 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Value Alignment for Generative Recommendation in Industrial Advertising
May 07, 2026Generative Recommendation (GR) reformulates recommendation as a next-token generation problem and has shown promise in industrial applications. However, extending GR to industrial advertising is non-trivial because the system must optimize not only user interest but also commercial value. Existing GR pipelines remain largely semantics-centric, making it difficult to align value signals across tokenization, decoding, and online serving. To address this issue, we propose UniVA, a Unified Value Alignment framework for advertising recommendation. We first introduce a Commercial SID tokenizer that injects value-related attributes into SID construction, yielding value-discriminative item representations. We then develop a Generation-as-Ranking SID Decoder jointly optimized by supervised learning and eCPM-aware reinforcement learning, which fuses value scores into next-item SID generation to perform generation and ranking in one decoding process. Finally, we design a value-guided personalized beam search that reuses generation-as-ranking logits as online value guidance and applies a personalized trie tree to constrain decoding to request-valid SID paths. Experiments on the Tencent WeChat Channels advertising platform show that UniVA achieves a 37.04\% improvement in offline Hit Rate@100 over the baseline and a 1.5\% GMV lift in online A/B tests.
Spend Search Where It Pays: Value-Guided Structured Sampling and Optimization for Generative Recommendation
Feb 12, 2026Generative recommendation via autoregressive models has unified retrieval and ranking into a single conditional generation framework. However, fine-tuning these models with Reinforcement Learning (RL) often suffers from a fundamental probability-reward mismatch. Conventional likelihood-dominated decoding (e.g., beam search) exhibits a myopic bias toward locally probable prefixes, which causes two critical failures: (1) insufficient exploration, where high-reward items in low-probability branches are prematurely pruned and rarely sampled, and (2) advantage compression, where trajectories sharing high-probability prefixes receive highly correlated rewards with low within-group variance, yielding a weak comparative signal for RL. To address these challenges, we propose V-STAR, a Value-guided Sampling and Tree-structured Advantage Reinforcement framework. V-STAR forms a self-evolving loop via two synergistic components. First, a Value-Guided Efficient Decoding (VED) is developed to identify decisive nodes and selectively deepen high-potential prefixes. This improves exploration efficiency without exhaustive tree search. Second, we propose Sibling-GRPO, which exploits the induced tree topology to compute sibling-relative advantages and concentrates learning signals on decisive branching decisions. Extensive experiments on both offline and online datasets demonstrate that V-STAR outperforms state-of-the-art baselines, delivering superior accuracy and candidate-set diversity under strict latency constraints.
S-GRec: Personalized Semantic-Aware Generative Recommendation with Asymmetric Advantage
Feb 12, 2026Generative recommendation models sequence generation to produce items end-to-end, but training from behavioral logs often provides weak supervision on underlying user intent. Although Large Language Models (LLMs) offer rich semantic priors that could supply such supervision, direct adoption in industrial recommendation is hindered by two obstacles: semantic signals can conflict with platform business objectives, and LLM inference is prohibitively expensive at scale. This paper presents S-GRec, a semantic-aware framework that decouples an online lightweight generator from an offline LLM-based semantic judge for train-time supervision. S-GRec introduces a two-stage Personalized Semantic Judge (PSJ) that produces interpretable aspect evidence and learns user-conditional aggregation from pairwise feedback, yielding stable semantic rewards. To prevent semantic supervision from deviating from business goals, Asymmetric Advantage Policy Optimization (A2PO) anchors optimization on business rewards (e.g., eCPM) and injects semantic advantages only when they are consistent. Extensive experiments on public benchmarks and a large-scale production system validate both effectiveness and scalability, including statistically significant gains in CTR and a 1.19\% lift in GMV in online A/B tests, without requiring real-time LLM inference.
Breaking the Curse of Repulsion: Optimistic Distributionally Robust Policy Optimization for Off-Policy Generative Recommendation
Feb 11, 2026Policy-based Reinforcement Learning (RL) has established itself as the dominant paradigm in generative recommendation for optimizing sequential user interactions. However, when applied to offline historical logs, these methods suffer a critical failure: the dominance of low-quality data induces severe model collapse. We first establish the Divergence Theory of Repulsive Optimization, revealing that negative gradient updates inherently trigger exponential intensity explosion during off-policy training. This theory elucidates the inherent dilemma of existing methods, exposing their inability to reconcile variance reduction and noise imitation. To break this curse, we argue that the solution lies in rigorously identifying the latent high-quality distribution entangled within the noisy behavior policy. Accordingly, we reformulate the objective as an Optimistic Distributionally Robust Optimization (DRO) problem. Guided by this formulation, we propose Distributionally Robust Policy Optimization (DRPO). We prove that hard filtering is the exact solution to this DRO objective, enabling DRPO to optimally recover high-quality behaviors while strictly discarding divergence-inducing noise. Extensive experiments demonstrate that DRPO achieves state-of-the-art performance on mixed-quality recommendation benchmarks.
GPR: Towards a Generative Pre-trained One-Model Paradigm for Large-Scale Advertising Recommendation
Nov 13, 2025



As an intelligent infrastructure connecting users with commercial content, advertising recommendation systems play a central role in information flow and value creation within the digital economy. However, existing multi-stage advertising recommendation systems suffer from objective misalignment and error propagation, making it difficult to achieve global optimality, while unified generative recommendation models still struggle to meet the demands of practical industrial applications. To address these issues, we propose GPR (Generative Pre-trained Recommender), the first one-model framework that redefines advertising recommendation as an end-to-end generative task, replacing the traditional cascading paradigm with a unified generative approach. To realize GPR, we introduce three key innovations spanning unified representation, network architecture, and training strategy. First, we design a unified input schema and tokenization method tailored to advertising scenarios, mapping both ads and organic content into a shared multi-level semantic ID space, thereby enhancing semantic alignment and modeling consistency across heterogeneous data. Second, we develop the Heterogeneous Hierarchical Decoder (HHD), a dual-decoder architecture that decouples user intent modeling from ad generation, achieving a balance between training efficiency and inference flexibility while maintaining strong modeling capacity. Finally, we propose a multi-stage joint training strategy that integrates Multi-Token Prediction (MTP), Value-Aware Fine-Tuning and the Hierarchy Enhanced Policy Optimization (HEPO) algorithm, forming a complete generative recommendation pipeline that unifies interest modeling, value alignment, and policy optimization. GPR has been fully deployed in the Tencent Weixin Channels advertising system, delivering significant improvements in key business metrics including GMV and CTCVR.
HybridGNN: Learning Hybrid Representation in Multiplex Heterogeneous Networks
Aug 03, 2022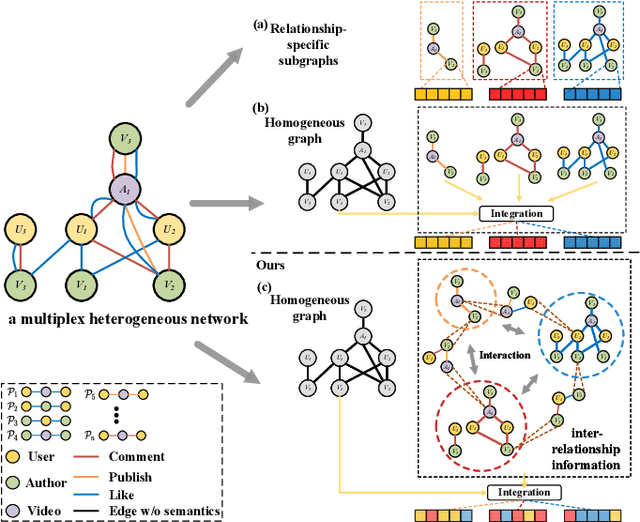
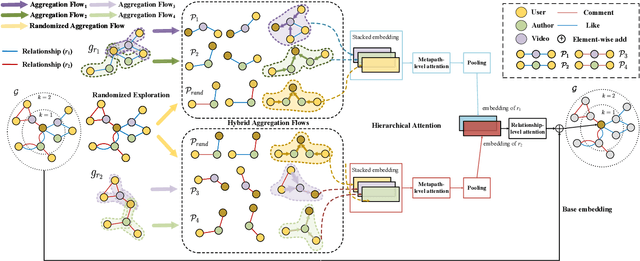
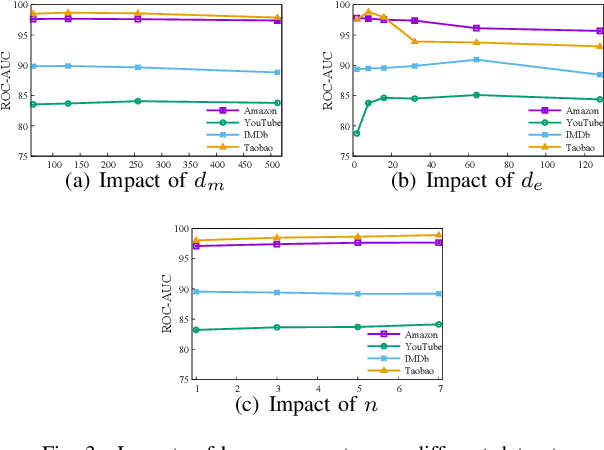
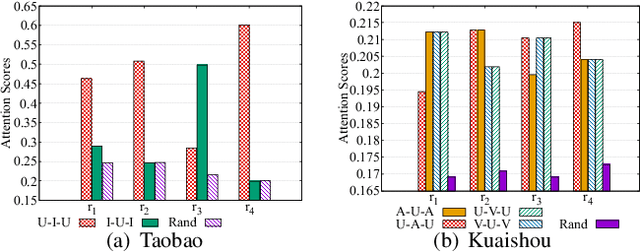
Recently, graph neural networks have shown the superiority of modeling the complex topological structures in heterogeneous network-based recommender systems. Due to the diverse interactions among nodes and abundant semantics emerging from diverse types of nodes and edges, there is a bursting research interest in learning expressive node representations in multiplex heterogeneous networks. One of the most important tasks in recommender systems is to predict the potential connection between two nodes under a specific edge type (i.e., relationship). Although existing studies utilize explicit metapaths to aggregate neighbors, practically they only consider intra-relationship metapaths and thus fail to leverage the potential uplift by inter-relationship information. Moreover, it is not always straightforward to exploit inter-relationship metapaths comprehensively under diverse relationships, especially with the increasing number of node and edge types. In addition, contributions of different relationships between two nodes are difficult to measure. To address the challenges, we propose HybridGNN, an end-to-end GNN model with hybrid aggregation flows and hierarchical attentions to fully utilize the heterogeneity in the multiplex scenarios. Specifically, HybridGNN applies a randomized inter-relationship exploration module to exploit the multiplexity property among different relationships. Then, our model leverages hybrid aggregation flows under intra-relationship metapaths and randomized exploration to learn the rich semantics. To explore the importance of different aggregation flow and take advantage of the multiplexity property, we bring forward a novel hierarchical attention module which leverages both metapath-level attention and relationship-level attention. Extensive experimental results suggest that HybridGNN achieves the best performance compared to several state-of-the-art baselines.
Concept-Aware Denoising Graph Neural Network for Micro-Video Recommendation
Sep 28, 2021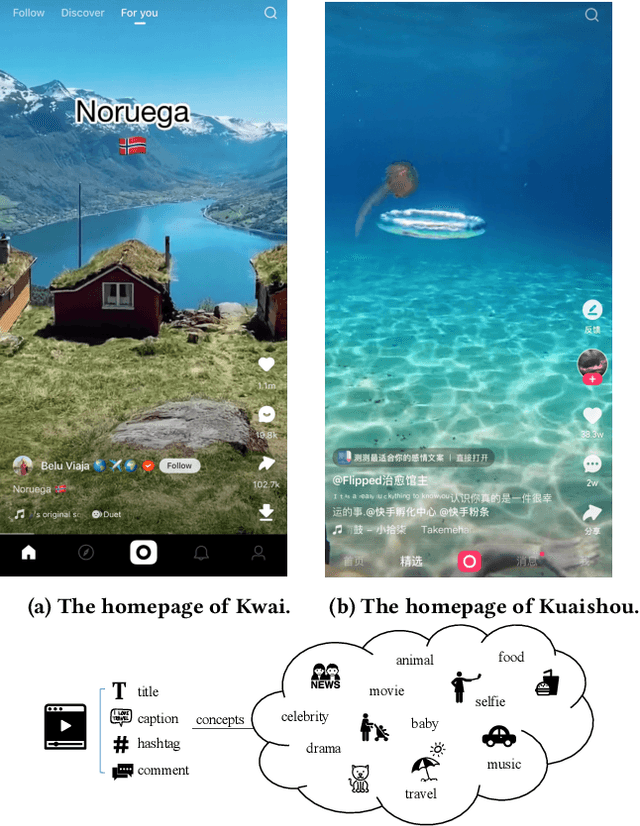

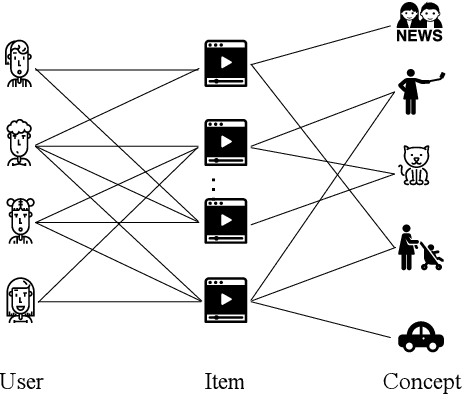
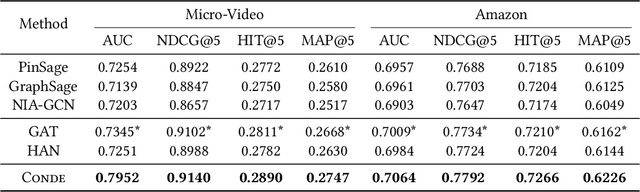
Recently, micro-video sharing platforms such as Kuaishou and Tiktok have become a major source of information for people's lives. Thanks to the large traffic volume, short video lifespan and streaming fashion of these services, it has become more and more pressing to improve the existing recommender systems to accommodate these challenges in a cost-effective way. In this paper, we propose a novel concept-aware denoising graph neural network (named CONDE) for micro-video recommendation. CONDE consists of a three-phase graph convolution process to derive user and micro-video representations: warm-up propagation, graph denoising and preference refinement. A heterogeneous tripartite graph is constructed by connecting user nodes with video nodes, and video nodes with associated concept nodes, extracted from captions and comments of the videos. To address the noisy information in the graph, we introduce a user-oriented graph denoising phase to extract a subgraph which can better reflect the user's preference. Despite the main focus of micro-video recommendation in this paper, we also show that our method can be generalized to other types of tasks. Therefore, we also conduct empirical studies on a well-known public E-commerce dataset. The experimental results suggest that the proposed CONDE achieves significantly better recommendation performance than the existing state-of-the-art solutions.
Expanding Semantic Knowledge for Zero-shot Graph Embedding
Mar 23, 2021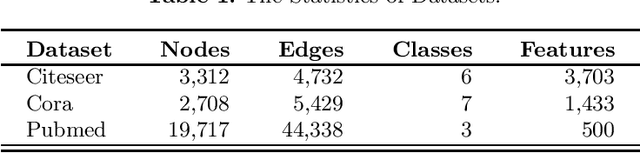
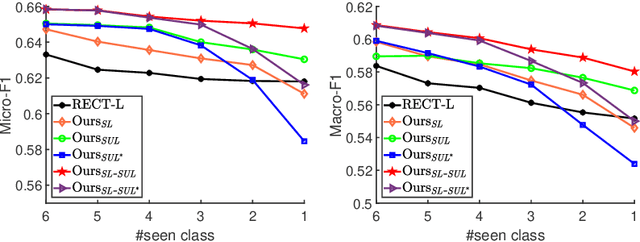
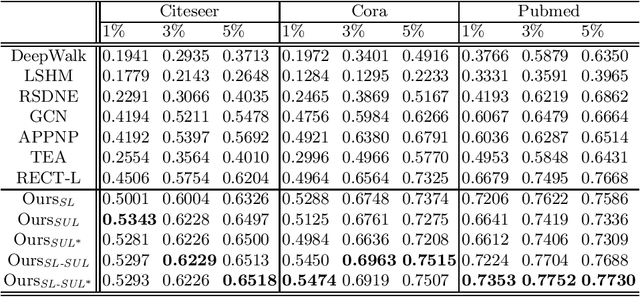
Zero-shot graph embedding is a major challenge for supervised graph learning. Although a recent method RECT has shown promising performance, its working mechanisms are not clear and still needs lots of training data. In this paper, we give deep insights into RECT, and address its fundamental limits. We show that its core part is a GNN prototypical model in which a class prototype is described by its mean feature vector. As such, RECT maps nodes from the raw-input feature space into an intermediate-level semantic space that connects the raw-input features to both seen and unseen classes. This mechanism makes RECT work well on both seen and unseen classes, which however also reduces the discrimination. To realize its full potentials, we propose two label expansion strategies. Specifically, besides expanding the labeled node set of seen classes, we can also expand that of unseen classes. Experiments on real-world datasets validate the superiority of our methods.