. So in this work, we propose a novel Wavelet-based Mamba with Fourier Adjustment model called WalMaFa, consisting of a Wavelet-based Mamba Block (WMB) and a Fast Fourier Adjustment Block (FFAB). We employ an Encoder-Latent-Decoder structure to accomplish the end-to-end transformation. Specifically, WMB is adopted in the Encoder and Decoder to enhance global brightness while FFAB is adopted in the Latent to fine-tune local texture details and alleviate ambiguity. Extensive experiments demonstrate that our proposed WalMaFa achieves state-of-the-art performance with fewer computational resources and faster speed. Code is now available at: https://github.com/mcpaulgeorge/WalMaFa.
Sample then Identify: A General Framework for Risk Control and Assessment in Multimodal Large Language Models
Oct 10, 2024



Multimodal Large Language Models (MLLMs) exhibit promising advancements across various tasks, yet they still encounter significant trustworthiness issues. Prior studies apply Split Conformal Prediction (SCP) in language modeling to construct prediction sets with statistical guarantees. However, these methods typically rely on internal model logits or are restricted to multiple-choice settings, which hampers their generalizability and adaptability in dynamic, open-ended environments. In this paper, we introduce TRON, a two-step framework for risk control and assessment, applicable to any MLLM that supports sampling in both open-ended and closed-ended scenarios. TRON comprises two main components: (1) a novel conformal score to sample response sets of minimum size, and (2) a nonconformity score to identify high-quality responses based on self-consistency theory, controlling the error rates by two specific risk levels. Furthermore, we investigate semantic redundancy in prediction sets within open-ended contexts for the first time, leading to a promising evaluation metric for MLLMs based on average set size. Our comprehensive experiments across four Video Question-Answering (VideoQA) datasets utilizing eight MLLMs show that TRON achieves desired error rates bounded by two user-specified risk levels. Additionally, deduplicated prediction sets maintain adaptiveness while being more efficient and stable for risk assessment under different risk levels.